YOLOv5 Jetson部署 TensorRT
用TensorRT部署YOLOv5,用的最多的方式就是通过:
https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
步骤和教程都已经很详细了,我只是记录一下遇到的问题。
我的环境:
Jetson Xavier NX
Jetpack 4.5
aarch64 Ubuntu18.04
python 3.6.9
cuda 10.2
cudnn 8.0
tensorrt 7.1.3.0
opencv-python 4.5.5.64
torch 1.8.0
torchvision 0.9.0
在make的时候出现如下报错:
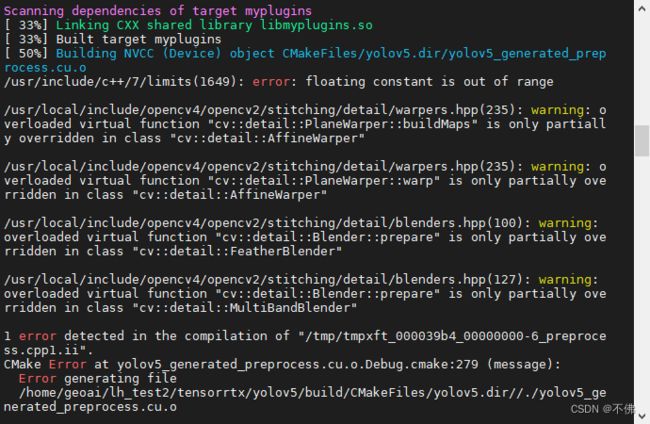
查了半天没找到原因,后来突然想起一篇部署文章中说好多错误是忘记加sudo导致的,我试了一下,真是这个原因……
在生成engine的时候出现如下报错:
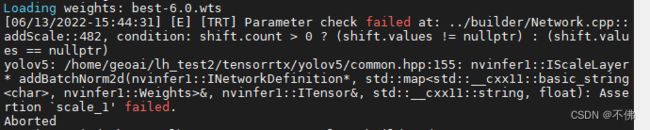
如果yololayer.h中CLASS_NUM改过了, 那就是模型不对。因为我很早就开始使用YOLOv5,模型版本有点乱,下载对应版本的模型就好了。

生成engine之后,就可以用Python脚本yolov5_trt.py推理图片了。
这个脚本是推理一个文件夹中的所有图片,是个入门级的demo,对我使用来说有以下问题:
- 无法推理视频。
- 每张图的框颜色是随机的,没有根据类别固定,且不支持中文标签。
- BATCH_SIZE>1的时候,比如BATCH_SIZE=2,那么测试的图片数必须是2的倍数,否则会报错。
- 没明白为啥要不断创建新线程,我用不到多线程,去掉线程之后速度会更快。
我的需求是要能实时推理视频,以实现算法功能,所以画框和保存图片在实际使用中没有必要,反而拖慢速度。
我根据自己的需求改写了代码,用来推理视频或视频流。代码如下,有需要的同学自取:
"""
An example that uses TensorRT's Python api to make inferences.
"""
import ctypes
import os
import shutil
import random
import sys
import time
import cv2
import numpy as np
import pycuda.autoinit
import pycuda.driver as cuda
import tensorrt as trt
import torch
CONF_THRESH = 0.5
IOU_THRESHOLD = 0.4
class YoLov5TRT(object):
"""
description: A YOLOv5 class that warps TensorRT ops, preprocess and postprocess ops.
"""
def __init__(self, engine_file_path):
# Create a Context on this device,
self.ctx = cuda.Device(0).make_context()
stream = cuda.Stream()
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
runtime = trt.Runtime(TRT_LOGGER)
# Deserialize the engine from file
with open(engine_file_path, "rb") as f:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
host_inputs = []
cuda_inputs = []
host_outputs = []
cuda_outputs = []
bindings = []
for binding in engine:
print('bingding:', binding, engine.get_binding_shape(binding))
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(cuda_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
self.input_w = engine.get_binding_shape(binding)[-1]
self.input_h = engine.get_binding_shape(binding)[-2]
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
# Store
self.stream = stream
self.context = context
self.engine = engine
self.host_inputs = host_inputs
self.cuda_inputs = cuda_inputs
self.host_outputs = host_outputs
self.cuda_outputs = cuda_outputs
self.bindings = bindings
self.batch_size = engine.max_batch_size
def infer(self, raw_image_generator):
# Make self the active context, pushing it on top of the context stack.
self.ctx.push()
# Restore
stream = self.stream
context = self.context
engine = self.engine
host_inputs = self.host_inputs
cuda_inputs = self.cuda_inputs
host_outputs = self.host_outputs
cuda_outputs = self.cuda_outputs
bindings = self.bindings
# Do image preprocess
batch_image_raw = []
batch_origin_h = []
batch_origin_w = []
batch_input_image = np.empty(shape=[self.batch_size, 3, self.input_h, self.input_w])
for i, image_raw in enumerate(raw_image_generator):
input_image, image_raw, origin_h, origin_w = self.preprocess_image(image_raw)
batch_image_raw.append(image_raw)
batch_origin_h.append(origin_h)
batch_origin_w.append(origin_w)
np.copyto(batch_input_image[i], input_image)
batch_input_image = np.ascontiguousarray(batch_input_image)
# Copy input image to host buffer
np.copyto(host_inputs[0], batch_input_image.ravel())
start = time.time()
# Transfer input data to the GPU.
cuda.memcpy_htod_async(cuda_inputs[0], host_inputs[0], stream)
# Run inference.
context.execute_async(batch_size=self.batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(host_outputs[0], cuda_outputs[0], stream)
# Synchronize the stream
stream.synchronize()
end = time.time()
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
# Here we use the first row of output in that batch_size = 1
output = host_outputs[0]
result_boxes, result_scores, result_classid = None, None, None
# Do postprocess
for i in range(self.batch_size):
result_boxes, result_scores, result_classid = self.post_process(
output[i * 6001: (i + 1) * 6001], batch_origin_h[i], batch_origin_w[i]
)
return result_boxes, result_scores, result_classid, end - start
def destroy(self):
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
def get_raw_image_zeros(self):
"""
description: Ready data for warmup
"""
for _ in range(self.batch_size):
yield np.zeros([self.input_h, self.input_w, 3], dtype=np.uint8)
def preprocess_image(self, raw_bgr_image):
"""
description: Convert BGR image to RGB,
resize and pad it to target size, normalize to [0,1],
transform to NCHW format.
param:
input_image_path: str, image path
return:
image: the processed image
image_raw: the original image
h: original height
w: original width
"""
image_raw = raw_bgr_image
h, w, c = image_raw.shape
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
# Calculate widht and height and paddings
r_w = self.input_w / w
r_h = self.input_h / h
if r_h > r_w:
tw = self.input_w
th = int(r_w * h)
tx1 = tx2 = 0
ty1 = int((self.input_h - th) / 2)
ty2 = self.input_h - th - ty1
else:
tw = int(r_h * w)
th = self.input_h
tx1 = int((self.input_w - tw) / 2)
tx2 = self.input_w - tw - tx1
ty1 = ty2 = 0
# Resize the image with long side while maintaining ratio
image = cv2.resize(image, (tw, th))
# Pad the short side with (128,128,128)
image = cv2.copyMakeBorder(
image, ty1, ty2, tx1, tx2, cv2.BORDER_CONSTANT, None, (128, 128, 128)
)
image = image.astype(np.float32)
# Normalize to [0,1]
image /= 255.0
# HWC to CHW format:
image = np.transpose(image, [2, 0, 1])
# CHW to NCHW format
image = np.expand_dims(image, axis=0)
# Convert the image to row-major order, also known as "C order":
image = np.ascontiguousarray(image)
return image, image_raw, h, w
def xywh2xyxy(self, origin_h, origin_w, x):
"""
description: Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
param:
origin_h: height of original image
origin_w: width of original image
x: A boxes numpy, each row is a box [center_x, center_y, w, h]
return:
y: A boxes numpy, each row is a box [x1, y1, x2, y2]
"""
y = np.zeros_like(x)
r_w = self.input_w / origin_w
r_h = self.input_h / origin_h
if r_h > r_w:
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y /= r_w
else:
y[:, 0] = x[:, 0] - x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
y /= r_h
return y
def post_process(self, output, origin_h, origin_w):
"""
description: postprocess the prediction
param:
output: A numpy likes [num_boxes,cx,cy,w,h,conf,cls_id, cx,cy,w,h,conf,cls_id, ...]
origin_h: height of original image
origin_w: width of original image
return:
result_boxes: finally boxes, a boxes numpy, each row is a box [x1, y1, x2, y2]
result_scores: finally scores, a numpy, each element is the score correspoing to box
result_classid: finally classid, a numpy, each element is the classid correspoing to box
"""
# Get the num of boxes detected
num = int(output[0])
# Reshape to a two dimentional ndarray
pred = np.reshape(output[1:], (-1, 6))[:num, :]
# Do nms
boxes = self.non_max_suppression(pred, origin_h, origin_w, conf_thres=CONF_THRESH, nms_thres=IOU_THRESHOLD)
result_boxes = boxes[:, :4] if len(boxes) else np.array([])
result_scores = boxes[:, 4] if len(boxes) else np.array([])
result_classid = boxes[:, 5] if len(boxes) else np.array([])
return result_boxes, result_scores, result_classid
def bbox_iou(self, box1, box2, x1y1x2y2=True):
"""
description: compute the IoU of two bounding boxes
param:
box1: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
box2: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
x1y1x2y2: select the coordinate format
return:
iou: computed iou
"""
if not x1y1x2y2:
# Transform from center and width to exact coordinates
b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
else:
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
# Get the coordinates of the intersection rectangle
inter_rect_x1 = np.maximum(b1_x1, b2_x1)
inter_rect_y1 = np.maximum(b1_y1, b2_y1)
inter_rect_x2 = np.minimum(b1_x2, b2_x2)
inter_rect_y2 = np.minimum(b1_y2, b2_y2)
# Intersection area
inter_area = np.clip(inter_rect_x2 - inter_rect_x1 + 1, 0, None) * \
np.clip(inter_rect_y2 - inter_rect_y1 + 1, 0, None)
# Union Area
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
iou = inter_area / (b1_area + b2_area - inter_area + 1e-16)
return iou
def non_max_suppression(self, prediction, origin_h, origin_w, conf_thres=0.5, nms_thres=0.4):
"""
description: Removes detections with lower object confidence score than 'conf_thres' and performs
Non-Maximum Suppression to further filter detections.
param:
prediction: detections, (x1, y1, x2, y2, conf, cls_id)
origin_h: original image height
origin_w: original image width
conf_thres: a confidence threshold to filter detections
nms_thres: a iou threshold to filter detections
return:
boxes: output after nms with the shape (x1, y1, x2, y2, conf, cls_id)
"""
# Get the boxes that score > CONF_THRESH
boxes = prediction[prediction[:, 4] >= conf_thres]
# Trandform bbox from [center_x, center_y, w, h] to [x1, y1, x2, y2]
boxes[:, :4] = self.xywh2xyxy(origin_h, origin_w, boxes[:, :4])
# clip the coordinates
boxes[:, 0] = np.clip(boxes[:, 0], 0, origin_w - 1)
boxes[:, 2] = np.clip(boxes[:, 2], 0, origin_w - 1)
boxes[:, 1] = np.clip(boxes[:, 1], 0, origin_h - 1)
boxes[:, 3] = np.clip(boxes[:, 3], 0, origin_h - 1)
# Object confidence
confs = boxes[:, 4]
# Sort by the confs
boxes = boxes[np.argsort(-confs)]
# Perform non-maximum suppression
keep_boxes = []
while boxes.shape[0]:
large_overlap = self.bbox_iou(np.expand_dims(boxes[0, :4], 0), boxes[:, :4]) > nms_thres
label_match = boxes[0, -1] == boxes[:, -1]
# Indices of boxes with lower confidence scores, large IOUs and matching labels
invalid = large_overlap & label_match
keep_boxes += [boxes[0]]
boxes = boxes[~invalid]
boxes = np.stack(keep_boxes, 0) if len(keep_boxes) else np.array([])
return boxes
if __name__ == "__main__":
# load custom plugin and engine
engine_file_path = "build/device_17_5765_s.engine"
PLUGIN_LIBRARY = "build/libmyplugins.so"
source = 'samples/t1.mp4'
if len(sys.argv) > 1:
engine_file_path = sys.argv[1]
if len(sys.argv) > 2:
PLUGIN_LIBRARY = sys.argv[2]
if len(sys.argv) > 3:
source = sys.argv[3]
assert source.lower().endswith('mp4') or source.lower().startswith(('rtsp://', 'rtmp://'))
ctypes.CDLL(PLUGIN_LIBRARY)
# load coco labels
categories = ["person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat",
"traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse",
"sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie",
"suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove",
"skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon"]
# a YoLov5TRT instance
yolov5_wrapper = YoLov5TRT(engine_file_path)
try:
print('batch size is', yolov5_wrapper.batch_size)
for i in range(10):
result_boxes, result_scores, result_classid, use_time = yolov5_wrapper.infer(yolov5_wrapper.get_raw_image_zeros())
print('input->({},{}), time->{:.2f}ms'.format(yolov5_wrapper.input_h, yolov5_wrapper.input_w, use_time * 1000))
raw_image_generator = []
cap = cv2.VideoCapture(source)
t1 = time.time()
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
if yolov5_wrapper.batch_size == 1:
raw_image_generator = [frame]
result_boxes, result_scores, result_classid, use_time = yolov5_wrapper.infer(raw_image_generator)
print('input->{}\ttime->{:.2f}ms'.format(cap.get(cv2.CAP_PROP_POS_FRAMES), use_time * 1000))
else:
if cap.get(cv2.CAP_PROP_POS_FRAMES) % yolov5_wrapper.batch_size == 0:
raw_image_generator.append(frame)
result_boxes, result_scores, result_classid, use_time = yolov5_wrapper.infer(raw_image_generator)
print('input->{}\ttime->{:.2f}ms'.format(cap.get(cv2.CAP_PROP_POS_FRAMES), use_time * 1000))
raw_image_generator = []
else:
raw_image_generator.append(frame)
print('FPS:', cap.get(cv2.CAP_PROP_FRAME_COUNT) / (time.time() - t1))
cap.release()
finally:
# destroy the instance
yolov5_wrapper.destroy()
新增了第三个命令行参数source作为视频路径或视频流地址,类别名categories根据自己的改,因为我反正不画图不展示也不保存,所以这个类别名只是用来打印结果的,写中文还是英文没区别。画图和保存的代码我都不要了,大家可以根据自己需求保留。
我用yolov5s.pt生成的engine,跑测试视频,没有画框和保存的情况下,帧率刚好超过25,基本实时了。
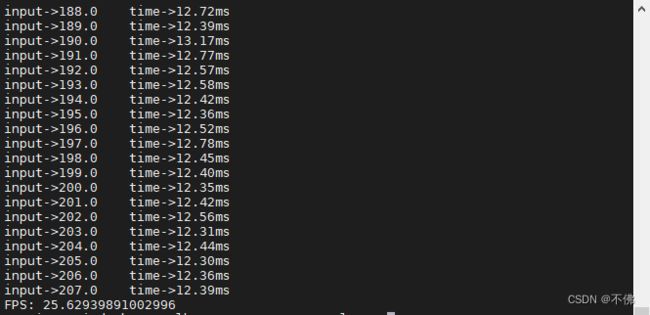
为了做比较,我这个代码也支持BATCH_SIZE>1的情况,即将每几帧图片一起推理,当然这个engine要重新生成。
我测试了一下当BATCH_SIZE=2的时候:
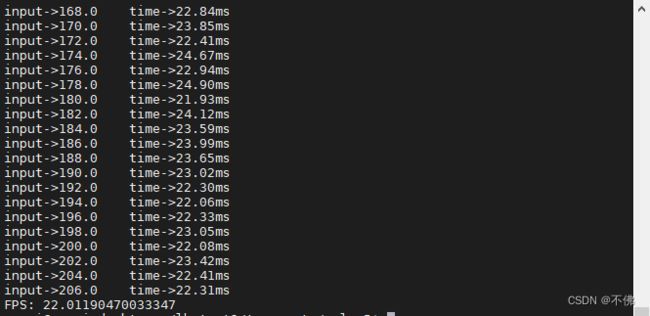
虽然看起来2帧的推理时间没有到原来的2倍,但整体速度反而变慢了。
------------------------------------------------------------------我是一条慵懒的分割线------------------------------------------------------------------------------------
YOLOv5最新的6.1版本增加了TensorRT的导出和推理,记录一下自己的使用过程。
我这台NX的cuda和tensorrt是内置的,主要是python、torch和torchvision要匹配且符合YOLOv5要求。
还是用yolov5s.pt训练得到的模型best.pt,yolov5-6.1下,使用命令:
python3 export.py --device 0 --weights best.pt --include engine
导出TensorRT的模型,会先转成onnx再转成engine。
第一次转的时候,内存不足直接退出了,我的NX内存是8G。

应该是模型太大了?我把export.py中的export_engine()的workspace参数从4改成2,还是失败,用了最小的yolov5n还是内存爆炸。没找到办法,我想是不是因为先转onnx已经占了一部分内存,如果把这两步拆开内存可能就够用了。于是我把代码中将onnx转engine的部分给简化了出来:
import tensorrt as trt
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)
config = builder.create_builder_config()
config.max_workspace_size = 2 << 30
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, logger)
parser.parse_from_file('best.onnx')
with builder.build_engine(network, config) as engine, open('best.engine', 'wb') as t:
t.write(engine.serialize())
其中config.max_workspace_size = 2 << 30中的2就是workspace参数,如果内存还是不够用,可以改成1。onnx和engine的名字按自己的改就好了。先生成onnx,再用上述代码生成engine,这样终于成功了。
我用视频做推理测试
pt的推理速度为:
Speed: 1.3ms pre-process, 44.3ms inference, 3.5ms NMS per image at shape (1, 3, 640, 640)
engine的推理速度为:
Speed: 1.5ms pre-process, 31.9ms inference, 3.8ms NMS per image at shape (1, 3, 640, 640)
速度提升不多,这种通过onnx路径转engine的方式,和第一种直接用TensorRT的C++API复现模型的方式,效果还是有挺大差别的。生成的模型也不一样,YOLOv5生成的engine会大得多。