2022-10-27学习记录
一、图片数据增强代码
1.1 贴图混合的数据增强方法
@staticmethod
def rand_bbox(img_size, lam):
"""Generate a random boudning box."""
w = img_size[-1]
h = img_size[-2]
cut_rat = torch.sqrt(1. - lam)
cut_w = torch.tensor(int(w * cut_rat))
cut_h = torch.tensor(int(h * cut_rat))
# uniform
cx = torch.randint(w, (1, ))[0]
cy = torch.randint(h, (1, ))[0]
bbx1 = torch.clamp(cx - cut_w // 2, 0, w)
bby1 = torch.clamp(cy - cut_h // 2, 0, h)
bbx2 = torch.clamp(cx + cut_w // 2, 0, w)
bby2 = torch.clamp(cy + cut_h // 2, 0, h)
return bbx1, bby1, bbx2, bby2
def do_blending(self, imgs, label, **kwargs):
"""Blending images with cutmix."""
assert len(kwargs) == 0, f'unexpected kwargs for cutmix {kwargs}'
batch_size = imgs.size(0)
rand_index = torch.randperm(batch_size)
lam = self.beta.sample()
bbx1, bby1, bbx2, bby2 = self.rand_bbox(imgs.size(), lam)
imgs[:, ..., bby1:bby2, bbx1:bbx2] = imgs[rand_index, ..., bby1:bby2,
bbx1:bbx2]
lam = 1 - (1.0 * (bbx2 - bbx1) * (bby2 - bby1) /
(imgs.size()[-1] * imgs.size()[-2]))
label = lam * label + (1 - lam) * label[rand_index, :]
return imgs, label
1.2 随机混合的数据增强方法
def do_blending(self, imgs, label, **kwargs):
"""Blending images with mixup."""
assert len(kwargs) == 0, f'unexpected kwargs for mixup {kwargs}'
lam = self.beta.sample()
batch_size = imgs.size(0)
rand_index = torch.randperm(batch_size)
mixed_imgs = lam * imgs + (1 - lam) * imgs[rand_index, :]
mixed_label = lam * label + (1 - lam) * label[rand_index, :]
return mixed_imgs, mixed_label
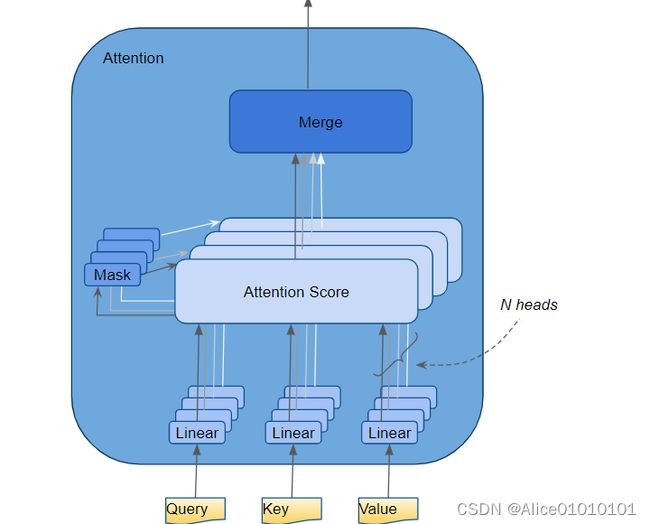
二、Multi-Head Attention中的multi结构
三、论文segformer
3.1 分析一
代码中的Transformer Block实际结构图为:

3.2 分析二
之前工作的相对复杂的decoder在CNN encoder上很重要且很有意义,但是在Segformer里,简单的MLP decoder也能work的很好,这是为什么呢?这里需要引出一个概念: 有效感受野(Effective Receptive Field)。关于有效感受野可以看这篇17年的论文:Understanding the Effective Receptive Field in Deep Convolutional Neural Networks对于语义分割来说最重要的问题就是如何增大感受野,之前无数的工作也都是在研究这方面。首先对于CNN encoder来说,有效感受野是比较小且局部的,所以需要一些decoder 的设计来增大有效感受野,比如ASPP里利用了不同大小的空洞卷积来实现这一目的。但是对于Transformer encoder来说,由于 self-attention这一牛逼的操作,有效感受野变得非常大,因此decoder 不需要更多操作来提高感受野(self-attention 永远滴神!)。我们也设计了ablation study具体见论文的Table 1d.
3.3 分析三
如果训练和测试时的图片大小和分辨率不一致,而位置编码PE固定的话,则在测试时需要使用插值来预测相应的位置编码。Segformer使用Mix-FFN中的zero-padding来leak location information.

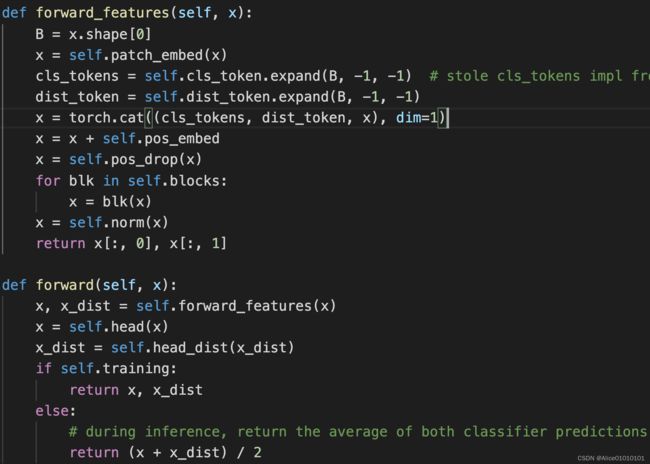
四、DEIT:在ViT的基础上主要有了两点变化
4.1 变化一
添加了cls_token和distillation_token,和input在dim=1维度上进行拼接。输出x和x_dis,并分别通过self.head输出结果output,通过self.head_dist输出蒸馏的结果output_kd
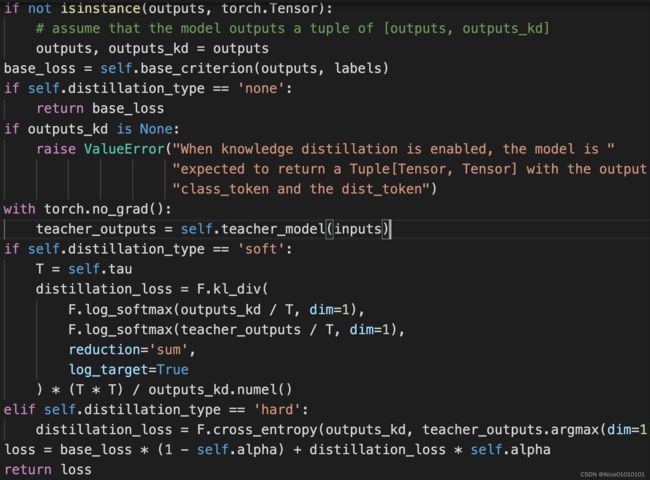
4.2 变化二
设计loss,在基础output和label的交叉熵损失函数之外;将input通过指定的teacher network(default为regnety_160)得到输出teacher_output,并将teacher_output和output_kd进行KL散度损失函数;两个损失函数相加
五、计算两个矩阵之间的欧氏距离

六、PointTAD 任务:多标签时序动作检测
6.1 任务描述
下图S1和S2代表两种不同的错误预测类型:
S1 successfully predicts the correct action category with an incomplete segment of action highlights, whereas S2 does a better job in locating the boundaries yet get misclassifified as “Sit” due to the inclusion of confusing frames.
6.2 任务介绍
Segment-based representation:基于时序分割片段的表示
时序片段在模型整个训练框架中,有三种不同的用法。作为anchors,中间proposals和final predictions。
- As anchors. Segments as anchors are explored mainly in anchor-based frameworks. These methods used sliding windows or proposal generation results as anchors.
- As proposals. Most TAD methods use segments as intermediate proposals. Uniform sampling or pooling are commonly used to extract features from these segments. P-GCN applied max-pooling within local segments for proposal features. G-TAD uniformly divided segments into bins and average-pooled each bin to obtain proposal features. AFSD proposed boundary pooling in boundary region to refine action feature.
- As final predictions. Segments as final predictions are employed among all three types of TAD frameworks, because segments generally facilitate the computation of action overlaps and loss calculation.
- PointTAD直接使用learnable query points as intermediate proposals with iterative refinement. The learnable query points represent the important frames within action and action feature is extracted only from these keyframes rather than using RoI pooling.
6.3 pipeline
一个Query points针对一个video clip,包含Ns(设置为21)个关键帧位置。初始化为输入视频片段的时间中点,每个位置(每个query point)表示的偏移量由query vectors生成,用来对位置表示进行迭代更新(Iterative point refinement),而每个位置(每个query point)表示通过regression loss更新在多阶段更新;其中通过随机选取2/3Ns的点,选出值最小和最大的点生成伪标签,参与分类损失L1-loss和时间框损失tIoU loss的计算。
6.4 解码器核心部分
七、DETR二分图匹配部分

八、PGCN
首先将输入的视频均匀地划分为多个64帧的片段,作为一系列proposals,使用I3D提取每个proposal(时间段)内的特征向量。在图中,以每个proposal特征为图的结点,tIoU>threshold为邻近相似结点,在邻接矩阵中建立邻接关系;以d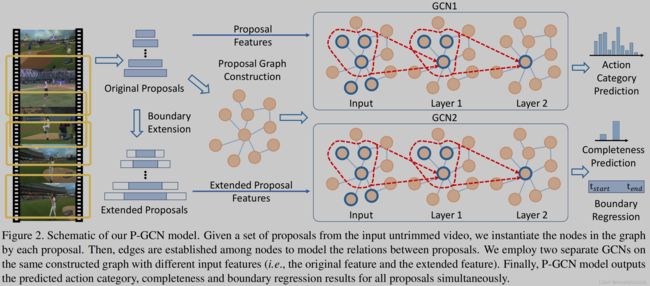
九、DeepGCN