Visual SLAM: What are the Current Trends and What to Expect?
引自
Tourani A, Bavle H, Sanchez-Lopez J L, et al. Visual SLAM: What are the Current Trends and What to Expect?[J]. arXiv preprint arXiv:2210.10491, 2022.
摘要
介绍VSLAM系统的最新进展,以及讨论现有的挑战和趋势。我们对vslam领域发表的45篇有影响力的论文进行了深入的文献调查。我们根据不同的特征对这些稿件进行了分类,包括新颖性领域、目的、采用的算法和语义层次。
引言
vslam主要包括一个视觉里程计(VO)前端,用于局部估计相机的行径,以及一个SLAM后端,以优化创建的地图,在每个类别中使用的模块的多样性导致实现的变化。VO根据局部一致性提供机器人位置和姿态的初步估计,并发送到后端进行优化。因此,VSLAM和VO的主要区别在于是否考虑地图和预测轨迹的全局一致性。一些最先进的VSLAM应用程序还包括两个附加模块:环路关闭检测和映射。它们负责识别之前访问过的位置,以便根据相机姿势进行更精确的跟踪和地图重建。
本文对45篇VSLAM论文进行了调查,并根据不同方面进行了分类。我们希望我们的工作能为机器人研究人员改进VSLAM技术提供参考。本文的其余部分组织如下:第二节回顾了VSLAM方法的演化阶段,这些阶段导致了目前存在的系统。我们将在第三节中介绍和讨论VSLAM领域的其他已发表的调查。第四节给出了各种VSLAM模块的抽象级别,第五节给出了基于主要贡献的先进水平的分类。然后,我们将在第六节讨论该领域尚未解决的挑战和潜在趋势。本文最后在第七节结束。
视觉slam算法的进化
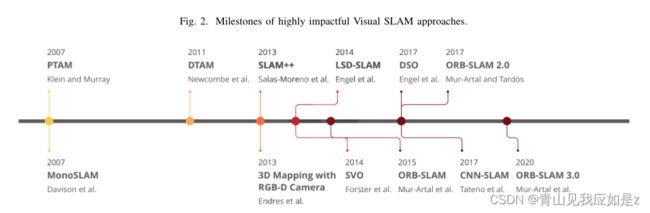
文献中第一个实现实时单目VSLAM系统的努力是由Davison等人在2007年开发的,他们介绍了一个名为Mono-SLAM[17]的框架。他们的间接框架可以利用扩展卡尔曼滤波(EKF)算法[18]来估计世界上的摄像机运动和3D元素。尽管缺乏全局优化和闭环检测模块,Mono-SLAM在VSLAM领域开始起主要作用。然而,用这种方法重建的地图只包括地标,并没有提供关于该地区的进一步详细信息。Klein等人同年在[14]中提出了并行跟踪与映射(PTAM),他们将整个VSLAM系统划分为两个主要线程:跟踪和映射。这个多线程基线在以后的工作中得到了许多后续工作的认可,本文将对此进行讨论。他们方法的主要思想是减少计算成本,并应用并行处理来实现实时性能。跟踪线程实时估计相机运动,映射预测特征点的三维位置。PTAM也是第一个利用束调整(BA)来联合优化相机姿势和创建的3D地图的方法。该算法利用加速分段测试(FAST)[19]角点检测算法的特征进行关键点匹配和跟踪。尽管该算法的性能优于Mono-SLAM,但设计复杂,第一阶段需要用户输入。测量深度值和运动参数的直接方法是由纽科姆等人在2011年提出的密集跟踪和映射(DTAM)。DTAM是一个配备了密集映射和密集跟踪模块的实时框架,可以通过将整个帧与给定的深度图对齐来确定相机姿势。为了构建环境图,上述阶段分别估计场景的深度和运动参数。尽管DTAM可以提供地图的详细表示,但它需要很高的计算成本来实时执行。作为3D映射和基于像素的优化领域的另一种间接方法,Endres等人在2013年提出了一种可用于RGB-D相机的方法。他们的方法实时执行,专注于低成本的嵌入式系统和小型机器人,但它不能在无特征或具有挑战性的场景中产生准确的结果。同年,Salas-Moreno等人提出了在实时SLAM框架中利用语义信息的第一个尝试之一,命名为SLAM++。他们的系统采用RGB-D传感器输出,并执行3D相机姿态估计和跟踪,以形成一个姿态图。位姿图是一种图,其中的节点表示位姿估计,并由表示测量不确定度的节点之间的相对位姿的边连接。然后,通过合并从场景中语义对象获得的相对3D姿势,对预测的姿势进行优化。
[14] G. Klein and D. Murray, “Parallel tracking and mapping for small ar workspaces,” in 2007 6th IEEE and ACM international symposium on mixed and augmented reality. IEEE, 2007, pp. 225–234.
[17] A. J. Davison, I. D. Reid, N. D. Molton, and O. Stasse, “Monoslam: Real-time single camera slam,” IEEE transactions on pattern analysis and machine intelligence, vol. 29, no. 6, pp. 1052–1067, 2007.
[18] M. I. Ribeiro, “Kalman and extended kalman filters: Concept, derivation and properties,” Institute for Systems and Robotics, vol. 43, p. 46, 2004.
[19] D. G. Viswanathan, “Features from accelerated segment test (fast),” in Proceedings of the 10th workshop on image analysis for multimedia interactive services, London, UK, 2009, pp. 6–8.
随着VSLAM基线的不断成熟,研究人员将注意力集中在提高这些系统的性能和精度上。在这方面,Forster等人在2014年提出了一种混合VO方法,称为半直接视觉里程计(SVO)[24],作为VSLAM体系结构的一部分。他们的方法可以合并基于特征的方法和直接方法来执行传感器的运动估计和映射任务。SVO可以同时使用单眼和立体摄像机,并配备了位姿优化模块,以尽量减少重投影误差。然而,SVO的主要缺点是使用短期数据关联,不能执行闭环检测和全局优化。LSD-SLAM[25]是Engel等人在2014年推出的另一个有影响力的VSLAM方法,包含跟踪、深度地图估计和地图优化线程。该方法可以利用其姿态图估计模块重构大比例尺地图,并具有全局优化和闭环检测功能。LSD-SLAM的缺点是它具有挑战性的初始化阶段需要在一个平面上的所有点,这使得它成为一种计算密集型的方法。穆尔-阿尔塔尔等人介绍了两种精确的间接VSLAM方法,目前已引起许多研究人员的注意:ORB-SLAM[26]和ORBSLAM 2.0[27]。这些方法可以在纹理良好的序列中完成定位和映射,并利用面向快速和旋转简要(ORB)特征进行高性能的位置识别。ORBSLAM的第一个版本能够使用从相机位置收集的关键帧计算相机位置和环境的结构。第二个版本是对ORB-SLAM的扩展,具有三个并行线程,包括用于查找特征对应的跟踪,用于映射管理操作的本地映射,以及用于检测新循环和纠正漂移错误的循环关闭。虽然ORB-SLAM 2.0可以在单目和立体相机设置下工作,但由于重构地图的比例尺未知,它不能用于自主导航。这种方法的另一个缺点是它不能在无纹理的区域或具有重复模式的环境中工作。该框架的最新版本被命名为ORB-SLAM 3.0,于2021年[28]提出。它适用于各种类型的相机,如单目,RGB-D和立体视觉,并提供改进的姿态估计输出。
[24] C. Forster, M. Pizzoli, and D. Scaramuzza, “Svo: Fast semi-direct monocular visual odometry,” in 2014 IEEE international conference on robotics and automation (ICRA). IEEE, 2014, pp. 15–22.
[25] J. Engel, T. Sch¨ops, and D. Cremers, “Lsd-slam: Large-scale direct monocular slam,” in European conference on computer vision. Springer, 2014, pp. 834–849.
[26] R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “Orb-slam: a versatile and accurate monocular slam system,” IEEE transactions on robotics, vol. 31, no. 5, pp. 1147–1163, 2015.
[27] R. Mur-Artal and J. D. Tard´os, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,” IEEE transactions on robotics, vol. 33, no. 5, pp. 1255–1262, 2017.
[28] C. Campos, R. Elvira, J. J. G. Rodr´ıguez, J. M. Montiel, and J. D. Tard´os, “Orb-slam3: An accurate open-source library for visual, visual– inertial, and multimap slam,” IEEE Transactions on Robotics, vol. 37, no. 6, pp. 1874–1890, 2021.
近年来,随着深度学习在各个领域的显著影响,基于深度神经网络的方法可以通过提供更高的识别和匹配率来解决许多问题。类似地,在VSLAM中用学习到的特征代替手工制作是许多近期基于深度学习的方法提出的解决方案之一。在这方面,Tateno等人提出了一种基于卷积神经网络(CNNs)的方法,该方法处理用于相机姿态估计的输入帧,并使用关键帧进行深度预测,称为CNN-SLAM[29]。将相机帧分割成更小的部分以更好地理解环境是CNN-SLAM提供并行处理和实时性能的想法之一。作为一种不同的方法,Engel等人还在直接VSLAM算法中引入了一种新的趋势,称为直接稀疏距离计(DSO)[30],该算法将直接方法与稀疏重建相结合,提取图像块中强度最高的点。通过对稀疏像素集的跟踪,考虑图像形成参数,采用间接跟踪方法。需要注意的是,DSO只能在使用光测量校准的相机时提供完美的精度,而不能在使用常规相机时获得高精度的结果。
[29] K. Tateno, F. Tombari, I. Laina, and N. Navab, “Cnn-slam: Real-time dense monocular slam with learned depth prediction,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6243–6252.
[30] J. Engel, V. Koltun, and D. Cremers, “Direct sparse odometry,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 3, pp. 611–625, 2017.
相关调查
在VSLAM领域有各种调查论文,对不同的现有方法进行了一般性的回顾。这些论文中的每一篇都回顾了使用VSLAM方法的主要优点和缺点。Macario Barros等人[31]将方法分为三个不同的类别:仅视觉(单眼)、视觉惯性(立体)和RGB-D。他们还提出了各种简化VSLAM算法分析的标准。然而,它们不包括其他视觉传感器,如基于事件相机的传感器,我们将在后面的IV -A中讨论。Chen等人[32]回顾了广泛的传统和语义VSLAM出版物。他们将SLAM开发时代划分为经典阶段、算法分析阶段和健壮感知阶段,并介绍了其中的热点问题。他们还总结了使用直接/间接方法的经典框架,并研究了深度学习算法在语义分割中的影响。尽管他们的工作为该领域的高级解决方案提供了全面的研究,但方法的分类仅局限于基于特征的vslam中使用的特征类型。Jia等人[33]调查了大量的手稿,并简要比较了基于图优化的方法和配有深度学习的方法。尽管提出了适当的比较,但由于审查的论文数量有限,他们的讨论不能一般化。在另一项工作中,Abaspur Kazerouni等人[34]涵盖了各种VSLAM方法,利用感官设备、数据集和模块,模拟了几种间接方法进行比较和分析。它们只对基于特征的算法做出贡献,例如HOG、尺度不变特征变换(SIFT)、加速鲁棒特征(SURF)和基于深度学习的解决方案。Bavle等人[35]分析了各种SLAM和VSLAM应用程序中的态势感知方面,并讨论了它们的缺失点。他们可以得出结论,操作缺乏的态势感知特征可以提高当前研究工作的绩效。
其他一些调查研究了VSLAM的最新方法,主要针对一个特定的主题或趋势。例如,Duan等人[15]调查了交通机器人视觉SLAM系统中深度学习的进展。作者在论文中总结了在VO和闭环检测任务中使用各种基于深度学习的方法的优缺点。在vslam中使用深度学习方法的显著优势是在姿态估计和整体性能计算中精确的特征提取。在同一领域的另一项工作中,Arshad和Kim[36]关注深度学习算法在使用可视化数据的闭环检测中的影响。他们查阅了VSLAM的各种论文,并分析了机器人在不同条件下的长期自主性。Singandhupe和La[37]回顾了VO和VSLAM对无人驾驶汽车的影响。
[32] W. Chen, G. Shang, A. Ji, C. Zhou, X. Wang, C. Xu, Z. Li, and K. Hu, “An overview on visual slam: From tradition to semantic,” Remote Sensing, vol. 14, no. 13, p. 3010, 2022.
[33] Y. Jia, X. Yan, and Y. Xu, “A survey of simultaneous localization and mapping for robot,” in 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), vol. 1. IEEE, 2019, pp. 857–861.
[34] I. A. Kazerouni, L. Fitzgerald, G. Dooly, and D. Toal, “A survey of state-of-the-art on visual slam,” Expert Systems with Applications, p. 117734, 2022.
[35] H. Bavle, J. L. Sanchez-Lopez, E. F. Schmidt, and H. Voos, “From slam to situational awareness: Challenges and survey,” arXiv preprint arXiv:2110.00273, 2021.
[15] C. Duan, S. Junginger, J. Huang, K. Jin, and K. Thurow, “Deep Learning for Visual SLAM in Transportation Robotics: A Review,” Transportation Safety and Environment, vol. 1, no. 3, pp. 177–184, 01 2020. [Online]. Available: https://doi.org/10.1093/tse/tdz019
[36] S. Arshad and G.-W. Kim, “Role of deep learning in loop closure detection for visual and lidar slam: A survey,” Sensors, vol. 21, no. 4, p. 1243, 2021.
[37] A. Singandhupe and H. M. La, “A review of slam techniques and security in autonomous driving,” in 2019 third IEEE international conference on robotic computing (IRC). IEEE, 2019, pp. 602–607.
VSLAM设置标准
考虑到各种VSLAM方法,我们可以将不同的设置和配置分为以下类别:
A.传感器和数据采集
Davison等人介绍的VSLAM算法的早期实现。[17]配备了一个单目摄像机,用于轨迹恢复。单目摄像机是最常见的视觉传感器,用于广泛的任务,如物体检测和跟踪。另一方面,立体相机包含两个或两个以上的图像传感器,使它们能够感知捕获图像的深度,从而在VSLAM应用中获得更精确的性能。这些相机的设置是成本效益和提供信息的感知更高的精度要求。RGB-D相机是vslam中使用的视觉传感器的其他变体,提供场景的深度和颜色。上述视觉传感器可以在简单的情况下提供丰富的环境信息,例如,适当的照明和运动速度,但它们往往难以应对照明低或场景动态范围高的情况。
[17] A. J. Davison, I. D. Reid, N. D. Molton, and O. Stasse, “Monoslam: Real-time single camera slam,” IEEE transactions on pattern analysis and machine intelligence, vol. 29, no. 6, pp. 1052–1067, 2007.
此外,一些方法使用多摄像头设置来解决在现实环境中工作的常见问题,并提高定位精度。利用多个视觉传感器在复杂的情况下,如遮挡,伪装,传感器故障,或可跟踪纹理稀疏发生的情况下,通过提供摄像机的重叠视野。虽然多摄像头设置可以解决一些数据采集问题,但只有摄像头的vslam可能面临各种挑战,如遇到快速移动的物体时的运动模糊,低或强照明下的特征不匹配,高节奏变化场景下的动态对象忽略等。因此,一些VSLAM应用程序可能会在摄像头旁边配备多个传感器。融合事件和标准帧[42]或集成其他传感器,如激光雷达[43]和imu到VSLAM是一些现有的解决方案。
[42] A. R. Vidal, H. Rebecq, T. Horstschaefer, and D. Scaramuzza, “Ultimate slam? combining events, images, and imu for robust visual slam in hdr and high-speed scenarios,” IEEE Robotics and Automation Letters,
vol. 3, no. 2, pp. 994–1001, 2018.
[43] L. Xu, C. Feng, V. R. Kamat, and C. C. Menassa, “An occupancy grid mapping enhanced visual slam for real-time locating applications in indoor gps-denied environments,” Automation in Construction, vol. 104, pp. 230–245, 2019.
B.目标环境
在许多传统的VSLAM实践中,机器人工作在一个静态的世界中,不会有突然或意想不到的变化,这是一个强有力的假设。因此,尽管许多系统可以在特定的设置中证明成功的应用,但环境中一些意想不到的变化(例如,移动对象的存在)可能会给系统造成复杂性,并在很大程度上降低状态估计质量。在动态环境中工作的系统通常使用诸如光流或随机样本共识(RANSAC)[44]等算法来检测场景中的运动,将运动对象分类为异常值,并在重构地图时跳过它们。这类系统或利用几何/语义信息,或试图通过结合这两个[45]的结果来改进定位方案。
[44] M. A. Fischler and R. C. Bolles, “Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography,” Communications of the ACM, vol. 24, no. 6, pp. 381–395, 1981.
[45] L. Cui and C. Ma, “Sof-slam: A semantic visual slam for dynamic environments,” IEEE access, vol. 7, pp. 166 528–166 539, 2019.
此外,我们还可以将不同的环境分为室内和室外,作为一种一般分类法。户外环境可以是具有建筑和道路纹理等结构地标和大规模运动变化的城市区域,也可以是具有弱运动状态的越野区域,如移动的云和植被、沙子的纹理等。因此,在越野环境中可跟踪点的数量少于城市区域,增加了定位和闭环检测失败的风险。另一方面,室内环境包含具有完全不同的全局空间属性的场景,如走廊、墙壁和房间。我们可以预见,虽然VSLAM系统可能在上述的一个区域中工作得很好,但在其他环境中可能不能显示相同的性能。
C.视觉特征处理
如第一节所述,检测视觉特征并利用特征描述符信息进行姿态估计是间接VSLAM方法的一个必然阶段。这些方法采用各种特征提取算法来更好地理解环境,跟踪连续帧中的特征点。特征提取阶段包含了广泛的算法,包括SIFT[46]、SURF[47]、FAST[19]、二进制鲁棒独立基本特征(BRIEF)[48]、ORB[49]等。其中,与SIFT和SURF[50]相比,ORB特征具有快速提取和匹配的优点,且不损失巨大的精度。
[46] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,” International journal of computer vision, vol. 60, no. 2, pp. 91–110, 2004.
[47] H. Bay, T. Tuytelaars, and L. V. Gool, “Surf: Speeded up robust features,” in European conference on computer vision. Springer, 2006, pp. 404–417.
[19] D. G. Viswanathan, “Features from accelerated segment test (fast),” in Proceedings of the 10th workshop on image analysis for multimedia interactive services, London, UK, 2009, pp. 6–8.
[48] M. Calonder, V. Lepetit, C. Strecha, and P. Fua, “Brief: Binary robust independent elementary features,” in European conference on computer vision. Springer, 2010, pp. 778–792.
[49] E. Rublee, V. Rabaud, K. Konolige, and G. Bradski, “Orb: An efficient alternative to sift or surf,” in 2011 International conference on computer vision. Ieee, 2011, pp. 2564–2571.
[50] E. Karami, S. Prasad, and M. Shehata, “Image matching using sift, surf, brief and orb: performance comparison for distorted images,” arXiv preprint arXiv:1710.02726, 2017.
上面提到的一些方法的问题是,它们不能有效地适应各种复杂和不可预见的情况。因此,许多研究人员使用cnn来提取图像的各个阶段的深层特征,包括VO、位姿估计和环路闭合检测。根据方法的功能,这些技术可以表示有监督或无监督框架。
D.系统评估
虽然一些VSLAM方法,特别是那些能够在动态和具有挑战性的环境中工作的方法在现实条件下的机器人上进行了测试,但许多研究工作已经使用公开的数据集来证明它们的适用性。在这方面,Bonarini等人的RAWSEEDS Dataset。[51]是一个著名的多传感器基准测试工具,包含室内、室外和混合机器人轨迹与地面真实数据。它是用于机器人和SLAM目的的最古老的公开基准测试工具之一。McCormac等人的Scenenet RGB-D。[52]是另一个用于场景理解问题的数据集,如语义分割和对象检测,包含500万张大规模渲染的RGB-D图像。该数据集还包含像素完美的地面真实标签和精确的相机姿势和深度数据,使其成为VSLAM应用程序的有力工具。最近VSLAM和VO领域的许多工作都在TUM RGB-D数据集[53]上测试了他们的方法。上述数据集和基准测试工具包含由Microsoft Kinect传感器和相应的地面传感器轨迹捕获的彩色和深度图像。此外,Nguyen等人的NTUVIRAL。[54]是一个由配备3D激光雷达、相机、imu和多个超宽带(uwb)的UA V收集的数据集。该数据集包含室内和室外实例,用于评估自动驾驶和空中操作性能。
[51] A. Bonarini, W. Burgard, G. Fontana, M. Matteucci, D. G. Sorrenti, and J. D. Tardos, “Rawseeds: Robotics advancement through webpublishing of sensorial and elaborated extensive data sets,” in In proceedings of IROS, vol. 6, 2006, p. 93.
[52] J. McCormac, A. Handa, S. Leutenegger, and A. J. Davison, “Scenenet rgb-d: Can 5m synthetic images beat generic imagenet pre-training on indoor segmentation?” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 2678–2687.
[53] J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of rgb-d slam systems,” in 2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2012, pp. 573–580.
[54] T.-M. Nguyen, S. Yuan, M. Cao, Y. Lyu, T. H. Nguyen, and L. Xie, “Ntu viral: A visual-inertial-ranging-lidar dataset, from an aerial vehicle viewpoint,” Internationl Journal of Robotics Research, 2021.
此外,Burri等人的EuRoC MA V[55]是另一个流行的数据集,包含由立体相机捕获的图像,以及同步IMU测量和运动地面真相。在EuRoC MA V中收集的数据根据周围条件分为易、中、难三类。[56]是VSLAM作品的另一个公开数据集,包含由配备各种传感器的轮式机器人收集的广泛数据。它为单目和RGB-D算法提供了适当的数据,以及车轮编码器的里程计数据。作为VSLAM应用程序中使用的更通用的数据集,KITTI[57]是受欢迎的数据集合,由移动车辆上的两个高分辨率RGB和灰度视频摄像机捕获。KITTI使用GPS和激光传感器提供精确的地面真相,使其成为移动机器人和自动驾驶领域非常受欢迎的数据集。TartanAir[58]是另一个用于在具有挑战性的场景下评估SLAM算法的基准数据集。此外,伦敦帝国理工学院和爱尔兰国立大学Maynooth (ICL-NUIM)[59]数据集是另一个包含手持RGB-D相机序列的VO数据集,它已被用作许多SLAM工作的基准。
[56] X. Shi, D. Li, P. Zhao, Q. Tian, Y. Tian, Q. Long, C. Zhu, J. Song, F. Qiao, L. Song et al., “Are we ready for service robots? the openloris-scene datasets for lifelong slam,” in 2020 IEEE international conference on robotics and automation (ICRA). IEEE, 2020, pp. 3139–
3145.
[57] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012, pp. 3354– 3361.
[58] W. Wang, D. Zhu, X. Wang, Y. Hu, Y. Qiu, C. Wang, Y. Hu, A. Kapoor, and S. Scherer, “Tartanair: A dataset to push the limits of visual slam,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 4909–4916.
[59] A. Handa, T. Whelan, J. McDonald, and A. J. Davison, “A benchmark for rgb-d visual odometry, 3d reconstruction and slam,” in 2014 IEEE international conference on Robotics and automation (ICRA). IEEE, 2014, pp. 1524–1531.
根据传感器设置、应用程序和目标环境,上述数据集可用于多种VSLAM方法。这些数据集主要包含摄像机的外部和内部标定参数以及地面真相数据。表一和图3分别总结了数据集的特征和每个数据集的一些实例。

E.语义层面
机器人需要语义信息来理解周围的场景,并做出更有利的决策。在最近的许多VSLAM工作中,在基于几何的数据中添加语义级信息优于纯基于几何的方法,使其能够传递周围环境的概念性知识[61]。在这方面,预先训练的对象识别模块可以向VSLAM模型添加语义信息[62]。最近的一种方法是在VSLAM应用程序中使用cnn。一般来说,语义VSLAM方法包含以下四个主要组件:
•跟踪模块:利用从连续视频帧中提取的二维特征点,估计摄像机姿态,构建三维地图点。通过相机位姿的计算和三维地图点的构建,分别建立了定位和映射过程的基线。
•本地映射模块:通过处理两个连续的视频帧,创建一个新的3D映射点,它与BA模块一起用于改进相机姿势。
•循环关闭模块:通过将关键帧与提取的视觉特征进行比较,并评估它们之间的相似性,调整相机姿势并优化构建的地图。
•非刚性上下文剔除(NRCC):使用NRCC的主要目标是从视频帧中过滤时间对象,以减少它们对定位和映射阶段的有害影响。它主要包含一个屏蔽/分割过程,用于分离帧中的各种不稳定实例,如人。由于NRCC减少了要处理的特征点的数量,因此它简化了计算部分,并产生了更健壮的性能。
因此,在VSLAM方法中利用语义层次可以提高姿态估计和映射重构的不确定性。然而,目前的挑战是如何正确使用提取的语义信息,而不会对计算成本产生巨大影响。
[61] C. Yu, Z. Liu, X.-J. Liu, F. Xie, Y. Yang, Q. Wei, and Q. Fei, “Dsslam: A semantic visual slam towards dynamic environments,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 1168–1174.
[62] S. Wen, P. Li, Y. Zhao, H. Zhang, F. Sun, and Z. Wang, “Semantic visual slam in dynamic environment,” Autonomous Robots, vol. 45, no. 4, pp. 493–504, 2021.
以主要目标为依据的Vslam方法
为了找到能够获得丰富成果并呈现健壮架构的VSLAM方法,我们从谷歌学术和著名的计算机科学书目数据库Scopus和DBLP中收集并筛选了近年来在顶级场所发表的被引用率很高的出版物。我们还研究了上述出版物中提到的手稿,并对与VSLAM领域最相关的手稿进行了提纯。在对论文进行了研究之后,我们可以根据收集到的出版物解决某一特定问题的主要目的,将它们分为以下几个小节:
A.目标一:多传感器处理
这个类别涵盖了VSLAM方法的范围,这些方法使用各种传感器来更好地理解环境。
1)使用多台摄像机:
2)采用多传感器:
B.目标二:姿态估计
这类方法主要关注如何使用各种算法改进VSLAM方法的姿态估计。
1)采用线/点数据:
在这方面,Zhou等人[70]建议将建筑结构线作为确定相机姿态的有用特征。结构线与主要方向相关联,并编码全局方向信息,从而改善预测轨迹。上面提到的StructSLAM方法是一种6自由度(DoF) VSLAM技术,可以在低特征和无特征条件下工作。In使用EKF根据场景中当前的方向来估计变量。为了进行评价,使用了来自RAWSEEDS 2009的室内场景数据集和一组生成的序列图像数据集。
[70] H. Zhou, D. Zou, L. Pei, R. Ying, P. Liu, andW. Yu, “Structslam: Visual slam with building structure lines,” IEEE Transactions on Vehicular Technology, vol. 64, no. 4, pp. 1364–1375, 2015.
点线SLAM (PL-SLAM)7是一种基于ORB-SLAM的针对非动态低纹理设置优化的VSLAM系统,由Pumarola等人提出[71]。该系统同时融合了线和点特征,以改进姿态估计,并有助于在特征点很少的情况下运行。作者在他们生成的数据集和TUM RGB-D上测试了PL-SLAM。他们的方法的缺点是计算成本和使用其他几何原语的本质,如平面,以获得更鲁棒的精度。
[71] A. Pumarola, A. Vakhitov, A. Agudo, A. Sanfeliu, and F. Moreno-Noguer, “Pl-slam: Real-time monocular visual slam with points and lines,” in 2017 IEEE international conference on robotics and automation (ICRA). IEEE, 2017, pp. 4503–4508.
Gomez-Ojeda等人[72]介绍了PL-SLAM8(不同于Pumarola等人[71]中的同名框架),这是一种间接的VSLAM技术,利用立体视觉摄像机中的点和线来重建看不见的地图。他们将从所有VSLAM模块中的点和线中获得的片段与从他们的方法中连续帧中获得的视觉信息合并在一起。利用ORB和线段检测器(LSD)算法,在PL-SLAM的后续立体帧中检索和跟踪点和线段。作者在EuRoC和KITTI数据集上测试了PL-SLAM,在性能方面可以优于ORB-SLAM 2.0的立体版本。PL-SLAM的主要缺点之一是特征跟踪模块所需的计算时间,并考虑所有结构线来提取环境信息。
[72] R. Gomez-Ojeda, F.-A. Moreno, D. Zuniga-No¨el, D. Scaramuzza, and J. Gonzalez-Jimenez, “Pl-slam: A stereo slam system through the combination of points and line segments,” IEEE Transactions on Robotics, vol. 35, no. 3, pp. 734–746, 2019.
Lim等人[73]提出了一种用于单目点线VSLAM系统的简并避免技术。基于光流的线路跟踪模块提取线路特征,过滤掉每帧中的短线路,并匹配之前识别的线路,这是他们方法的另一个贡献。为了证明他们的技术的有效性,并表明它优于现有的基于点的方法,他们在EuRoC MAV数据集上测试了他们的系统。该系统缺乏一种自适应的方法来识别正确的优化参数,尽管有强大的发现。
[73] H. Lim, Y. Kim, K. Jung, S. Hu, and H. Myung, “Avoiding degeneracy for monocular visual slam with point and line features,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 11 675–11 681.
2)使用额外的特征:
双四元数视觉SLAM (DQV-SLAM)是在[74]中提出的一种用于立体视觉相机的框架,它使用广泛的贝叶斯框架进行六自由度姿态估计。为了防止非线性空间变换群的线性化,他们的方法采用了渐进式贝叶斯更新。对于地图和光流的点云,DQVSLAM使用ORB特性在动态环境中实现可靠的数据关联。在KITTI和EuRoC数据集上,该方法能可靠地估计实验结果。然而,该方法缺乏对姿态随机建模的概率解释,且对基于采样近似的滤波有较高的计算要求。
[74] S. Bultmann, K. Li, and U. D. Hanebeck, “Stereo visual slam based on unscented dual quaternion filtering,” in 2019 22th International Conference on Information Fusion (FUSION). IEEE, 2019, pp. 1–8.
Mu ~ noz-Salinas等人[75]开发了一种使用人工正方形平面标记来重新创建大尺度室内环境地图的技术。如果每个视频帧中至少有两个标记可见,他们的实时SPM-SLAM系统可以解决使用标记进行姿态估计的模糊性问题。他们创建了一个数据集,将标记的视频序列放置在两个由一扇门连接的房间中进行检查。虽然SPM-SLAM具有成本效益,但它只有在大量平面标记分散在区域周围,且至少有两个可见标记连接识别时才能工作。此外,他们的框架处理场景动态变化的能力没有被测量。
[75] R. Munoz-Salinas, M. J. Marin-Jimenez, and R. Medina-Carnicer, “Spm-slam: Simultaneous localization and mapping with squared planar markers,” Pattern Recognition, vol. 86, pp. 156–171, 2019.
3)深度学习:
Bruno和Colombini[76]提出了LIFT-SLAM方法,将基于深度学习的特征描述符与传统的基于几何的系统相结合。他们扩展了ORB-SLAM系统的管道,并使用CNN从图像中提取特征,使用学到的特征提供更密集和更精确的匹配。为了实现检测、描述和方向估计的目的,LIFT- slam对学习不变特征变换(LIFT)深度神经网络进行了优化。使用KITTI和EuRoC MAV数据集的室内和室外实例的研究表明,LIFT-SLAM在准确性方面优于传统的基于特征和基于深度学习的VSLAM系统。然而,该方法的缺点是其计算密集的管道和未优化的CNN设计,导致接近实时性能。
[76] H. M. S. Bruno and E. L. Colombini, “Lift-slam: A deep-learning feature-based monocular visual slam method,” Neurocomputing, vol. 455, pp. 97–110, 2021.
Naveed等人[77]提出了一种基于深度学习的VSLAM解决方案,该方案具有可靠且一致的模块,即使是在极端转弯的路线上。他们的方法优于一些vslam,并使用了在现实模拟器上训练的深度强化学习网络。此外,它们为主动VSLAM评估提供了一个基线,可以在实际的室内和室外环境中恰当地推广。该网络的路径规划器开发了理想的路径数据,这些数据由其基础系统ORB-SLAM接收。他们制作了一个数据集,其中包含在具有挑战性和无纹理环境下的实际导航片段,用于评估。
[77] K. Naveed, M. L. Anjum, W. Hussain, and D. Lee, “Deep introspective slam: deep reinforcement learning based approach to avoid tracking failure in visual slam,” Autonomous Robots, vol. 46, no. 6, pp. 705– 724, 2022.
作为另一种方法,RWT-SLAM是作者在[78]中针对弱纹理情况提出的基于深度特征匹配的VSLAM框架。他们的方法基于ORB-SLAM,采用增强型LoFTR[79]算法的特征掩码进行局部图像特征匹配。采用CNN架构和LoFTR算法分别提取场景中的粗级描述符和细级描述符。RWT-SLAM在TUM RGB-D和OpenLORIS-Scene数据集以及作者收集的真实世界数据集上进行了检验。然而,尽管他们的系统具有健壮的特征匹配结果和性能,但计算量很大。
[78] Q. Peng, Z. Xiang, Y. Fan, T. Zhao, and X. Zhao, “Rwt-slam: Robust visual slam for highly weak-textured environments,” arXiv preprint arXiv:2207.03539, 2022.
[79] J. Sun, Z. Shen, Y. Wang, H. Bao, and X. Zhou, “Loftr: Detectorfree local feature matching with transformers,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8922–8931.
C.目标三:现实世界可行性
这类方法的主要目标是在各种环境中使用并在几种场景下工作。我们注意到,本节中的引用与从环境中提取的语义信息高度集成,并呈现了一个端到端VSLAM应用程序。
1)动态环境:
在这方面,Yu等人[61]提出了一种名为DS-SLAM9的VSLAM系统,该系统可用于动态上下文,并为地图构建提供语义级信息。该系统基于ORB-SLAM 2.0构建,包含五个线程:跟踪、语义分割、局部映射、闭环和密集语义映射构建。为了在位姿估计过程之前排除动态项目并提高定位精度,DS-SLAM采用了光流算法和一个称为SegNet的实时语义分割网络[80]。DS-SLAM已经在现实环境和RGB-D相机以及TUM RGB-D数据集上进行了测试。然而,尽管其定位精度较高,但存在语义分割的局限性和计算量大的特点。
[61] C. Yu, Z. Liu, X.-J. Liu, F. Xie, Y. Yang, Q. Wei, and Q. Fei, “Dsslam: A semantic visual slam towards dynamic environments,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 1168–1174.
[80] V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image segmentation,” IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 12, pp. 2481–2495, 2017.
语义光流SLAM (soft -SLAM)是建立在ORBSLAM 2.0 RGB-D模式基础上的间接VSLAM系统,是Cui和Ma[45]在高动态环境下提出的另一种方法。他们的方法使用语义光流动态特征检测模块,提取并跳过ORB特征提取提供的语义和几何信息中隐藏的变化特征。为了提供准确的相机姿势和环境报告,soft - slam利用了SegNet的像素级语义分割模块。在动态程度极高的情况下,在TUM RGB-D数据集和现实环境中的实验结果表明,soft - slam的性能优于ORB-SLAM 2.0。然而,非静态特征识别方法的有效性和对连续两帧的依赖是soft - slam的缺点。
[45] L. Cui and C. Ma, “Sof-slam: A semantic visual slam for dynamic environments,” IEEE access, vol. 7, pp. 166 528–166 539, 2019.
Cheng等人[81]利用光流方法分离和消除动态特征点,提出了一种用于动态环境的VSLAM系统。他们利用ORB-SLAM管道的结构,为其提供由典型单目相机输出生成的固定特征点,用于精确的姿态估计。该系统通过对光流值进行排序并将其用于特征识别,从而在无特征环境下工作。在TUM RGB-D数据集上的实验结果表明,该系统在动态室内环境下运行良好。然而,该系统的配置使用离线阈值进行运动分析,使其难以在各种动态环境情况下使用。
[81] J. Cheng, Y. Sun, and M. Q.-H. Meng, “Improving monocular visual slam in dynamic environments: an optical-flow-based approach,” Advanced Robotics, vol. 33, no. 12, pp. 576–589, 2019.
Yang等人[82]发布了另一种VSLAM策略,该策略使用语义分割网络数据、一种运动一致性检测技术和几何限制来重建环境图。他们的方法基于ORB-SLAM 2.0的RGB-D变体,在动态和室内环境中表现良好。采用改进的ORB特征提取技术,只保留场景中的稳定特征,而忽略动态特征。然后将这些特征和语义数据结合起来创建静态语义映射。对牛津和TUM RGB-D数据集的评估结果表明,他们的方法在提高定位精度和使用大量数据创建语义地图方面是有效的。然而,他们的系统在走廊或信息较少的地方可能会遇到问题。
[82] S. Yang, C. Zhao, Z. Wu, Y. Wang, G. Wang, and D. Li, “Visual slam based on semantic segmentation and geometric constraints for dynamic indoor environments,” IEEE Access, vol. 10, pp. 69 636–69 649, 2022.
2)深度学习解决方案:
在Li等人[83]的另一项名为DXSLAM10的工作中,深度学习被用于寻找类似于SuperPoints的关键点,并生成通用描述符和图像关键点。他们训练尖端的深度CNN高频网,通过从每一帧提取局部和全局信息,生成基于帧和关键点的描述。他们还使用离线词袋(BoW)方法来训练具有局部特征的视觉词汇,以进行精确的闭环识别。DXSLAM在不使用图形处理器(GPU)的情况下实时运行,并且与现代cpu兼容。即使没有特别处理这些特性,它也具有在动态上下文中抵抗动态变化的强大能力。DXSLAM已经在TUM RGB-D和openlris - scene数据集以及室内和室外图像上进行了测试,可以获得比ORBSLAM 2.0和DS-SLAM更精确的结果。然而,这种方法的主要缺点是特征提取的体系结构复杂,并将深层特征合并到旧的SLAM框架中。
[83] D. Li, X. Shi, Q. Long, S. Liu, W. Yang, F. Wang, Q. Wei, and F. Qiao, “Dxslam: A robust and efficient visual slam system with deep features,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 4958–4965.
Li等人[84]开发了一种实时VSLAM技术,用于在复杂情况下基于深度学习提取特征点。该方法可以运行在GPU上,支持创建3D密集地图,是一个具有自监督功能的多任务CNN特征提取。CNN输出是固定长度为256的二进制码字符串,这使得它可以被更传统的特征点检测器(如ORB)所取代。它包含三个线程,用于在动态场景中实现可靠和及时的性能:跟踪、本地映射和循环关闭。该系统支持单目和RGB-D相机,使用ORBSLAM 2.0作为基线。作者在TUM数据集上测试了他们的方法,并使用Kinect摄像头在走廊和办公室收集了两个数据集进行实验。
[84] G. Li, L. Yu, and S. Fei, “A deep-learning real-time visual slam system based on multi-task feature extraction network and self-supervised feature points,” Measurement, vol. 168, p. 108403, 2021.
Steenbeek和Nex在[85]中提出了一种使用CNN进行精确场景解释和地图重建的实时VSLAM技术。他们的解决方案利用飞行过程中来自UA V的单目摄像头流,并使用深度估计神经网络以获得可靠的性能。该方法基于ORB-SLAM 2.0,利用从室内环境中收集到的视觉线索。此外,CNN还接受了超过48000个室内样本的训练,并操作姿势、空间深度和RGB输入来估计规模和深度。TUM RGB-D数据集和使用无人机进行的真实测试用于评估该系统,表明该系统增强了姿态估计精度。然而,系统在没有纹理的情况下挣扎,需要CPU和GPU资源的实时性能。
[85] A. Steenbeek and F. Nex, “Cnn-based dense monocular visual slam for real-time uav exploration in emergency conditions,” Drones, vol. 6, no. 3, p. 79, 2022.
3)使用人工地标:
4)设置范围广:
另一种用于动态室内外情况的VSLAM策略是DMS-SLAM[87],它支持单目、立体和RGB-D视觉传感器。该系统采用滑动窗口和基于网格的运动统计(GMS)[88]特征匹配方法来查找静态特征位置。DMS-SLAM以ORB- slam 2.0系统为基础,跟踪ORB算法识别的静态特征。作者在TUM RGB-D和KITTI数据集上测试了他们提出的方法,并优于前沿的VSLAM算法。此外,由于动态对象上的特征点在跟踪步骤中被删除,DMS-SLAM比原始的ORB-SLAM 2.0执行得更快。尽管所描述的好处,建议的解决方案在纹理少、快速运动和高动态环境的情况下遇到困难。
[87] G. Liu, W. Zeng, B. Feng, and F. Xu, “Dms-slam: A general visual slam system for dynamic scenes with multiple sensors,” Sensors, vol. 19, no. 17, p. 3714, 2019.
[88] J. Bian, W.-Y. Lin, Y. Matsushita, S.-K. Yeung, T.-D. Nguyen, and M.-M. Cheng, “Gms: Grid-based motion statistics for fast, ultra-robust feature correspondence,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4181–4190.
D.目标四:资源约束
在另一个类别中,与其他标准设备相比,一些VSLAM方法是为计算资源有限的设备构建的。例如,为移动设备和带有嵌入式系统的机器人设计的VSLAM系统就包括在这个类别中。
1)处理能力有限的设备
在这方面,edgeSLAM是Xu等人[89]提出的一种针对移动和资源受限设备的实时、边缘辅助语义VSLAM系统。它采用一系列细粒度模块供边缘服务器和相关移动设备使用,而不需要重载线程。edgeSLAM还包含了基于Mask-RCNN技术的语义分割模块,以改进分割和对象跟踪。作者将他们的策略付诸实践,在一个边缘服务器上使用几种商业移动设备,如手机和开发板。通过重用对象分割的结果,他们通过调整系统参数以适应不同的网络带宽和延迟情况,避免了重复处理。EdgeSLAM已经在TUM RGB-D、KITTI和创建的实验设置数据集的单目视觉实例上进行了评估。[89] J. Xu, H. Cao, D. Li, K. Huang, C. Qian, L. Shangguan, and Z. Yang, “Edge assisted mobile semantic visual slam,” in IEEE INFOCOM 2020-IEEE Conference on Computer Communications. IEEE, 2020, pp. 1828–1837.
对于立体相机设置,Schlegel, Colosi和Grisetti[90]建议使用名为ProSLAM12的轻量级基于功能的VSLAM框架,该框架可以达到与尖端技术相当的效果。四个模块组成了他们的方法:三角测量模块,创建3D点和相关的特征描述符;增量运动估计模块,处理两帧以确定当前位置;地图管理模块,用于创建本地地图;以及重新定位模块,它根据本地地图的相似性更新世界地图。ProSLAM使用单个线程检索点的3D位置,并利用少量众所周知的库创建一个易于创建的系统。在KITTI和EuRoC数据集上的实验表明,该方法能取得较好的鲁棒性。然而,它在旋转估计方面显示出弱点,并且不包含任何束调整模块。
[90] D. Schlegel, M. Colosi, and G. Grisetti, “Proslam: Graph slam from a programmer’s perspective,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 3833–3840.
Bavle等人[91]提出了VPS-SLAM 13,一种用于航空机器人的基于图的轻型VSLAM框架。他们的实时系统集成了几何数据、几种目标检测技术和视觉/视觉惯性里程计,用于姿态估计和构建环境的语义地图。VPS-SLAM利用底层特征、IMU测量和高层平面信息重构稀疏语义映射并预测机器人状态。该系统利用在COCO数据集[93]上训练的you Only Look Once v2.0 (YOLO2)[92]的轻量级版本进行对象检测,因为其实时和计算有效的性能。他们使用了一个手持相机设置和一个装有RGB-D相机的空中机器人平台进行测试。TUM RGB-D数据集的室内实例被用于测试他们的方法,他们能够提供与著名的VSLAM方法相同的结果。然而,他们的VSLAM系统只能使用少量的对象(如椅子、书籍和笔记本电脑)来构建周围区域的语义地图。
[91] H. Bavle, P. De La Puente, J. P. How, and P. Campoy, “Vps-slam: Visual planar semantic slam for aerial robotic systems,” IEEE Access, vol. 8, pp. 60 704–60 718, 2020.
[92] J. Redmon and A. Farhadi, “Yolo9000: better, faster, stronger,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7263–7271.
Tseng等人[94]提出了另一种实时室内VSLAM方法,该方法需要低成本的设置。作者还提出了一种估计帧数和视觉元素所需的合理程度的定位精度的技术。他们的解决方案基于OpenVSLAM[95]框架,并将其用于现实世界中出现的紧急情况,例如访问特定目标。该系统采用高效透视点(EPnP)和RANSAC算法获取场景的特征图,用于精确的姿态估计。根据在一栋建筑中进行的测试,他们的设备可以在恶劣的照明条件下提供准确的结果。
[94] P.-Y. Tseng, J. J. Lin, Y.-C. Chan, and A. Y. Chen, “Real-time indoor localization with visual slam for in-building emergency response,” Automation in Construction, vol. 140, p. 104319, 2022.
[95] S. Sumikura, M. Shibuya, and K. Sakurada, “Openvslam: a versatile visual slam framework,” in Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 2292–2295.
2)计算卸载:
Ben Ali等[96]建议使用边缘计算,将资源密集型操作卸载到云端,减少机器人的计算负担。他们在他们的间接框架edge - slam14中修改了ORB-SLAM 2.0的架构,通过维护机器人上的跟踪模块,并将剩余的任务委派给边缘。通过分割机器人和边缘设备之间的VSLAM管道,系统可以同时维护本地和全局映射。在可用资源较少的情况下,它们仍然可以在不牺牲准确性的情况下正确执行。他们使用TUM的RGB-D数据集和两个不同的移动设备,使用RGB-D相机生成一个定制的室内环境数据集进行评估。然而,他们的方法的缺点之一是由于各种SLAM模块的解耦而导致的体系结构的复杂性。另一个缺点是他们的系统只能在短期内工作,而在长期情况下(例如,多日)使用Edge-SLAM将面临性能下降。
[96] A. J. Ben Ali, Z. S. Hashemifar, and K. Dantu, “Edge-slam: edgeassisted visual simultaneous localization and mapping,” in Proceedings of the 18th International Conference on Mobile Systems, Applications, and Services, 2020, pp. 325–337.
E.目标V:多样化
VSLAM作品在这个类别中主要关注直接的开发、利用、改编和扩展。
在这方面,Sumikura等人[95]介绍了OpenVSLAM15,这是一个适应性很强的开源VSLAM框架,旨在被其他第三方程序快速开发和调用。他们基于特征的方法与多种相机类型兼容,包括单目、立体和RGB-D,并可以存储或重用重构的地图以供以后使用。由于其强大的ORB特征提取模块,OpenVSLAM在跟踪精度和效率方面优于ORB- slam和ORB- slam 2.0。但是,由于担心类似的代码侵犯了ORB-SLAM 2.0的权利,该系统的开源代码已经停止。
[95] S. Sumikura, M. Shibuya, and K. Sakurada, “Openvslam: a versatile visual slam framework,” in Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 2292–2295.
为了弥补实时能力、准确性和弹性之间的差距,Ferrera等人[97]开发了OV2SLAM16,可与单目和立体视觉相机一起工作。通过限制关键帧的特征提取,并通过消除光测量误差在后续帧中监控它们,他们的方法减少了计算负载。在这个意义上,OV2SLAM是一种混合策略,它结合了VSLAM算法的直接和间接类别的优点。在室内和室外实验中,使用包括EuRoC、KITTI和TartanAir在内的知名基准测试数据集,证明了OV2SLAM在性能和准确性方面超过了几种流行的技术。
Teed和Deng[98]提出了这方面的另一种方法,名为DROID-SLAM17,是一种基于深度学习的视觉SLAM,适用于单目、立体和RGB-D相机。与已知的单目和立体跟踪方法相比,该方法具有更高的精度和鲁棒性。他们的解决方案是实时运行的,由后端(用于束调整)和前端(用于关键帧收集和图形优化)线程组成。DROID-SLAM已经用单目摄像机的例子进行了教学,因此它不需要再次训练来使用立体声和RGB-D输入。该方法与间接方法一样,将投影误差最小化,同时不需要对特征识别和匹配进行任何预处理。由下采样层和残差块组成的特征提取网络对每个输入图像进行处理,生成密集的特征。DROID-SLAM已经在TartanAir、EuRoC和TUM RGB-D等知名数据集上进行了测试,可以获得可接受的结果。
[97] M. Ferrera, A. Eudes, J. Moras, M. Sanfourche, and G. Le Besnerais, “Ov2slam: A fully online and versatile visual slam for real-time applications,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 1399–1406, 2021.
Bonetto等人在[99]中提出了iRotate 18,一种用于配备RGB-D摄像头的全向机器人的主动技术。此外,在他们的方法中使用了一个模块,用于在摄像机的视野区域内发现障碍物。通过提供对以前未探索过的地方和以前去过的地方的观察范围,iRotate的主要目标是缩短机器人在绘制环境地图时必须走的距离。该方法使用一个VSLAM框架,后端是图形特征。通过在仿真和真实三轮全向机器人上的比较,作者可以获得与前沿VSLAM方法相同的结果。然而,他们的方法的主要缺点是,机器人可能会面临起停情况下,本地路径被重新规划。
[99] E. Bonetto, P. Goldschmid, M. Pabst, M. J. Black, and A. Ahmad, “irotate: Active visual slam for omnidirectional robots,” Robotics and Autonomous Systems, vol. 154, p. 104102, 2022.
F. 目的VI:视觉里程计
这类方法旨在以尽可能高的精度确定机器人的位置和方向。
1)深度神经网络(Deep Neural Networks):在这方面,文献[100]提出了Dynamic-SLAM框架,利用深度学习实现精确的姿态预测和合适的环境理解。作为优化VO的语义级模块的一部分,作者使用CNN来识别环境中的运动目标,这有助于降低由于不恰当的特征匹配带来的姿态估计误差。此外,dynamic - slam使用一个选择性跟踪模块来忽略场景中的动态位置,并在相邻帧中使用一个错过的特征校正算法来实现速度不变性。尽管取得了良好的结果,但该系统需要巨大的计算成本,并且由于定义的语义类数量有限,面临着对动态/静态对象进行错误分类的风险。
Bloesch等人[101]提出了Code-SLAM19直接技术,该技术提供了场景几何图形的浓缩和密集表示。他们的VSLAM系统只与单目相机一起工作,是PTAM[14]的增强版本。他们将强度图像划分为卷积特征,并将它们输入深度自动编码器,使用的是经过SceneNet RGB-D数据集强度图像训练的CNN。EuRoC数据集的室内示例已用于测试Code-SLAM,结果在准确性和性能方面很有希望。
[101] M. Bloesch, J. Czarnowski, R. Clark, S. Leutenegger, and A. J. Davison, “Codeslam—learning a compact, optimisable representation for dense visual slam,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2560–2568.
Wang等人[102]提出了一种端到端VO框架,使用深度循环卷积神经网络(Deep recursive Convolutional Neural Network, RCNN)架构进行单目设置。他们的方法使用深度学习自动学习适当的特征,建模顺序动态和关系,并直接从颜色帧推断姿势。DeepVO架构包括一个名为FlowNet的CNN,用于计算连续帧的光流,以及两个Long - term Memory (LSTM)层,用于根据CNN提供的提要估计时间变化。该框架结合CNN和循环神经网络(RNN),可以同时提取视觉特征并进行顺序建模。DeepVO可以将几何图形与学习到的知识模型结合起来,实现增强的VO。然而,它不能取代传统的基于几何的VO方法。
[102] S. Wang, R. Clark, H. Wen, and N. Trigoni, “Deepvo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks,” in 2017 IEEE international conference on robotics and automation (ICRA). IEEE, 2017, pp. 2043–2050.
Parisotto等人[103]提出了一种类似deepvo的端到端系统,使用神经图优化(NGO)步骤代替lstm。他们的方法是基于时间上不同的姿态操作闭环检测和校正机制。NGO采用两种注意优化方法,联合优化局部位姿估计模块的卷积层聚合预测,实现全局位姿估计。他们在2D和3D迷宫中试验了他们的技术,并超越了DeepVO的性能和准确性水平。上述方法需要连接到SLAM框架以提供重新定位信号。
[103] E. Parisotto, D. Singh Chaplot, J. Zhang, and R. Salakhutdinov, “Global pose estimation with an attention-based recurrent network,” in Proceedings of the ieee conference on computer vision and pattern recognition workshops, 2018, pp. 237–246.
在另一项工作中,Czarnowski等人[104]介绍了最广泛的VSLAM框架之一DeepFactors21,用于用单目摄像机密集重建环境地图。为了更可靠的地图重建,他们的实时解决方案执行姿态和深度的联合优化,利用概率数据,并结合学习和基于模型的方法。作者修改了CodeSLAM框架,并添加了缺失的组件,如本地/全局循环检测。在对大约140万张ScanNet[105]图像进行训练后,该系统在ICL-NUIM和TUM RGB-D数据集上进行评估。DeepFactors改进了CodeSLAM框架的思想,并专注于传统SLAM管道中的代码优化。但是,由于模块的计算成本,这种方法需要使用gpu来保证实时性。
[104] J. Czarnowski, T. Laidlow, R. Clark, and A. J. Davison, “Deepfactors: Real-time probabilistic dense monocular slam,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 721–728, 2020.
[105] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5828–5839.
**2)邻框深度处理:**在另一项工作中,通过减少用于相机运动检测的两张照片之间的光度和几何误差,[106]22的作者为RGB-D相机开发了一种实时密集SLAM方法,改进了他们的先验方法[107]。他们基于关键帧的解决方案扩展了Pose SLAM[108],该方案仅保留非冗余的姿势以生成紧凑的地图,增加了密集的视觉测程特征,并有效利用来自相机帧的信息进行可靠的相机运动估计。作者还使用基于熵的技术来测量关键帧的相似性,用于闭环检测和漂移避免。然而,他们的方法仍然需要在闭环检测和关键帧选择质量方面的工作。
[106] C. Kerl, J. Sturm, and D. Cremers, “Dense visual slam for rgb-d cameras,” in 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2013, pp. 2100–2106.
[107] ——, “Robust odometry estimation for rgb-d cameras,” in 2013 IEEE international conference on robotics and automation, 2013, pp. 3748– 3754.
[108] V. Ila, J. M. Porta, and J. Andrade-Cetto, “Information-based compact pose slam,” IEEE Transactions on Robotics, vol. 26, no. 1, pp. 78–93, 2009.
在Li等人[109]介绍的另一项工作中,实时动态对象删除使用基于特征的VSLAM方法,即DP-SLAM。该方法使用贝叶斯概率传播模型,基于从运动物体中得到的关键点的似然性。DP-SLAM利用移动概率传播算法和迭代概率更新,可以克服几何限制和语义数据的变化。它集成了ORB-SLAM 2.0,并已在TUM RGB-D数据集上进行了测试。尽管得到了准确的结果,但由于迭代概率更新模块的存在,该系统只能在稀疏的vslam环境下工作,计算成本较高。
[109] A. Li, J. Wang, M. Xu, and Z. Chen, “Dp-slam: A visual slam with moving probability towards dynamic environments,” Information Sciences, vol. 556, pp. 128–142, 2021.
Dong等人[110]建议的室内导航系统成对导航(Pair-Navi)重用一个代理先前跟踪的路径,以供其他代理将来使用。因此,被称为leader的前一个旅行者捕获跟踪信息,如转弯和特定的环境质量,并将其提供给需要前往相同目的地的后一个跟随者。跟随器使用一个重新定位模块来确定它与参考轨迹相关的位置,而引导器集成了视觉里程计和轨迹创建模块。为了从视频特征集中识别和删除动态项,该系统采用了基于掩码区域的CNN (Mask R-CNN)。他们在一组生成的数据集和几部智能手机上测试了Pair-Navi。
[110] E. Dong, J. Xu, C. Wu, Y. Liu, and Z. Yang, “Pair-navi: Peer-to-peer indoor navigation with mobile visual slam,” in IEEE INFOCOM 2019- IEEE Conference on Computer Communications. IEEE, 2019, pp. 1189–1197.
**3)各种特性加工:**这方面的另一种方法是Li等人[111]提出的基于文本的VSLAM系统TextSLAM。它将使用FAST角检测技术从场景中检索的文本项目合并到SLAM管道中。文本包含各种纹理、模式和语义,使得该方法更有效地使用它们创建高质量的3D文本地图。TextSLAM使用文本作为可靠的视觉基准标记,在找到文本的第一帧之后对其进行参数化,然后将3D文本对象投射到目标图像上再次定位。他们还提出了一种新的三变量参数化技术,用于初始化瞬时文本特征。使用单目相机和作者创建的数据集,在室内和室外环境中进行了实验,结果非常准确。在没有文本的环境中操作、处理短的字母和需要大量文本字典的存储是TextSLAM的三个基本挑战。
[111] B. Li, D. Zou, D. Sartori, L. Pei, and W. Yu, “Textslam: Visual slam with planar text features,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 2102–2108.
Xu等人[43]提出了一种间接的VSLAM系统,建立在改进的ORB-SLAM基础上,使用占用网格映射(OGM)方法和新的2D映射模块实现高精度定位和用户交互。他们的系统可以利用OGM重构环境地图,将障碍物的存在显示为等间距的变量场,使得在规划路线时连续实时导航成为可能。对生成数据集的实验检验显示了它们在gps拒绝条件下的逼近函数。然而,他们的技术难以在动态和复杂的环境中很好地发挥作用,在走廊和无特征的条件下难以适当地匹配特征。
[43] L. Xu, C. Feng, V. R. Kamat, and C. C. Menassa, “An occupancy grid mapping enhanced visual slam for real-time locating applications in indoor gps-denied environments,” Automation in Construction, vol. 104, pp. 230–245, 2019.
CPA-SLAM是Ma等人[112]提出的一种针对RGB-D相机的直接VSLAM方法,利用平面进行跟踪和图形优化。帧到关键帧和帧到平面的对齐规律地集成在他们的技术中。他们还介绍了一种针对参考关键帧跟踪摄像机并将图像与平面对齐的图像对齐算法。CPA-SLAM使用关键帧数据,寻找最近的短时间和地理距离进行跟踪。他们的跟踪系统的实时性能在有平面和无平面设置下进行了测试,并对TUM RGB-D和ICL-NUIM数据集进行了室内和室外场景分析。然而,它只支持少量的几何形状,即平面。
[112] L. Ma, C. Kerl, J. St¨uckler, and D. Cremers, “Cpa-slam: Consistent plane-model alignment for direct rgb-d slam,” in 2016 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2016, pp. 1285–1291.
明确当前的趋势
A. 统计数据

图4。分析VSLAM方法的当前趋势:a)用于实现新方法的基础SLAM系统,b)该方法的主要目标,c)拟议方法所测试的各种数据集,d)在拟议方法中利用语义数据的影响,e)环境中存在的动态对象的数量,f)系统所测试的各种类型的环境。
我们可以看到大多数被提议的VSLAM系统都是独立的应用程序,它们从头开始使用视觉传感器实现定位和映射的整个过程。虽然ORB-SLAM 2.0和ORB-SLAM是用于创建新框架的其他基础平台,但最小的方法是基于其他VSLAM系统,如PTAM和PoseSLAM。此外,就VSLAM应用的目标而言,子图“b”中排名第一的是改进Visual Odometry模块。因此,目前大多数vslam都试图解决现有算法在确定机器人位置和方向方面的问题。姿态估计和现实世界可行性是提出新的VSLAM论文的进一步基本目标。关于被调查论文中用于评价的数据集,子图“c”表明,大多数工作都在TUM RGB-D数据集上进行了测试。该数据集在审稿中被用作评价的主要基线或多个基线之一。此外,许多研究人员倾向于在它们生成的数据集上进行实验。我们可以假设生成数据集的主要动机是展示VSLAM方法如何在现实场景中工作,以及它是否可以用作端到端应用程序。EuRoC MA V和KITTI分别是VSLAM工作中比较受欢迎的评价数据集。从子图“d”中提取的另一个有趣的信息是关于使用VSLAM系统时使用语义数据的影响。我们可以看到,大多数评论的论文在处理环境时不包括语义数据。
当考虑到环境时,我们可以在子图“e”中看到,超过一半的方法也可以在具有挑战性条件的动态环境中工作,而其余的系统只关注没有动态变化的环境。此外,在子图“f”中,大多数方法都适用于“室内环境”或“室内和室外环境都适用”,而其余的论文只在室外条件下进行了测试。应该提到的是,只有在限制假设的特定情况下才能起作用的方法,如果在其他情况下使用,可能不会产生同样的准确性。这就是为什么有些方法只专注于某一特定情况的主要原因之一。
B.分析当前趋势
许多高潜力领域和未解决的问题,这些问题的研究将导致未来slam系统的发展有更强大的方法。
深度学习:深度神经网络在包括VSLAM[15]在内的各种应用中显示出令人鼓舞的结果,使其成为多个研究领域的重要趋势。由于它们的学习能力,这些体系结构显示出相当大的潜力,可以作为可靠的特征提取器来解决VO和环路关闭检测中的不同问题。cnn可以帮助vslam进行精确的目标检测和语义分割,并在正确识别手工制作的特征方面优于传统的特征提取和匹配算法。必须指出的是,由于基于深度学习的方法是在数据集上训练的,而数据集的数据种类繁多,对象类别有限,因此总是存在动态点分类错误,导致错误分割的风险。因此,它可能导致较低的分割精度和姿态估计误差。
信息检索和计算成本的权衡:通常情况下,处理成本和场景中信息的数量应该始终保持平衡。从这个角度来看,密集的地图允许VSLAM应用程序记录高维的完整场景信息,但实时这样做将需要大量的计算。另一方面,稀疏表示由于其较低的计算成本而无法捕获所有所需的信息。还应该注意的是,实时性能与相机的帧率直接相关,峰值处理时间的帧丢失会对VSLAM系统的性能产生负面影响,而不管算法性能如何。此外,vslam通常利用紧密耦合的模块,修改一个模块可能会对其他模块产生不利影响,这使得平衡任务更具挑战性。
语义分割:在创建环境地图的同时提供语义信息可以为机器人带来非常有用的信息。识别摄像机视场中的物体,如门、窗、人等,是当前和未来VSLAM工作中的一个热门话题,因为语义信息可以用于姿态估计、轨迹规划和环路闭合检测模块。随着对象检测和跟踪算法的广泛使用,语义vslam无疑将是该领域未来的解决方案之一。
闭环算法:SLAM系统的关键问题之一是定位误差累积导致的漂移问题和特征轨迹丢失问题。在VSLAM系统中,通过检测漂移和闭环来识别以前访问过的地方会导致较高的计算延迟和成本[89]。主要原因是闭环检测的复杂度随着重构映射的大小而增加。此外,结合从不同地点收集的地图数据并细化估计的姿态是非常复杂的任务。这样,闭环检测模块的优化和平衡就有了巨大的改进潜力。检测环路闭包的常用方法之一是通过训练基于局部特征的视觉词汇表,然后聚合它们来改进图像检索。
[89] J. Xu, H. Cao, D. Li, K. Huang, C. Qian, L. Shangguan, and Z. Yang, “Edge assisted mobile semantic visual slam,” in IEEE INFOCOM 2020-IEEE Conference on Computer Communications. IEEE, 2020, pp. 1828–1837.
在具有挑战性的场景下工作:在无纹理的环境中工作,很少有显著的特征点,经常导致机器人的位置和方向漂移误差。作为VSLAM的主要挑战之一,这个错误可能会导致系统故障。因此,在基于特征的方法中考虑互补的场景理解方法,如目标检测或线特征,将是一个时髦的话题。