论文笔记:主干网络——GoogLeNet
Going Deeper with Convolutions
更深的卷积神经网络
目录
- Going Deeper with Convolutions
- 更深的卷积神经网络
-
- 论文结构
- 一、GoogLeNet结构
-
- ①Inception模块(论文中的4)
- ②GoogLeNet结构(论文的5)
- 二、训练技巧(论文的6)
-
- ①辅助损失
- ②学习率下降策略(论文的6第一段)
- ③数据增强(论文的6第二段)
- 三、测试技巧(论文的7)
-
- ① multi crop (1张-->144张)
- ② Model Fusion 模型融合
- 四、实验结果及分析
- 五、稀疏结构(论文中的3)
- 六、论文总结
-
- ①关键点、创新点
- ② 备用参考文献知识点:
论文结构
摘要: 介绍背景,Inception高效率、多尺度,成就
1. introduction: 介绍CNN的成功,商用要求少量参数,借鉴了NIN
2. Related Work: 借鉴了NIN的1×1卷积,2007年论文的多尺度滤波器
3. The Motivation and High Level Considerations: 提出Inception动机分析
4. Architectural Details: Inception结构详解及变化
5. GoogLeNet: 参赛的模型——22层卷积网络模型结构
6. Trainning Methodology: 训练设置,超参数,数据增强技巧
7. ILSVRC 2014Classification: 分类任务中的设置及结果
8. ILSVRC 2014 Deteciton: 目标检测任务中的设置及结果
9. Conclusions: 总结Inception结构的特点
10. Acknowlegements: 致谢
一、GoogLeNet结构
①Inception模块(论文中的4)
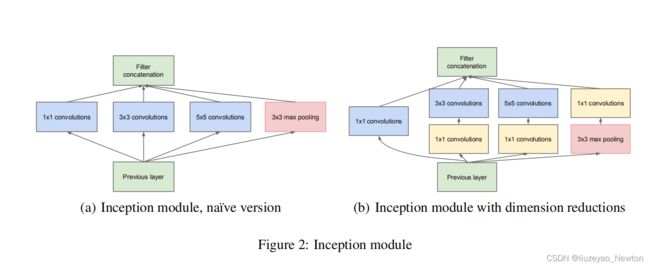
特点:
(1)多尺度处理,使用不同的卷积核提取特征。
(2)1×1卷积降维
(3)卷积和池化一起用上,用比较少的计算量,得到比较多的特征图
从左图到右图的改进:使用1×1卷积降维
原因:
(1)因为3×3池化可以让特征通道数增加,把特征图完全保留下来了,数据量激增。所以池化层用1×1卷积来处理。
(2)计算量太大,3×3conv和5×5conv的通道数多,所以使用1×1卷积,根据卷积核的个数,压缩卷积核厚度。
②GoogLeNet结构(论文的5)
(1)三阶段
第一阶段:conv-pool-conv-pool
快速降低分辨率,降低倍数是步长的立方。因为feature map太大不利于做Inception操作
第二阶段:堆叠使用9个Inception
第三阶段:FC层分类输出。
(2)堆叠使用Inception module,22层
(3)增加两个辅助损失,缓解梯度消失。
辅助分类输出:中间层特征具有分类能力,得到1个1000维的向量,与标签对比,得到loss值,再梯度反向传播,使前面网络层梯度有所增加。
(4)参数设置
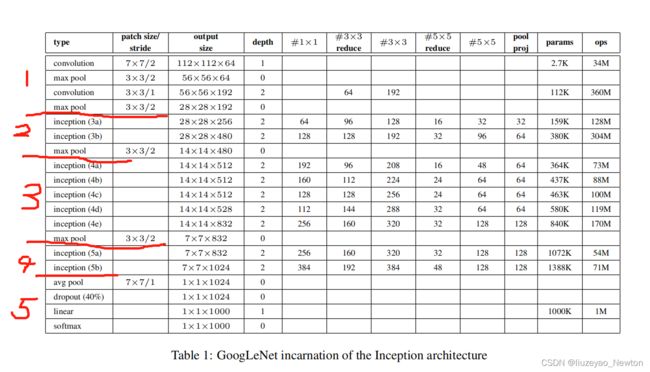
【数据流计算】:
输入像素为224×224×3,
经过五个block、5次分辨率下降:
经过第一个阶段,变为28×28×192,
经过第二个阶段:
堆叠两个Inception,池化后,降低分辨率为14×14×480,
再堆叠5个Inception,池化后,降低分辨率为7×7×832,
在堆叠2个Inception,得到7×7×1024,
经过第三阶段:
平均池化-dropout-linear-softmax后,输出1×1×1000,1000个分类
【输出时的特点】:
没有堆叠使用多个FC层,只用了1个FC层实现模型的迁移、学习。直接改变最后一个linear层神经元个数,就可以实现,把GoogLeNet应用到不同任务中。
二、训练技巧(论文的6)
①辅助损失
增加了两个辅助分类层(Inception(4d、4e)),计算辅助损失。
作用:
(1)增加loss回传
(2)充当正则约束,使中间层特征也具备一定的分类能力。
②学习率下降策略(论文的6第一段)
每8个epoch下降4%,可以使 loss 和 accuracy曲线比较平滑。
③数据增强(论文的6第二段)
(1)图像尺寸均匀分布在8%-100%之间
(2)长宽比在 [3/4,4/3] 之间
(3)光度畸变可以减轻过拟合
三、测试技巧(论文的7)
① multi crop (1张–>144张)
step 1: 等比例缩放短边至256、288、320、352
step 2: 长边裁剪出3个正方形(左中右 / 上中下)
step 3: 每个正方形进行左上、左下、右上、右下、中心、全局resize
step 4: 水平镜像
4×3×6×2 = 144
② Model Fusion 模型融合
7模型融合,在权重初始化和学习率相同时,仅在采样方式、顺序上有所差异。
融合的模型要有差异,差异来自训练时设置的不同的超参数,或一系列样本的不同,来实现样本融合的模型具备不一样的表现能力。
四、实验结果及分析
(1)分类:
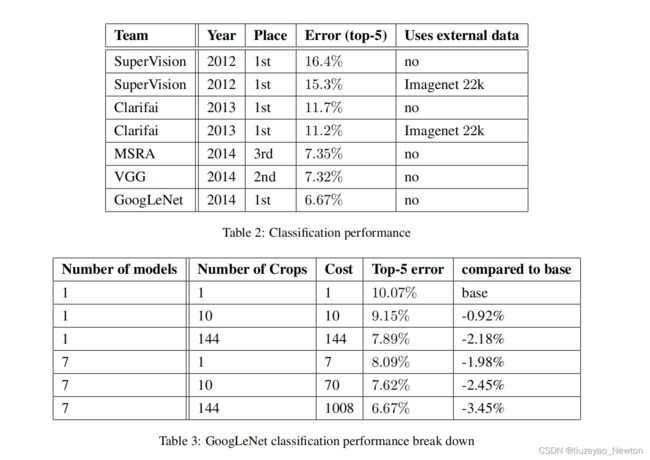
模型融合:多模型比单模型精度高;
multi crop:crop越多,精度越高
(2)检测:
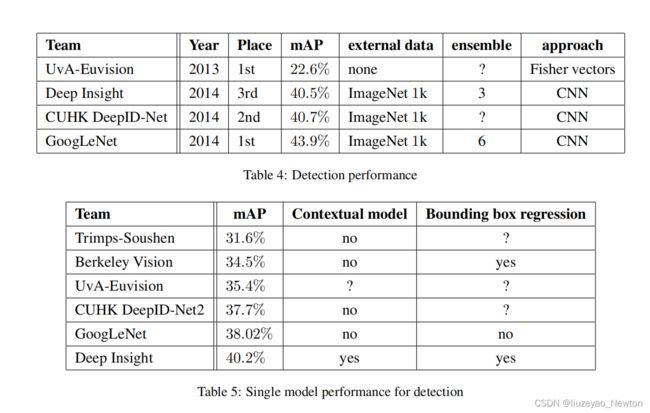
与RCNN类似,
结合selective search 和 multi-box
五、稀疏结构(论文中的3)
稀疏矩阵 可以分解为密集矩阵计算,加快收敛速度。
同时可以打破均匀分布,相关性强的特征聚集在一起。
六、论文总结
①关键点、创新点
(1)大量使用1×1,可以降低维度,减少计算量,参数是AlexNet的1/12
(2)多尺度卷积核,实现多尺度特征提取
(3)辅助损失层,增加梯度回传,增加正则,减轻过拟合
② 备用参考文献知识点:
(1)随机采用差值方法可以提升性能。
we started to use random interpolation methods (bilinear, area, nearest neighbor and cubic, with equal probability) for resizing relatively late and in conjunction with other hyperparameter changes.(论文6的第二段)
(2)为了节省内存消耗,先将分辨率降低,再堆叠使用Inception module。
For technical reasons (memory efficiency during training), it seemed beneficial to start using Inception modules only at higher layers while keeping the lower layers in traditional convolutional fashion. (论文4的第五段)
(3)增加模型深度和宽度,可以提升性能,但是有两个缺点:容易过拟合,计算量过大。
The most straightforward way of improving the performance of deep neural networks is by increasing their size.
Bigger size typically means a larger number of parameters, which makes the enlarged network more prone to overfitting,
Another drawback of uniformly increased network size is the dramatically increased use of computational resources. (论文3的前三段首句)
(4)最后一个全连接层,为了更方便的微调,迁移学习。
we use an extra linear layer. This enables
adapting and fine-tuning our networks for other label sets easily.(论文5的第三段)