2022:Transformer Decoders with MultiModal Regularization for Cross-Modal Food Retrieval
摘要
近些年跨模态图像-配方检索得到了广泛的关注。我们提出一种新的检索框架,T-Food(用于跨模态食物检索的多模态正则化的Transformer解码器),使用一种新的正则化方案利用模态间的交互作用,在测试时只使用单模态编码器用于高效检索。我们还利用专门的配方编码器捕获配方实体间的内部依赖,并提出一种具有动态边缘的三重损失的变体,以适应任务的难度。最后,我们利用最近的VLP模型的力量用于图像编码器,如CLIP。
一、介绍
本工作关注配方-图像检索,包括检索给定配方对应的图像,反之亦然。我们提出一种基于新的架构和学习框架的跨模态配方检索的新策略。由于配方实体是高度相关的,我们提出一种显式地利用实体内部和实体之间的依赖性的一种层次化的transformer。对于视觉编码器,我们考虑视觉transformer如ViT,也考虑了最近的模型如在大的多模态数据集上预训练好的CLIP-ViT,我们期待后者能够对在Recipe1M中的噪声更具鲁棒性。
为了实现高效的大规模检索,我们利用双编码器,但我们在训练期间考虑一个更复杂的图像-配方交互,我们通过一个新的transformer基本模块与作为一种正则化的图像-文本匹配损失来实现,以更好的对齐编码器表示。我们也提出一种新的可适应的损失,具有一个动态边缘,根据任务的难度而变化。整体结构与学习方案如图1所示。
我们的贡献如下:1)深的结构设计:(a)我们提出一种具有transformer解码器的新的配方编码器,捕获配方实体间的交互,(b)我们利用在大规模数据集上训练好的VLP模型用作图像编码器,(c)我们用由模态内连接的transformer组成的一个多模态块组成这种结构,尤其为训练设计。我们在测试时只保留单模态编码器,以用于高效的跨模态检索。2)训练框架:(a)我们提出一种新的多模态正则化,在多模态模块顶部包含一个图像-文本匹配损失,(b)我们引入一种具有动态边缘的新的可适应三重损失,以适应任务的难度。

二、相关工作
2.1 多模态学习
双编码器,如CLIP和ALIGN,对每个模态使用分开的编码器,并使用一个对比损失来对齐模态。这些模型在推理期间是高效的,然而,它们在大量的数据上训练,依赖全局相似性,没有利用细粒度的模态交互。
另一方面,多模态编码器利用一个重的transformer,获取两个模态的标记,依赖几个预训练任务如掩码语言建模、图像-文本匹配、掩码图像建模或prefixLM。尽管在视觉-语言任务上取得了成功,但由于自注意力和模态间的交叉注意力,它们存在计算复杂度,限制对大规模任务的适应性。为了使这些模型在推理过程中更有效,一些工作在使用双编码器[30,41]进行第一次排序后,采用对前k个例子进行重新排序。尽管这些方法在跨模态检索方面取得了成功,但该模型的大规模检索效率仍然是一个瓶颈。
2.2 对比学习
三、T-Food框架
首先,每个模态被分别编码为两个标记嵌入序列,这两个序列以不同的方式被使用:(1)我们在测试时提取两个固定尺寸的嵌入用于检索,并在训练时与一个三重损失更接近。(2)我们将这两个序列送入多模态正则化(MMR)模块,计算一个细粒度的对齐分数(图像-文本匹配损失)。
3.1 双编码器(DE)
图像编码器 我们使用一个视觉transformer(如ViT B/16)作为一个图像编码器,此外,在下游任务上微调大的视觉/语言模型被证明是一个有效的策略,因此,我们提出微调在大规模数据集上训练过的CLIP ViT B/16。图像编码器Ei将一个输入图像I编码为一个图像标记序列和一个[CLS]标记输出,被线性投影形成一个固定尺寸的图像嵌入eI。
配方编码器 不同于其它使用循环网络和预训练嵌入的工作,我们遵循[47]使用层次化的transformer编码配方为原始文本,如图2。
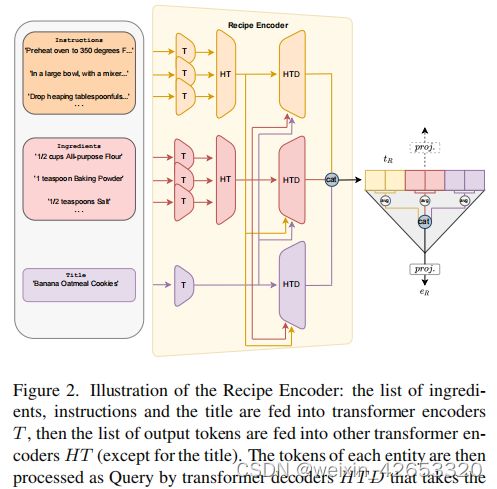
3.2 多模态正则化(MMR)
我们提出一种多模态正则化,包含transformer解码器和一个图像-文本匹配损失(ITM),以进一步在对齐过程期间引导双编码器(图3)。多模态编码器旨只在训练期间使用。与其它的表示学习方法相比,如自监督学习,其中一个简单的投影层被添加到特征表示的顶部以计算对比损失。在这里,投影层通过一个更复杂的多模态模块替代,且对比损失被ITM替代。

MMR的主要块包括一个特别使用交叉注意力的transformer解码器:查询(Q)来自一个模态,而键(K)和值(V)来自另一个模态。换句话说,查询通过考虑两个模态间的依赖更新。具体地,Q的每个向量通过另一个模态的KV向量的加权和更新的,其中每个权值是每个KV向量与底层Q向量的相似性。我们使用transformer解码器的选择是基于它们的计算效率。此外,我们选择配方标记作为查询,因为配方标记的数量远少于图像标记的数量,这减少了复杂度。
MMR模块包含内部连接的transformers、一个图像标记增强模块(ITEM)来增强图像标记,接下来是一个多模态transformer解码器(MTD):
图像标记增强模块(ITEM) 在进入MTD之前增强图像标记,通过增加一个transformer解码器将图像标记作为查询(Q)和配方标记作为键和值(KV):
![]()
这个模块通过添加配方元素丰富了图像标记。虽然只使用这些成分似乎是很自然的,因为它们存在于图像的不同区域/令牌中,但我们发现其他配方元素,即使它们没有在图像中明确呈现,也会带来额外的改进(见补充材料)。
多模态transformer解码器(MTD) 提出一个多模态transformer解码器(MTD)预测每对样本的匹配分数。我们认为这个预测的匹配分数更好地捕获了两个模态间的相互作用,与独立地提取的嵌入之间应用全局余弦相似性相比。MTD包含自注意力、交叉注意力和反馈模块。对于交叉注意力,一个模态的标记被考虑为查询(Q)和另一模态的标记作为键和值(KV)。一对样本的匹配分数可以通过以下方式获取:

图像-文本匹配(ITM)损失: ITM是一种二值交叉熵损失,被优化为分类一个图像-文本对是否匹配。在对三重损失进行批硬挖掘的成功后,将损失应用来最难的负样本中;对于每个配方/图像锚点,我们使用DE输出的嵌入的快速余弦相似度,在批中采样与锚点最相似的负配方/图像。损失可以被如下表示:

3.3 检索损失
我们在我们的学习框架中使用三重损失。我们引入一种具有动态边缘的三重损失的变体。
三重损失:
![]()
其中xa、xp和xn是锚点、正和负样本,α是一个边缘,d(·,·)是一个距离函数。
IncMargin损失: 受课程学习方法[3]的启发,随着训练的进行,任务变得更加困难,我们建议用一个动态的边际来取代恒定的边际。其理念是,任务的难度也会受到边际的影响;小边际比大边际更容易优化。这里我们假设任务在一开始是困难的,因此我们从一个小的边际αinc开始,并在每个时期增加它,直到达到最大值,从而使它更简单:
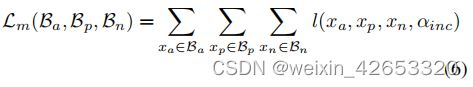
我们在一个可接受的最小值和最大值之间保持自适应边际。此外,我们遵循Adamine[6],并使用自适应加权策略使用三联体损失,其中三联体采用与δ相似的术语进行加权,以克服大多数三联体不活跃时的消失更新。我们将实例损失称为图像文本对比损失,它可以写成:
![]()
类似地,我们将Adamine[6]的语义三重态损失作为正则化,以获得更多语义丰富的嵌入。语义损失Lsem与实例损失相同,除了选择正样本和负样本外。这里的正样本是与锚共享相同类别的样本,负样本是具有不同类别的样本。
总损失:
![]()
五、总结
我们提出一种新的烹饪情境下的多模态对齐框架,并在跨模态检索任务上大大超过了所有现有的工作。我们引入一种新的多模态正则化和新的三重损失的变体,此外,我们表明transformer编码器/解码器可以通过利用模态和配方元素间依赖关系带来显著的提升。最终,我们表示在大规模数据集上训练的VLP模型的迁移学习在这种情况下可以显著帮助。虽然这项工作在食品领域取得了成功,但我们认为所提出的想法可以有利于一般的跨模态任务,特别是跨模态检索。