基于PyTorch的深度学习--PyTorch 数据集和数据加载器
本篇文章是翻译:https://deeplizard.com网站中的关于Pytorch学习的文章,供学习使用。
原文地址为:https://deeplizard.com/learn/video/mUueSPmcOBc
基于深度学习的PyTorch数据集和数据加载器
欢迎回到基于PyTorch的神经网络系列课程,在这一部分,我们将了解到如何去使用数据集和数据加载器。
在这一阶段我们的主要目标是学会使用数据集和数据加载器,同时了解我们的训练集。废发不多少,现在开始。
从广义上来说,我们这个阶段仍然是在做准备数据的工作。
- 准备数据。
- 建立模型。
- 训练模型。
- 分析模型的结果。
在这篇文章中,我们将会看到数据集和数据加载器如何在前面文章介绍的对象中发挥作用的。在前面的文章中提到,我们有两个PyTorch对象—Dataset(数据集)和DataLoader(数据加载器)。 train_settrain_loader
现在我们将要去查看这些对象是如何工作的。
PyTorch Dataset:使用训练集
现在去实现一些操作以便我们更好的了解我们的数据。
探索数据
查看在我们的训练集中有多少张图片,我们可以使用len()函数查看我们的数据集的长度。
len(train_set)
#结果为:
#60000
这60000张图正是我们之前提到的Fashion-MNIST 数据集中的。如果我们想查看每一个图片的labels,我们可以这样做:
>train_set.targets
tensor([9, 0, 0, ..., 3, 0, 5])
第一张图片的标签是9,其后面的两张图片的标签都为0。在之前的文章中提到,这些值对实际的类名和标签进行编码。数字9表示短靴,数字0表示T恤衫。
如果我们想查看每一个类别标签的数量(比如,有多少张短靴的图片,有多少张T恤衫的图片)我们可以使用PyTorch的bincount()函数进行查询,如下所示:
> train_set.targets.bincount()
tensor([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000])
类别失衡:均衡和不均衡的数据集(Class Imbalance: Balanced And Unbalanced Datasets)
从上面的bincount()函数的结果可以看出,Fashion-MNIST数据集是均衡的,这表示,我们样本中的每一个类别的数量都是相等的。我们每个类别都有6000个样本。如果每个类别中的样本数量是不同的,我们就将其叫做不均衡数据集(unbalanced dataset)。
类别失衡是一个普遍的问题,但是,在我们的案例中,我们的Fashion-MNIST数据集是均衡的,所以在我们的项目中不必担心这个问题。
可以在下面这篇论文中了解更多关于深度学习中处理类别不均衡问题的方法:A systematic study of the class imbalance problem in convolutional neural networks.
从训练集中获取数据
为了从训练集中获取单一的元素,我们首先通过train_set对象传递给Python的内置函数iter()。这个函数将返回一个代表数据流的对象。
在得到这个数据流之后,我们可以使用python中的内置函数next()去得到数据流中的下一个元素。下面的代码表示我们期待得到一个样本,所以我们以sample(样本)来进行命名:
> sample = next(iter(train_set))
> len(sample)
2
通过这个调用这个样本的len()函数,我们可以看到这个样本有两个部分,这是因为数据集是由图片-标签对组成的。从训练集中取回的每一个样本都包含tensor类型的图片数据和与之相关的tensor类型的标签数据。
由于样本是一个序列类型(sequence type),我们可以使用序列拆包来分配图像和标签。我们现在检查图像和标签的类型,它们都是torch.Tensor类型的对象:(下面的代码中label的类型是int,不知道是原著编者写错了,还是我理解错了。)
> image, label = sample
> type(image)
torch.Tensor
> type(label)
int
我们可以看到图片的形状为1 x 28 x 28的张量。而标签是标量值张量。
> image.shape
torch.Size([1, 28, 28])
> torch.tensor(label).shape
torch.Size([])
我们也可以使用squeeze()函数去查看如何去除尺寸为1的维度。
> image.squeeze().shape
torch.Size([28, 28])
基于我们前面关于Fashion-MNIST 数据集的讨论。我们期待看到我们28 x28形状的图像。我们在张量的第一维上看到1的原因是需要这个维度来表示通道数。通常图片由RGB三种颜色通道表示。灰度图像通常只有单一的颜色通道。这就是为什么我们有1x28x28的张量。我们在28x28图像上有一个颜色通道。
现在让我们绘制图像,我们将首先了解为什么要压缩张量。我们首先压缩张量,然后将其传递给imshow()函数。
> plt.imshow(image.squeeze(), cmap="gray")
> torch.tensor(label)
tensor(9)
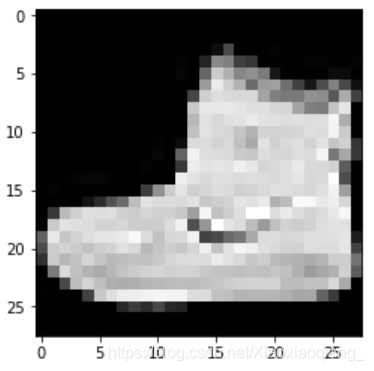
我们得到一个短靴和其标签9。我们知道标签9表示一个短靴,因为我们在前面已经提到过了。
准备好,让我们看看数据加载器是如和工作的。
PyTorch 数据加载器:批量处理数据(PyTorch DataLoader: Working With Batches Of Data)
我们将开始创建一个新的小批次数据加载器,其尺寸为10。所以很容易便能够实现。
> display_loader = torch.utils.data.DataLoader(
train_set, batch_size=10
)
我们使用iter()和next()函数从加载器中获得一批数据。
在使用数据加载器时应该注意一件事情,如果shuffle = Ture,则每次调用next后得到的批次都会不同。在使用shuffle = True时,训练集中的第一组样本将在第一次调用next时返回。shuffle默认关闭。
# note that each batch will be different when shuffle=True
#注意,当shuffle=True时,得到的每一个批次都会不同。
> batch = next(iter(display_loader))
> print('len:', len(batch))
len: 2
检查返回的一批数据的长度,我得到的结果时2,就像我们对训练集所进行操作后得到的结果一样。让我们继续查看这两个张量和其形状:
> images, labels = batch
> print('types:', type(images), type(labels))
> print('shapes:', images.shape, labels.shape)
types: <class 'torch.Tensor'> <class 'torch.Tensor'>
shapes: torch.Size([10, 1, 28, 28]) torch.Size([10])
因为batch_size = 10,我们知道我们处理的时10个图像和其对应的10个标签。所以我们使用复数的形式对其进行命名。
其类型是我们所期待的tensor类型。然而,它们的形状和我们之前看到的不一样。我们没有一个标量作为标签,而是有一个带有10个值的轴。每个维度内容由包含下面这些值:
(批次的大小,颜色通道,图片高度,图片宽度)>>其对应上述代码中的(10,1,28,28)
表示:批次大小是10,颜色通道为1,图像高度为28,图像宽度为28。
批处理大小为10,这就是为什么在形状中第一个数字为10。每一个图片都会有一个索引。接下来查看我们之前看到的第一个短靴。
> images[0].shape
torch.Size([1, 28, 28])
> labels[0]
9
我们可以使用torchvision.utils.make_grid()函数来创建一个网络(grid)来绘制一批图像:
> grid = torchvision.utils.make_grid(images, nrow=10)
> plt.figure(figsize=(15,15))
> plt.imshow(np.transpose(grid, (1,2,0)))
> print('labels:', labels)
labels: tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])

感谢Amit Chaudhary为我们指出使用PyTorch张量方法permute()来代替np.transpose()。就像这样:
> grid = torchvision.utils.make_grid(images, nrow=10)
> plt.figure(figsize=(15,15))
> plt.imshow(grid.permute(1,2,0))
> print('labels:', labels)
labels: tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])

下面是类名和标签的映射关系:
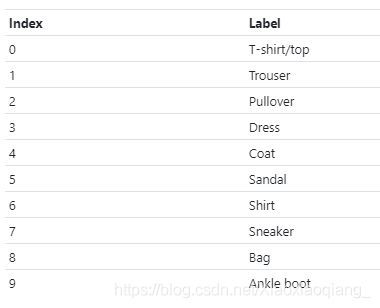
如何使用PyTorch数据加载器绘制图像
下面使用PyTorch数据加载器进行图像的绘制,这个方法受Barry Mitchell启发:
how_many_to_plot = 20
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=1, shuffle=True
)
plt.figure(figsize=(50,50))
for i, batch in enumerate(train_loader, start=1):
image, label = batch
plt.subplot(10,10,i)
plt.imshow(image.reshape(28,28), cmap='gray')
plt.axis('off')
plt.title(train_set.classes[label.item()], fontsize=28)
if (i >= how_many_to_plot): break
plt.show()

下一阶段进行模型的建立
我们现在应该对数据集和数据加载器有了更好的理解。这些都为我们接下来的工作提供很重要的基础。下次再见。