numpy 用法总结
简介
numpy 是Numerical Python的简称,是高性能的科学计算和数据分析的基础包,包含了大量的矩阵和数组的计算函数。下面来详细了解一下numpy的用法。
# 安装 numpy
pip install numpy
# 查看numpy的版本
numpy.__version__
# 导入numpy
import numpy as np
一、创建ndarray
ndarray:numpy中最基础的数据结构,一种多维的数组对象。
创建数组最简单的方法是使用array函数,它接受一切序列的对象,然后产生一个新的含有传入数据的numpy数组。
# 传入一个列表
data1 = [6, 7.5, 8, 0, 1]
data1 = np.array(data1)
data1
#输出
#array([6. , 7.5, 8. , 0. , 1. ])
# 传入嵌套序列会转化为多维数组
data2 = [[1, 2, 3, 4], [5, 6, 7, 8]]
data2 = np.array(data2)
data2
#输出
#array([[1, 2, 3, 4],
# [5, 6, 7, 8]])
每个数组都会有一个shape(一个表示各维度大小的元组)和一个dtype(数组数据类型)
print(data1.shape, data1.dtype)
print(data2.shape, data2.dtype)
#输出
#(5,) float64
#(2, 4) int64
注意
1⃣️ 数组中所有元素的类型都相同;
2⃣️ 如果数组由列表创建,列表中的元素类型不一样时,会统一成某个相同的类型(优先级:str>float>int);
除npp.array之外,还有一些函数可以新建数组,比如zeros和ones可以新建指定长度或形状的全0和全1的数组,empty可以创建一个没有任何具体值的数据,在使用是应注意系统会初始化一个随机值。
np.zeros(10)
#输出
#array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
# 传入一个指定形状的元组
np.ones((3, 6))
#输出
#array([[1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1., 1.]])
arange 是python内置函数的数组版;
np.arange(12)
# 输出
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
np.arange(0, 12, 2)
# 输出
# array([ 0, 2, 4, 6, 8, 10])
一些常用的创建数组的函数
| 函数 | 说明 |
|---|---|
| array | 将输入数据(列表、元组、数组或其他序列类型)转化为ndarray |
| asarray | 将输入数据转化为ndarray |
| arange | 返回一个ndarray,而不是列表 |
| ones,ones_like | 根据指定形状创建全1的数组 |
| zeros,zeros_like | 根据指定形状创建全0的数组 |
| empty,empty_like | 创建新数组,只分配内存空间,不填充值 |
| eys,identity | 创建一N*N的数组(对角线为1,其余为0) |
二、ndarray的数据类型
dtype(数据类型)是一个特殊的对象,可以将ndarray转化为指定的数据类型
arr1 = np.array([1, 2, 3], dtype=np.float64)
arr2 = np.array([1, 2, 3], dtype=np.int32)
print(arr1.dtype)
print(arr2.dtype)
# 输出
float64
int32
numpy的数据类型
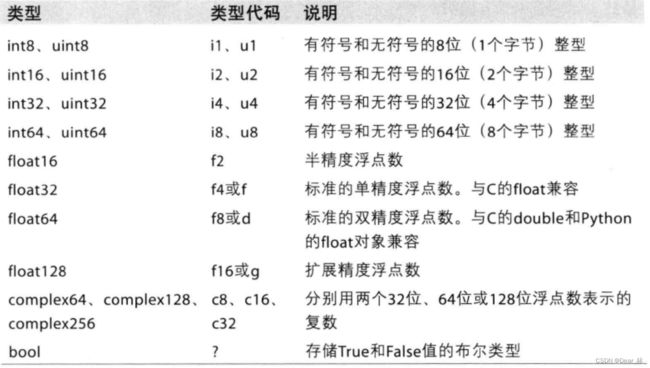

可以通过astype显式转化dtype
arr = np.array([1, 2, 3, 4])
arr.dtype
# 输出
# dtype('int64')
arr_float = arr.astype(np.float64)
arr_float
# 输出
# array([1., 2., 3., 4.])
上面是整数转化为浮点数,若将浮点数转化为整数,则小数部分会舍掉
arr = np.array([1.2, 3.4, 5.2, 5.6])
arr_int = arr.astype(np.int)
arr_int
# 输出
# array([1, 3, 5, 5])
三、ndarray常用的属性
维度 ndim, 大小 size, 形状 shape, 元素类型 dtype, 每项大小 itemsize, 数据 data
# 维度
arr = np.array([[1, 2, 3], [5, 3, 1]])
arr.ndim
# 输出:2
#数组的形状
arr.shape
#输出:(2, 3)
arr.dtype
# 输出:dtype('int64')
arr.size
#输出:6 指的是数组的元素个数
arr.itemsize
# 输出:8 数组中每个元素占用的字节数
arr.data
#输出:四、ndarray的基本操作
1、数组和标量之间的运算
数组是不用太过编写循环即可执行批量运算,另外大小相等的数组之间的任何运算都将会应用到元素级。
arr = np.array([[1., 2., 3.],[4., 5., 6.]])
arr*arr
# 输出
array([[ 1., 4., 9.],
[16., 25., 36.]])
1/arr
# 输出
array([[1. , 0.5 , 0.33333333],
[0.25 , 0.2 , 0.16666667]])
2、基本的索引和切片
索引:选取数组中数组子集或单个元素的方法。一维数组很简单,跟python的列表差不多。
arr = np.arange(10)
# 选取数组中的第六个元素
# 注意数组的下表是从0开始的
arr[5]
# 输出:5
# 选取数组中的某个子集
arr[3:6] # 指的是选取数组中的第3、4、5个元素
# 输出:array([3, 4, 5])
当一个标量值赋值到某个切片时,该值会自动广播到整个切片。这里跟列表最主要的区别是,数组的切片是原始数组的视图,这意味着数组不会被复制,视图上的任何修改都会放映到原数组中。
例如对上述arr的切片进行赋值
arr[3:5] = 12
arr
# 输出:array([ 0, 1, 2, 12, 12, 5, 6, 7, 8, 9])
对于二维数组,各索引位置上的元素不再是标量,而是一维数组。
arr2 = np.arange(9).reshape(3, 3)
arr2[2]
# 输出:array([6, 7, 8])
arr2[0, 2]
# 等价于arr2[0][2]
# 输出:2
二维数组的索引方式如下:

3、布尔型索引
# 假设有一个存储数据的数组和存储姓名的数组
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'])
data = np.random.randn(7, 4)
names=='Bob'
# 输出:array([ True, False, False, True, False, False, False])
# 布尔型数组用于数组索引
data[names=='Bob']
# 输出:
#array([[-0.29864871, 1.08067817, 0.47617838, -0.20705221],
# [ 0.9802988 , 1.88159087, -1.19031979, -0.30987026]])
注意这里布尔型数组的长度必须跟被索引数组的轴的长度一致,此外还可以将布尔型数组索引跟切片、整数混合使用。
data[names=='Bob', 2:]
# 输出:
array([[ 0.47617838, -0.20705221],
[-1.19031979, -0.30987026]])
4、花式索引
花式索引指的是用整数数组进行索引,假设有如下数组:
# 花式索引
arr = np.arange(32).reshape(8, 4)
arr[[4, 3, 0, 6]] # 以特定的顺序选取子集
# 输出:
array([[16, 17, 18, 19],
[12, 13, 14, 15],
[ 0, 1, 2, 3],
[24, 25, 26, 27]])
五、通用函数
通用函数是一种对ndarray中的数据执行元素级的运算,可以将其看作简单函数的矢量化包装。常用的ufunc有如下:


二元函数有:

以上就是numpy的基本的一些操作,此外numpy还可以利用数组进行数据处理以及读取文件,还有numpy的广播等。