【自监督论文阅读笔记】Green Hierarchical Vision Transformer for Masked Image Modeling
本文提出了一种 使用分层Vision Transformer (ViTs) ,例如Swin Transformer [43],进行 掩码图像建模(MIM)的有效方法,允许分层ViT 丢弃掩码patches,只对可见patches 进行操作。
本文的方法包括两个关键部分:
首先,对于窗口注意力window attention,本文按照分而治之策略 设计了一个 组窗口注意力Group Window Attention方案。为了减轻自注意力 相对于 图像块数量的 二次复杂度,组注意力鼓励uniform partition 一致的划分,使得每个任意大小的局部窗口内的可见小块 可以 以相同的大小分组,然后在每个组内执行掩码的自注意力。
其次,本文通过 动态规划算法 进一步改进分组策略,以最小化 分组块上 注意力的总体计算成本。因此,MIM现在可以以一种 绿色高效的方式 在 分层ViTs上 工作。例如,本文可以将训练分层ViT 的速度 提高约2.7倍,并将GPU内存使用量减少70%,同时仍能享受ImageNet分类上的竞争性能 和 下游COCO目标检测基准上的优势。
(绿色:GPU内存使用量减少)
Introduction:
受掩码语言建模 (MLM) [50, 51, 13, 5] 在自然语言处理 (NLP) 中的巨大成功 和 Vision Transformer (ViT) [15, 43, 60, 69] 的进步的推动,掩码图像建模(MIM)作为一种有前途的计算机视觉(CV)自监督预训练范式出现。 MIM 通过掩码预测 从未标记数据中学习表示,例如,预测离散的 tokens[2]、隐特征 [73、62、1] 或 随机掩码输入图像块的原始像素 [22、66]。其中,代表作 Masked Autoencoder (MAE) [22] 表现出具有竞争力的性能和令人印象深刻的效率。
本质上,MAE 为 MIM 提出了一种 非对称的编码器-解码器架构,其中编码器(例如,标准 ViT 模型 [15])仅在可见块上运行,轻量级解码器恢复所有块以进行掩码预测。
一方面,非对称的编码器-解码器架构 显著降低了 预训练的计算负担。另一方面,MAE 仅支持 各向同性的 ViT [15] 架构作为编码器,而 大多数现代视觉模型 采用层次结构 [37,25,43],部分原因是 需要处理视觉元素的尺度变化。
事实上,层次结构 和 局部归纳偏差 在各种 需要 不同级别或尺度的 表示 来进行预测的 CV 任务中至关重要,包括图像分类 [25] 和 目标检测 [19]。然而,如何将 分层的视觉转换器(例如 Swin Transformer [43])集成到 MAE 框架中仍然不是很简单。
此外,尽管 SimMIM [66] 的工作已经探索了用于 MIM 的 Swin Transformer,但它在可见和掩码块上都运行,并且与 MAE 相比,计算成本很高。作为一个具体的例子,本文发现即使是基本尺寸的 SimMIM 模型也无法在具有 8 个 32GB GPU 的单台机器上进行训练,更不用说更大的尺寸了。计算负担使得更广泛的研究人员难以深入这一研究领域,更不用说模型开发过程中的碳排放量了。
为此,本文本着绿色 AI [55, 67] 的精神,努力为具有层次模型的 MIM 设计一种新的绿色方法。本文的工作重点是将 MAE 的非对称的编码器 - 解码器架构扩展到分层视觉转换器,特别是代表性模型 Swin Transformer [43],以便 仅对可见块 进行有效的预训练。本文确定主要障碍是 局部窗口注意力的限制。尽管在分层视觉转换器中广泛使用,但 局部窗口注意力 不能很好地与随机掩码配合使用,因为它创建了无法并行计算的 各种大小的 局部窗口。
本文首次尝试解决这个缺点。本文的方法在概念上很简单,由两个部分组成。
首先,在分而治之的原则的指导下,本文提出了一个 Group Window Attention 方案,首先将 具有 奇数可见块的 局部窗口 划分为 几个相等大小的组,然后在每个组内 应用 掩码注意力 masked attention。
其次,本文将上述组划分 制定为 一个约束优化问题,其目标是找到一个组划分,以 最小化 对分组tokens的注意力 的计算成本。受 动态规划 [4] 概念 和 贪心原理 的启发,本文提出了一种 最优分组算法,该算法 自适应地 选择 最优组大小 并将 局部窗口 划分为 最少数量的组。
本文的方法是通用的,不会对主干模型的架构进行任何修改,这样我们就可以与 在可见和掩码patches上运行的基线进行对应的比较。在本文的实验评估中,观察到本文的方法需要的训练时间大大减少,消耗的 GPU 内存也少得多,同时性能与基线相当。具体来说,使用 Swin-B [43],与基线 SimMIM 相比,本文的方法只需要一半的训练时间和大约 40% 的 GPU 内存消耗,同时在 ImageNet-1K 上实现 83.7% 的 top-1 微调精度[ 54] 这与 SimMIM 相当。
(apple-to-apple comparisons :对两个东西的各个方面作一一对应的比较)
Contributions:
1. 本文设计了一个绿色的层次 Vision Transformer,用于掩码图像建模,倡导一种更实用的方法,大大提高了效率。
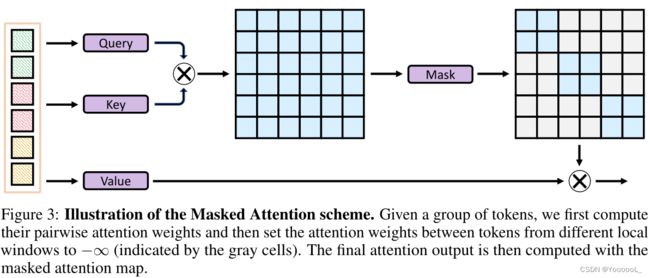
2. 如图2所示,本文提出了一个 组窗口注意力方案,将具有不同数量可见patches的局部窗口聚集成几个大小相等的组,然后在每个组内应用掩码注意力(见图3)。
3. 受 动态规划概念[4] 和 贪婪算法原理的启发,本文提出了一种最佳分组算法(参见算法1 ),该算法 自适应地 选择最佳组大小 并 将局部窗口 划分成最小数量的组。
4. 在ImageNet-1K [54]和MS-COCO [41]数据集上进行的大量实验评估表明,本文的方法可以获得与基准相当的性能,效率提高超过2倍(参见图1、表2和表3)。
Related Works:
自监督学习:【citable】
表征学习是CV中一个由来已久的基本问题,长期以来,表征学习一直以监督学习为主。直到最近三年,自监督学习(SSL)表现出令人印象深刻的性能,并得到了极大的关注。通常,SSL解决前置任务时 没有实际兴趣 学习好的表示。
根据前置任务的不同,SSL方法可以分为 生成方法 和 判别方法。
生成方法 基于部分观察到的输入来预测原始数据[59、49、38],预测应用于输入的变换[46、18], 或 输入空间中的模型像素[36、20、33、27]。掩码图像建模也属于这一类。
在过去的几年里,判别方法,特别是 对比学习方法 受到了更多的关注。对比学习使用一组随机数据失真 创建图像的多个视图,并鼓励表示 对失真保持不变。大量对比学习方法[63、47、23、9、71、72]通过最大化 正样本之间的相似性(即来自同一图像的视图),同时最小化 负样本之间的相似度 来驱动训练,有些作品只是简单地去除了负样本对[21、6、10、31、70、7]。除了对 全局特征 进行对比学习 外,还提出了几种方法来 维护表示的空间信息,并使用区域/掩码/像素级对比学习[61,65,64,26,29]。
Masked Language/Image Modeling:
自监督的预训练彻底改变了 NLP。其中,BERT [13] 及其变体 [5] 中提出的 Masked Language Modeling (MLM) 是最主要的方法,它们通过预测输入句子中随机掩码的tokens 来学习表示。 Masked Image Modeling 掩码图像建模 具有类似的 预测损坏图像 的想法,其中一些方法 [59, 49] 甚至早于 BERT。然而,这些方法在当时无法与其他预训练范例相提并论。
直到最近,在 Vision Transformers [15] 的显著进步的帮助下,几种 MIM 方法呈现出有希望的结果 [15、2、22、66、62],并成为 CV 中自监督学习的最新技术。这些方法可以 根据预测目标 进行粗略区分,例如 颜色箱color bins [15]、来自预训练 VAE [57、52] 的离散tokens [2、14]、原始像素 [22、66] 和 手工制作的特征[62]。在这些方法中,MAE [22] 展示了具有竞争力的性能和令人印象深刻的效率,因为它丢弃了掩码tokens 并 仅对可见标记进行操作。
Isotropic and Hierarchical Vision Transformers:
开创性的工作 Vision Transformer (ViT) [15] 彻底改变了传统的图像视图。 ViT 及其变体 [56] 将图像视为一系列patches,并采用 纯 Transformer [58] 主干 对patches进行建模 以进行图像分类,即使与卷积神经网络相比也取得了令人印象深刻的性能。然而,虽然 ViT 的结果在分类方面很有前景,但它 在密集预测任务上的表现不太理想,这主要是由于其 继承自 其各向同性结构的 低分辨率特征图 和 自注意力的二次复杂性 [58]。为此,一系列工作提出了 ViT 的层次结构 [60, 43, 16, 69] 和 有效的注意力 [30, 43, 12, 32],释放了 ViT 作为通用视觉骨干的潜力。本文的工作对 具有(移位)窗口局部注意力的代表性方法 Swin Transformer [43] 进行了研究,该方法在其他方法 [12、69、32] 中也被广泛采用。
Green AI:
见证了大型 AI 模型计算的指数级增长 [13, 5, 42],绿色 AI 的概念近年来受到越来越多的关注 [55, 67]。 Green AI 不只是痴迷于准确性,而是提倡 将效率 作为衡量 AI 模型的重要指标,倡导对研究界更具包容性的更环保的方法。本文遵循绿色 AI 的路径,并为具有分层 ViT 的 MIM 提供了一种更环保的方法。
Approach:
Preliminary:
Notations:令 ![]() 表示输入特征,其中 C、H 和 W 是 X 的通道数、高度和宽度;
表示输入特征,其中 C、H 和 W 是 X 的通道数、高度和宽度; ![]() 表示训练期间随机生成的(空间)掩码,其中 0 表示块对编码器不可见,反之亦然。
表示训练期间随机生成的(空间)掩码,其中 0 表示块对编码器不可见,反之亦然。
掩码图像建模: MIM 通过从其部分观察 ![]() 预测输入 X 的掩码部分来学习表示。关于 Mask(·,·) 操作,现有的 MIM 方法分为两类。
预测输入 X 的掩码部分来学习表示。关于 Mask(·,·) 操作,现有的 MIM 方法分为两类。
大多数方法 [2, 66, 62] 使用 Hadamard 积 进行掩码 并保留被掩码的patches,即 ![]() ,M 沿信道维度广播 C 次。
,M 沿信道维度广播 C 次。
与这些方法形成鲜明对比的是,Masked Autoencoders (MAE) [22] 建议在掩码阶段将掩码patches扔掉,即,
![]()
MAE 设计了一种 非对称和各向同性的编码器-解码器架构 以利用部分输入:编码器仅在没有掩码tokens的可见块 ![]() 上运行;解码器 从 可见块 和 掩码tokens 的表示中 重建原始图像。这种设计使 MAE 能够实现具有竞争力的性能和令人印象深刻的效率,例如,与在所有patches上运行的相比,训练速度提高了 3 倍。然而,MAE 仅适用于各向同性的 ViT,目前尚不清楚如何将 MAE 的效率转移到 分层的 ViT,在大多数视觉任务中,分层ViT 几乎一致地优于各向同性的 ViT [60、43、16、12、69]。在本文中,试图回答这个问题,并为具有分层 ViT 的 MIM 提出一种更环保的方法。
上运行;解码器 从 可见块 和 掩码tokens 的表示中 重建原始图像。这种设计使 MAE 能够实现具有竞争力的性能和令人印象深刻的效率,例如,与在所有patches上运行的相比,训练速度提高了 3 倍。然而,MAE 仅适用于各向同性的 ViT,目前尚不清楚如何将 MAE 的效率转移到 分层的 ViT,在大多数视觉任务中,分层ViT 几乎一致地优于各向同性的 ViT [60、43、16、12、69]。在本文中,试图回答这个问题,并为具有分层 ViT 的 MIM 提出一种更环保的方法。
用于掩码图像建模的Green Hierarchical Vision Transformer :
Base architecture:
本文选择具有代表性的分层ViT-Swin Transformer [43] —— 作为本文的基线,主要由 前馈神经网络(FFN)和(shifted)窗口注意力组成。虽然 FFN 是逐点操作,并且只能在可见块上进行操作,但窗口注意力无法做到这一点。
给定窗口大小 p(例如,Swin 为 7),窗口注意力首先将特征图 X 划分为 ![]() 个不重叠的局部窗口
个不重叠的局部窗口 ![]() ,其中每个 Xi 包含 p×p 个patches。然后,多头自注意力(MSA)[58] 在每个窗口内 独立并行执行,因为每个窗口包含相同数量的patches。
,其中每个 Xi 包含 p×p 个patches。然后,多头自注意力(MSA)[58] 在每个窗口内 独立并行执行,因为每个窗口包含相同数量的patches。
然而,当局部窗口内的patches数量不均匀时,即由于图 2 中的随机掩码,目前尚不清楚如何有效地并行计算注意力。为此,本文提出了一种高效的 Group Window Attention 方案,并直接替换 Swin 中的所有(移位的)窗口注意力,使其 仅以绿色方式 对 可见patches进行操作。
Group Window Attention:
针对上述问题,本文提出了一种组窗口注意力方案,该方案 显著提高了 窗口注意力 对 掩码特征的计算效率。给定等式 (1) 后的掩码特征 ![]() ,本文收集 一组 不均匀的局部窗口
,本文收集 一组 不均匀的局部窗口 ![]() ,其中每个元素仅包含 可见tokens,相应的大小为
,其中每个元素仅包含 可见tokens,相应的大小为 ![]() 。如图 2 所示,本文的 Group Window Attention 首先使用 Optimal Grouping 算法将不均匀的窗口划分为几个大小相等的组,然后在每个组内执行 Masked Attention 以避免信息泄漏。在接下来的两个小节中,将分别详细说明这两个组件。
。如图 2 所示,本文的 Group Window Attention 首先使用 Optimal Grouping 算法将不均匀的窗口划分为几个大小相等的组,然后在每个组内执行 Masked Attention 以避免信息泄漏。在接下来的两个小节中,将分别详细说明这两个组件。

动态规划的最优分组:
通用公式:
最优分组的第一步是找到一个关于 组大小 gs 的索引分区 Π:

其中 ng 是结果组的数量。等式 (3) 中的条件将分区限制为 包含 所有没有重复的局部窗口,并 强制每个组的实际大小 小于 gs。基于划分Π,得到一组 分组的token ![]() ,为
,为
![]()
在其上执行 Masked Attention。最后,应用分区 Π 的逆运算来恢复输出 tokens的位置。 (在这里,为了简单起见,本文假设 tokens的数量 ![]() 可以被 gs 整除。在实践中,在 |πj| 小于gs时填充组 πj。)
可以被 gs 整除。在实践中,在 |πj| 小于gs时填充组 πj。)
有了上面的公式,还有两个问题没有解决:1)如何选择最优的组大小 ![]() ,以及 2)如何在给定
,以及 2)如何在给定 ![]() 的情况下获得最优分区 Π*。为此,将本文的目标制定为以下 min-min优化问题,
的情况下获得最优分区 Π*。为此,将本文的目标制定为以下 min-min优化问题,
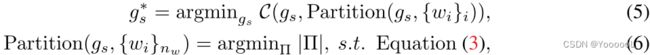
其中 C(·) 是一个成本函数,用于衡量 使用分组tokens的注意力的 计算成本。直观地说,等式(5)旨在找到 最优组大小 g∗s,即关于![]() 最优分区的计算成本最小。等式 (6) 在等式 (3) 的约束下,搜索最优分区。有了最优组大小,可以直接得到最优分区
最优分区的计算成本最小。等式 (6) 在等式 (3) 的约束下,搜索最优分区。有了最优组大小,可以直接得到最优分区![]() 。接下来,本文将详细介绍如何解决上述优化问题。
。接下来,本文将详细介绍如何解决上述优化问题。
使用动态规划进行分组划分:
本文发现等式 (6) 和 (3) 中的优化问题是 具有相同容量的多子集和问题 (MSSP-I) 的 一个特例,它是著名的具有相同容量的 0-1 多重背包问题的变体(MKP-I)[34,第 10 章]。在本文的例子中,组的大小类似于背包的容量,可见tokens的数量![]() 类似于商品的价值,商品的重量与其价值相同,背包的数量是无界的。
类似于商品的价值,商品的重量与其价值相同,背包的数量是无界的。
虽然一般的多背包问题是 NP-complete 非完全多项式,但由于容量相同,它的变体 MSSP-I 可以使用动态规划 (DP) 算法 [4] 在伪多项式时间内求解。具体来说,本文 将 DP 算法用于单背包问题(或子集和问题):
![]()
它从全集 Φ中选择一个子集 π,使得 ![]() (该算法的伪代码在附录中给出)。
(该算法的伪代码在附录中给出)。
我们交替地 将该算法应用于剩余的全集 Φ 并 从 Φ 中排除选定的子集 π,直到 Φ 为空。在实践中,发现本文的算法 非常快 并且 时间成本可以忽略不计,因为局部窗口的数量通常很少,例如在本文的预训练阶段少于 100。
成本函数:
因为本文主要关心效率,所以本文使用 FLOPs 来衡量 多头注意力 对分组tokens的 计算复杂度,即
![]()
其中 C 是通道数。尽管复杂度是组大小 gs 的二次方,但 使用较小的 gs 可能会产生更多的组(和更多的填充),并且效率不理想。因此,最佳组大小在训练期间 自适应地确定。
Putting everything together:
本文扫描组大小的可能值,从 ![]() 到
到 ![]() ,以找到最佳组大小。对于每个选定的组大小,首先使用等式(7)中的 DP 算法对窗口进行分区,然后计算该分区的注意力的计算成本。选择成本最小的一个作为最佳组大小。算法1总结了最优分组的伪代码。
,以找到最佳组大小。对于每个选定的组大小,首先使用等式(7)中的 DP 算法对窗口进行分区,然后计算该分区的注意力的计算成本。选择成本最小的一个作为最佳组大小。算法1总结了最优分组的伪代码。

Masked Attention:
由于不相邻的局部窗口被划分为相同的组,因此需要 掩码注意力的权重 以避免 这些局部窗口之间的信息交换。如图 3 所示,在计算了注意力图之后,本文只保留了窗口内的注意力权重(即块对角元素)并 丢弃了窗口间的注意力权重。类似的掩码方案也应用于检索相对位置偏差 [43],我们存储每个token的原始绝对位置 并 即时计算相对位置 以检索相应的偏差。
批量级随机掩码:
本文观察到 每个样本的随机掩码策略 会降低本文方法的效率:1)它可能会为每个样本产生不同数量的局部窗口组,这对于 Masked Attention 的并行计算是难以处理的; 2)当掩码patches大小 小于 分层模型的最大patches大小时,一些patches可能 同时包含 可见和掩码输入。在这种情况下,我们不能在训练期间丢弃这些patches,也不能充分利用稀疏化。因此,本文建议将掩码patches大小设置为与编码器的最大patches大小相同的值(例如,大多数分层模型为 32,这也是 [66] 的默认选择),并对同一GPU设备中的所有样本 使用相同的随机掩码(也称为微批次 micro-batch)。
Experiments:
Implementation Details and Experimental Setups:
本文在 ImageNet-1K [54](BSD 3-Clause License)图像分类数据集 和 MS-COCO [41](CC BY 4.0 License)目标检测/实例分割数据集上进行了实验。 Swin-Base 和 Swin-Large [43] 模型由四个阶段组成,具有步幅为 4/8/16/32 的特征,在本文中用作编码器,用于与基线 [66] 进行直接比较。该模型首先在没有标签的 ImageNet-1K 数据集上进行预训练,然后在下游任务上进行微调。本文方法的所有实验都是在具有 8 个 32G Tesla V100 GPU、CUDA 10.1、PyTorch [48] 1.8 和自动混合精度训练 [45] 的单台机器上进行的。
预训练设置:
本文使用 4×4 的patch大小 对大小为 224×224 的图像进行 patch化,并按照 3.5 节中的方案以比率 r(默认情况下 r = 0.75)随机掩码 patch。输入图像通过一组简单的数据增强进行转换,包括随机裁剪 和 水平翻转 以及 归一化。遵循之前的工作 MAE [22] ,本文使用了一个轻量级解码器,该解码器由 nd(默认情况下 nd = 1)个嵌入维度为 512 的 transformer块 组成。解码器将可见patches的表示 和 掩码tokens 作为输入,被附加在编码器的最后阶段之后,用于学习掩码patches的表示。紧随其后的是一个线性层来预测掩码patches的归一化像素值。这些模型经过 100/200/400/800 次训练,批量大小为 2,048。本文将 AdamW 优化器 [35] 与 余弦退火计划 [44] 一起使用。将基础学习率设置为 1.5e-4,权重衰减为 0.05,Adam 的超参数 β1 = 0.9,beta2 = 0.999,预热 epoch 的数量设置为 40,初始基础学习率为 1.5e-7。有效学习率由 batch_size/256 线性缩放。
ImageNet-1K 数据集上的微调:
为了进行微调,本文删除了解码器,并直接将 1000 路的全连接层 附加到编码器的平均池输出作为分类器。这些模型还通过 AdamW 优化器 [35] 进行了优化,总共 100 个训练 epoch,20 个预热 epoch,基础/预热学习率为 1.25e-4/2.5e-7,余弦退火计划 [44],权重衰减 0.05,分层学习率衰减 [2] 为 0.9,随机深度 [28] 比率为 0.1。数据增强与 [2, 66] 相同。
MS-COCO 数据集上的微调:
本文采用了带有 FPN [40] 作为检测器的 Mask R-CNN [24] 架构。所有模型都在 MS-COCO [41] 2017 训练拆分(~118k 图像)上进行了微调,最后在 val 拆分(~5k 图像)上进行了评估。本文使用 16 的批量大小,AdamW 优化器 [35],学习率为 1e-4,权重衰减为 0.05。采用 mmdetection [8] 中的 1×/3× 调度,总共使用 12/36 个训练 epoch,并将总 epoch 的 3 4 和 11 12 的学习率衰减 10 倍。标准 COCO用于对象检测和实例分割的指标,包括 AP、AP50 和 AP75 用于评估。
Ablations studies:
与 SimMIM 的效率比较:

图 1 中,将本文方法的效率与基线 SimMIM 进行了比较。对于本文的方法,评估是在具有 8 个 32GB V100 GPU 的单台机器上执行的,而对于 SimMIM,评估是在 2 或 4 台机器上执行的,因为它 无法适应 具有原始论文[66]的默认批量大小(即 2,048)的单台机器 。从图中可以看出,使用 224*224 大小的图像 训练 SimMIM 非常缓慢且需要大量内存。尽管 使用较小的图像 进行训练大大减少了训练时间和内存消耗,但它仍然远远落后于 本文使用大小为224*224 的图像的方法。具体而言,在相同数量的训练时期下,本文的方法在使用 Swin-B 的情况下 与基线性能相当,具有 ∼2 倍的加速 和 ∼60% 的内存减少。本文还观察到,使用更大的Swin-L ,效率提升越大,例如,与 SimMIM192 相比,加速比提高了 2.7 倍,突出了本文的方法在使用更大模型时的效率。
每个阶段stage的最佳组大小 gs:
由于 层次模型 具有 多个 具有不同特征尺度的阶段,因此每个阶段的最佳组大小也可能不同。对此,本文设计了一个模拟实验来分析不同阶段的最优gs。在模拟中,本文 根据第 3.5 节 随机生成 100 个掩码,计算不同 gs 选择的成本,并在图 4 中报告 成本的均值/标准差。注意,这里省略了第 4 阶段的分析,因为它只有一个局部窗口。

一般来说,我们观察到 成本 随 组大小 呈二次方增加,但 组大小 正好等于 局部窗口子集的总和 的某些情况除外。
另一个有趣的观察是,每个阶段的成本似乎是在 gs = 49 附近时为最小值,这等于窗口注意力的窗口大小。这一观察表明,本文可能不需要扫描所有可能的组大小,而只需在实践中设置 gs = p × p。
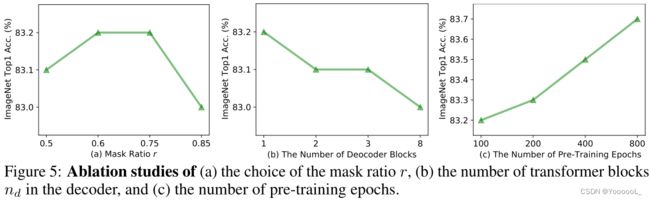
掩码率、解码器块数和预训练epoches的影响:
从图 5(a) 可以看出,本文的方法 在掩码率 r 在 0.5 到 0.85 之间变化时 性能相当稳定,,这与 [22] 的观察结果一致。在图 5(b) 中,还研究了解码器深度的影响。有趣的是,结果表明 更少的解码器块 会产生更好的结果。这项研究 倾向于 带有层次模型的 SimMIM [66] 的 简单预测头设计,这与 使用 各向同性模型 的 MAE [22] 的观察形成对比。为了简单和高效,在整篇论文中 将 r = 0.75 和 解码器块的数量 固定为 1。此外,研究了预训练预算 对本文方法的影响。如图 5(c) 所示,微调准确度随着训练 epoch 的数量稳步增加,并且似乎没有停滞不前,这表明它有进一步提升性能的潜力。
具有更大窗口大小的预训练:
[42] 的工作提出 使用 更大的窗口大小 有利于微调。然而,在实践中,它可能不太实用,因为 self-attention 的二次复杂性与窗口大小有关。幸运的是,仅在可见块上进行操作 允许以更大的窗口大小进行训练,而额外的成本很少。如表 1 所示,窗口大小加倍的预训练 仅将训练时间/GPU 内存略微增加不到 10%/20%,但在微调中 p = 7 时带来了适度的性能提升。
ImageNet-1K 分类:
本文在 ImageNet 验证集上微调预训练模型,并在表 2 中报告结果。在这里,本文与以下模型进行直接比较:1)从头开始训练,训练时间更长,2)对比学习训练,以及3) 用 MIM 训练。本文的方法使用 Swin-Base 主干实现了 83.7% 的 top-1 微调精度,这 优于监督学习/对比学习方法,并且与使用具有相似能力的主干的其他 MIM 方法相当。结果证明了本文方法的有效性,此外还 比 MAE 和 SimMIM 显著提高了效率。附录中给出了 Swin-L 主干的实验,以进一步检查本文的方法。
MS-COCO 目标检测和实例分割:
最后,评估了本文的预训练模型到 MS-COCO 目标检测和实例分割数据集的迁移学习性能。在这里,本文直接使用 有监督的 Swin Transformer 的代码库,而无需对微调策略进行任何修改。为了直接比较,本文使用他们的公开checkpoints 重新运行了有监督的 Swin-B 和 SimMIM 的实验。实验结果总结在表 3 中。与有监督的预训练 Swin-B 相比,本文的方法在所有指标方面都表现得更好,例如,APb 的绝对改进为 1.5%。此外,还观察到本文的方法在密集预测任务上的表现仍然与 SimMIM 相当。更重要的是,本文的方法使用 3 倍或 10 倍以上的微调时期 和 高级数据增强 [17],优于 [39] 中的大多数基线。这些实验,结合表 2 中的结果,验证了本文的方法可以实现出色的性能和令人印象深刻的预训练效率。
Conclusion:
在本文中,提出了一种 带有 层次Vision Transformers的 掩码图像建模 (MIM) 的绿色方法,例如 Swin Transformer [43],允许 层次模型 丢弃掩码patches 并 仅对可见patches 进行操作。结合高效的 Group Window Attention 方案 和 基于 DP 算法的 Optimal Grouping 策略,本文的方法可以 更快地训练 层次模型 ~2.7 倍,并将 GPU 内存消耗减少 70%,同时在 ImageNet 分类和下游 MS-COCO 目标检测基准的优势。本文希望这项工作将促进未来 以 有效性 和 效率 为目标的 自监督学习方法。
Limitation:
本文算法的限制之一是它需要 batch-wise掩码方案(如第 3.5 节)来实现最佳效率。虽然这个限制对 MIM 预训练影响不大,但它限制了本文的方法在更广泛的设置上的应用,例如,使用 需要 instance-wise实例级稀疏化的 token稀疏化 训练 ViT [53、68]。这些应用超出了这项工作的范围,本文将把它们留给未来的研究。
更广泛的影响:
这项工作为具有层次ViT 的 MIM 提出了一种绿色方法,显着减轻了 MIM 的繁重计算负担。一方面,这项工作提高了 MIM 的效率和有效性,这可能会激发新的算法和对该方向的研究。另一方面,由于预训练数据集可能包含偏差,本文的方法与其他无监督/自监督学习方法一样,也可能容易复制这些偏差。通过结合 FairML 方法 [3] 可以减轻这种担忧。