深度学习第三周
ResNet
ResNet在2015年由微软实验室提出,获得当年ImageNet竞赛分类第一名、目标检测第一名。
网络的亮点:
- 超深的网络层数(突破1000层)
- 提出residual残差模块
- 使用Batch Normalization来加速网络的训练
 ResNet网络结构
ResNet网络结构
在卷积神经网络中并不是卷积层和池化层进行简单的堆加越多越好,这是因为由于层数的加深,梯度消失或梯度爆炸的情况发生的概率会增加。
而在ResNet中,使用了残差模块来解决这写因为网络深度过多而带来的问题。

在RetNet残差结构中还有着一种shortcut时虚线的情况,这种情况是由于在残差结构中,输入的维度要和输出的维度相同,在shortcut中添加1*1的卷积核来进行维度的调整,使得残差结构满足维度相等的情况。

此外,这种需要调节的残差结构存在于conv3、conv4、conv5的第一层,并且步长都为2。
Batch Normalization
Batch Normalization的目的是使得一批数据的特征矩阵满足均值为0,方差为1的分布规律。

下面是一个计算的例子。假设输入图像有2个通道,每个通道有两个特征图,其中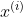 表示第
表示第 通道的数据,经过求均值和方差公式可以计算的到方差和均值,然后在经过Batch Normalization的计算公式可以得到新的te特征矩阵的值。
通道的数据,经过求均值和方差公式可以计算的到方差和均值,然后在经过Batch Normalization的计算公式可以得到新的te特征矩阵的值。
在上图中的 和
和 初始值分别为1和0,并且其值在网络的训练过程中在反向传播过程中逐渐优化的。
初始值分别为1和0,并且其值在网络的训练过程中在反向传播过程中逐渐优化的。
需要注意的问题:

迁移学习
使用迁移学习的优势:
- 能够夸苏的训练出一个理想的结果
- 当数据集较小时也能训练出理想的结果

conv1、conv2的角点信息和纹理信息都是比较通用的信息,在其他网络中也同样适用,因此可以将学习好的网络参数迁移到新网络中,通过这种方法可以较快的对一个网络进行训练。
常见的迁移学习的方式:
- 载入权重后训练所有的参数
- 载入权重后只训练最后几层参数
- 载入权重后在原网络的基础上再添加一层全连接层,并且仅训练最后一个全连接层
Pytorch实现ResNet34
利用Pytorch实现ResNet34用于花类的识别。在训练阶段利用GPU进行训练,采用迁移学习策略,使用ResNet预训练权重对模型进行训练。
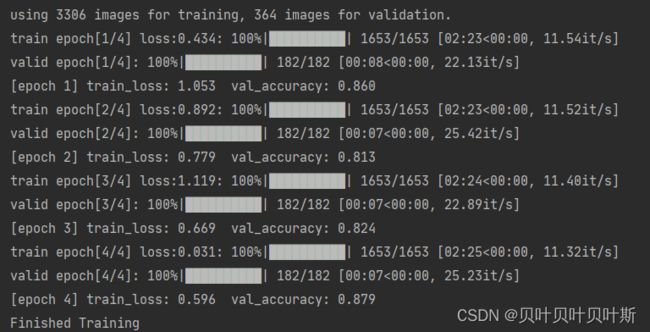
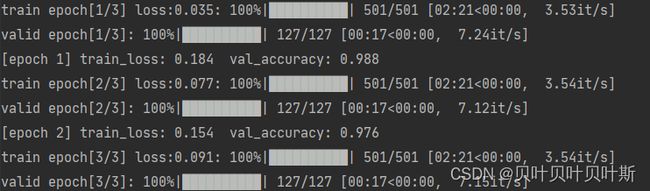
训练结果:
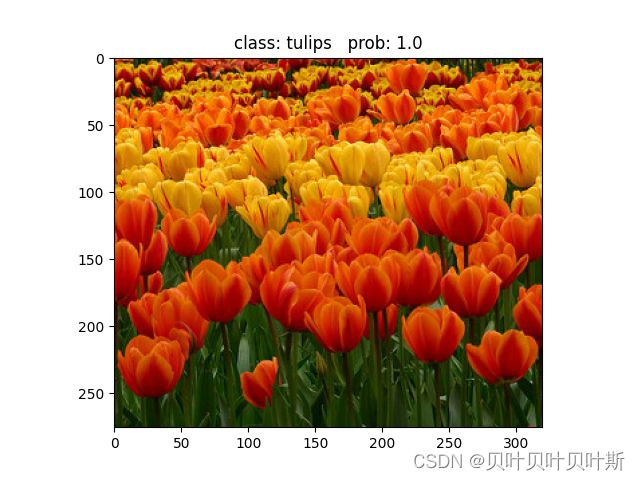
对模型进行一次测试:

RestNeXt
RestNeXt是ResNet的一个小的升级,左边是ResNet的残差结构,右边是ResNeXt的结构。

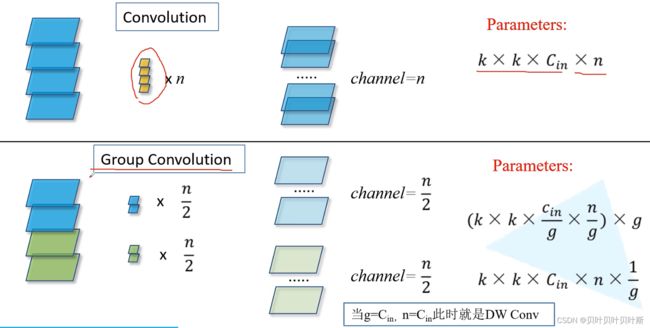
分组卷积
代码练习
- 构建ResNet网络
class BasicBlock(nn.Module):
expansion = 1
#downsample是在虚线的残差结构中
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)#加上padding可以使特征矩阵大小相等
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x- 加载数据集并对网络进行训练
- 编写test.py输出模型在测试集上的预测值
model.eval()
resfile = open('res.csv', 'w')
for i in range(0, 2000):
#加载当前的图片
img_path = 'F:/学习资源/deep-learning-for-image-processing-master/data_set/cat_dog/test/' + str(i) + '.jpg'
img = Image.open(img_path)
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print(img_path,":",predict_cla.item())
resfile.write(str(i) + ',' + str(predict_cla.item()))
resfile.close()之前出现过加载测试集出现过错误,出错原因是因为,测试集的命名中不含有该图像的分类标签。对测试集的处理需要对文件夹的每张图片继续宁遍历操作。
- 查看控制台输出与文件中内容


- 上传网站检测精确度

实际上ResNet的精准度应该很高,本次上传的是对测试集没有进行较好的预处理,并且模型仅仅训练的2个epoch,接下来会继续进行改进。
1、Residual learning
当想利用更深层的网络进行训练时,会出现梯度消失或者梯度爆炸的情况。Residual learning是用于解决深层网络训练的问题,将输入与输出相结合,解决梯度消失等问题。
2、Batch Normailization 的原理
Batch Normalization的目的是使得一批数据的特征矩阵满足均值为0,方差为1的分布规律,加快模型的收敛速度。详见此链接。
3、为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分组数量尽量多不行吗?
分组卷积能减少运算量和参数量,所以不容易过拟合,相同输入输出大小的情况下,减少为原来的![]()
分组数量并不是越多越好,当分组数目与输入图像channel相同,达到最大分组数,此时使用分组卷积会降低各个通道间的关联性,从而使得准确率降低。