【论文学习笔记】《An Overview of Voice Conversion and Its Challenges》
《An Overview of Voice Conversion and Its Challenges: From Statistical Modeling to Deep Learning》论文学习
文章目录
- 《An Overview of Voice Conversion and Its Challenges: From Statistical Modeling to Deep Learning》论文学习
-
- 摘要
- 1 介绍
- 2 典型语音转换流程
-
- 2.1 语音分析与重构
- 2.2 特征提取
- 2.3 特征映射
- 3 使用并行训练数据进行语音转换的统计建模
-
- 3.1 高斯混合模型
- 3.2 动态核偏最小二乘
- 3.3 频率弯折
- 3.4 非负矩阵分解
- 4 使用非并行训练数据进行语音转换的统计建模
-
- 4.1 INCA 算法
- 4.2 单位选择算法
- 4.3 说话人建模算法
- 5 深度学习语音转换
-
- 5.1 用于帧对齐并行数据的深度学习
- 5.2 用于并行数据含有注意力机制的编码器-解码器
- 5.3 超越成对说话人的并行数据
-
- 5.3.1 成对说话人的非并行数据
- 5.3.2 利用 TTS 系统
- 5.3.3 利用 ASR 系统
- 5.3.4 将说话人从说话内容中解脱出来
- 6 语音转换评价
-
- 6.1 客观评价
- 6.2 主观评价
- 6.3 使用深度学习方法进行评估
- 7 声音转换的挑战
-
- 7.1 使用深度学习方法进行评估
- 7.2 2016 语音转换挑战概述
- 7.3 2018 语音转换挑战概述
- 7.4 2020 语音转换挑战概述
- 7.5 相关挑战 — ASVspoof Challenge
- 8 资源
- 9 结论
摘要
说话人身份是人类语言的重要特征之一。在语音转换中,我们在保持语言内容不变的同时,改变说话人的身份。语音转换涉及多种语音处理技术,如语音分析、频谱转换、韵律转换、说话人特征化和声编码等。
随着理论和实践方面的最新进展,我们现在能够产生具有高说话人相似性的类似人类的声音质量。
在本文中,我们提供了从统计方法到深度学习的最先进的语音转换技术及其性能评估方法的全面概述,并讨论了它们的前景和局限性。我们还将报告最近的语音转换挑战( VCC ),当前技术状态的性能,并提供语音转换研究可用资源的摘要。
1 介绍
语音转换( VC )是人工智能的一个重要方面。它是研究如何在不改变语言内容的情况下,将一个人的声音转换成与另一个人的声音相似。语音转换属于语音合成的一个通用技术领域,它将文本转换为语音或改变语音的属性,如声音身份、情感、口音等。
斯图尔特是语音合成的先驱,他在《An electrical analogue of the vocal organs》中评论说,人工制造语音的真正困难不在于制造出可以产生语音的设备,而在于如何操作这个设备。
语音转换研究的重点是语音中语音身份的处理,是语音处理中一个具有挑战性的研究问题。
自从 20 世纪 50 年代首次提出基于计算机的语音合成技术以来,人们就一直在努力寻求有效地操纵语音特性。
20 世纪 70 年代数字信号处理技术的迅速发展,极大地促进了语音处理参数的控制。
尽管声音转换的原始动机可能是简单的新鲜感和好奇心,统计建模的技术进步深入学习对许多实际的应用程序产生重大影响,消费者受益,如个性化语音合成(《Spectral voice conversion for text-to-speech synthesis》,《Joint training framework for text-to-speech and voice conversion using multi-source tacotron and wavenet》),帮助言语障碍的沟通(《Towards personalised synthesised voices for individuals with vocal disabilities: Voice banking and reconstruction》),说话人身份隐藏(《Evaluating voice conversion-based privacy protection against informed attackers》),声音模仿与伪装(《Voice conversion versus speaker verification: An overview》,《Defending your voice: Adversarial attack on voice conversion》),和为电影配音。
一般来说,一个说话的人有三个特点:1)反映在句子结构、词汇选择和方言方面的语言因素;2)超音段因素,如语音信号的韵律特征;3)与短期特征相关的部分因素,如光谱和共振峰。
在语言内容固定的情况下,超音段和音段因素是影响说话人个性的相关因素。期望一种有效的语音转换技术能同时转换超音段和音段因素。
尽管取得了很大的进步,语音转换仍然远远不够完美。在本文中,我们在庆祝技术进步的同时,也暴露了它们的局限性。我们将从历史和技术的角度讨论最先进的技术。
一种典型的语音转换管道包括如下图所示的语音分析、映射和重构模块,称为分析-映射-重构管道。
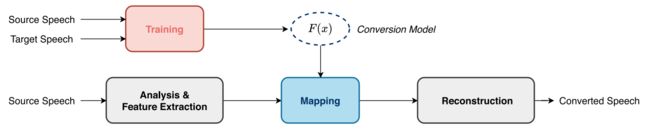
语音分析器将源说话人的语音信号分解成表示超段信息和段信息的特征,然后映射模块将这些特征指向目标说话人,最后重构模块重新合成时域语音信号。
映射模块在许多研究中占据了中心地位。这些技术可以以不同的方式分类,例如基于训练数据的使用:并行与非并行,统计建模技术类型:参数和非参数,优化的范围:帧级和语句级,和工作流的转换:直接映射与语言间映射。
让我们先从训练数据的使用角度进行说明。
语音转换的早期研究主要集中在使用并行训练数据的频谱映射上,其中源说话者和目标说话者都可以使用相同语言内容的语音,例如,矢量量化( VQ )(《Voice conversion through vector quantization》)和模糊矢量量化(《Speaker adaptation and voice conversion by codebook mapping》)。
使用并行数据,可以使用动态时间扭曲(《On the impact of alignment on voice conversion performance》)来对齐两个话语。
统计参数方法可以受益于更多的训练数据以提高性能,例如高斯混合模型(《Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory》,《Probabilistic feature mapping based on trajectory HMMs》,《The NU-naist voice conversion system for the voice conversion challenge 2016》),偏最小二乘回归(《Voice conversion using partial least squares regression》)和动态核偏最小二乘回归( DKPLS )(《Voice conversion using dynamic kernel partial least squares regression》)。
其中一个成功的统计非参数技术是基于非负矩阵分解( NMF )(《Semisupervised noise dictionary adaptation for exemplar-based noise robust speech recognition》),它被称为基于范例的稀疏表示技术(《Exemplar-based voice conversion in noisy environment》,《Exemplar-based sparse representation with residual compensation for voice conversion》,《Parallel dictionary learning for multimodal voice conversion using matrix factorization》,《Cute: A concatenative method for voice conversion using exemplar-based unit selection》)。
它需要比参数化技术更少的训练数据量,并且很好地解决了过平滑问题。我们注意到,当频谱被平滑时,就会产生消声效应。
稀疏表示技术包括语音稀疏表示、组稀疏实现(《Voice conversion based on non-negative matrix factorization using phoneme-categorized dictionary》,《Sparse representation of phonetic features for voice conversion with and without parallel data》)等,大大提高了小型并行训练数据集的语音质量。
对非并行训练数据(《Cross-language voice conversion evaluation using bilingual databases》,《Text-independent voice conversion based on unit selection》,《A spectral space warping approach to cross-lingual voice transformation in HMM-based TTS》,《VTLN-based crosslanguage voice conversion》,《INCA algorithm for training voice conversion systems from nonparallel corpora》,《Frame alignment method for cross-lingual voice conversion》)语音转换的研究为新的应用开辟了机会。
难点在于如何建立非并行源语和目标语之间的映射关系。
Error 等人(《INCA algorithm for training voice conversion systems from nonparallel corpora》)提出的印加对齐技术是解决非并行数据对齐问题(《Supervisory data alignment for text-independent voice conversion》)的一种解决方案。
使用对齐技术,可以将语音转换技术从并行数据扩展到非并行数据,如扩展到 DKPLS (《Voice conversion for non-parallel datasets using dynamic kernel partial least squares regression》)和说话人模型对齐方法(《Text-independent voice conversion using speaker model alignment method from non-parallel speech》)。
语音后图,或基于 PPG 的(《Phonetic posteriorgrams for many-to-one voice conversion without parallel data training》)方法,是研究非并行训练数据的另一个方向。
基于 PPG 的对齐技术在不使用外部资源的情况下,利用自动语音识别器生成中间语音表示(《Query-by-example spoken term detection using phonetic posteriorgram templates》,《Event selection from phone posteriorgrams using matched filters》)作为说话者之间的语际语言。
成功的应用包括语音稀疏表示(《Sparse representation of phonetic features for voice conversion with and without parallel data》)。
Wu 和 Li (《Voice conversion versus speaker verification: An overview》), Mohammadi 和 Kain (《An overview of voice conversion systems》)从语音特征的时间对齐以及代表统计建模学派的特征映射的角度对语音转换系统进行了概述。
深度学习技术的出现是语音转换研究(《Transformation of formants for voice conversion using artificial neural networks》)的一个重要技术里程碑。
它不仅极大地提高了技术水平,而且改变了我们研究语音转换的方式问题。它还开辟了一个新的研究方向,超越了并行和非并行数据范式。
尽管如此,统计建模方法的研究对研究问题的许多方面提供了深刻的见解,成为当今深度学习方法论的基础工作。
在本文中,我们将概述语音转换研究,提供一个视角,揭示从统计建模到深度学习的潜在设计原则。
深度学习对语音转换的贡献可以概括为三个方面。
首先,它允许映射模块从大量的语音数据中学习,从而极大地提高了语音质量和与目标说话人的相似度。
对于神经网络,我们把映射模块看作是一个非线性转换函数(《Multilayer feedforward networks are universal approximators》),它是从数据(《Comparing ANN and GMM in a voice conversion framework》,《High quality voice conversion using prosodic and high-resolution spectral features》)中训练出来的。
LSTM 代表了一个成功的并行训练数据(《Voice conversion using deep bidirectional long short-term memory based recurrent neural networks》)的实现。
深度学习对非并行数据技术产生了巨大的影响。
DBLSTM 和 i-vector (《On the use of I-vectors and average voice model for voice conversion without parallel data》)、 KL 发散和基于 DNN 的方法(《A KL divergence and DNN-based approach to voice conversion without parallel training sentences》)、变分自动编码器(《Voice conversion from non-parallel corpora using variational auto-encoder》)、平均建模(《Average modeling approach to voice conversion with non-parallel data》)、基于 DBLSTM 的递归神经网络(《Phonetic posteriorgrams for many-to-one voice conversion without parallel data training》,《Personalized, crosslingual TTS using phonetic posteriorgrams》)和端到端 Blow 模型(《Blow: A single-scale hyperconditioned flow for non-parallel raw-audio voice conversion》)的联合使用,将语音质量提升到一个新的高度。
最近,生成式对抗网络,如 VAW-GAN (《Voice conversion from unaligned corpora using variational autoencoding Wasserstein generative adversarial networks》), CycleGAN (《Parallel-data-free voice conversion using cycle-consistent adversarial networks》,《Highquality nonparallel voice conversion based on cycle-consistent adversarial network》,《Can we steal your vocal identity from the Internet?: Initial investigation of cloning Obama s voice using GAN, WaveNet and low-quality found data》),和 StarGAN (《StarGAN-VC: Nonparallel many-to-many voice conversion with star generative adversarial networks》)的多对多映射进一步推进了最先进的技术。
其次,深度学习对声编码技术产生了深远的影响。
语音分析和重构模块通常使用传统参数声码器(《Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory》,《Probabilistic feature mapping based on trajectory HMMs》,《The NU-naist voice conversion system for the voice conversion challenge 2016》,《A comparison between straight, glottal, and sinusoidal vocoding in statistical parametric speech synthesis》)来实现。
这种声码器的参数是根据信号处理中一些过于简化的假设手工调整的。因此,参数声码器提供了一个次优的解决方案。
神经声码器是一种神经网络,它学习从声学特征(《A comparison of recent waveform generation and acoustic modeling methods for neural-network-based speech synthesis》)重建音频波形。
第一次,神经声码器变得可训练和数据驱动。
WaveNet 声码器(《An investigation of multi-speaker training for wavenet vocoder》)代表了一种流行的神经声码器,它直接从输入特征向量中估计波形样本。
人们对它进行了深入的研究,例如,与扬声器相关和独立的 WaveNet 声码器(《An investigation of multi-speaker training for wavenet vocoder》,《Speaker-dependent wavenet vocoder》),准周期 WaveNet 声码器(《Quasiperiodic wavenet vocoder: A pitch dependent dilated convolution model for parametric speech generation》,《Statistical voice conversion with quasi-periodic wavenet vocoder》), GANs (《Adaptive wavenet vocoder for residual compensation in GAN-based voice conversion》)的自适应 WaveNet 声码器,分解的 WaveNet 声码器(《Wavenet factorization with singular value decomposition for voice conversion》),以及 VAEs (《Refined wavenet vocoder for variational autoencoder based voice conversion》)的精炼 WaveNet 声码器,这些都以其自然发声的音质而著名。
在传统的语音转换管道中,如 GMM (《Speaker-dependent wavenet vocoder》)、稀疏表示(《A voice conversion framework with tandem feature sparse representation and speaker-adapted wavenet vocoder》,《Group sparse representation with WaveNet Vocoder adaptation for spectrum and prosody conversion》)系统中, WaveNet 声码器被广泛采用。
其他成功的神经声码器包括 WaveRNN 声码器(《Efficient neural audio synthesis》)、 WaveGlow (《WaveGlow: A flow-based generative network for speech synthesis》)和 FloWaveNet (《Flowavenet: A generative flow for raw audio》),它们本身都是优秀的声码器。
第三,深度学习代表了对传统的分析-映射-重建方法的背离。以上所有技术主要遵循前文提到的语音转换管道。
神经声码器是可训练的,可以与映射模块(《Adaptive wavenet vocoder for residual compensation in GAN-based voice conversion》)甚至分析模块共同训练,成为端到端解(《Wavenet: A generative model for raw audio》)。
语音转换研究曾经是语音合成中的一个小领域。然而,这已经成为近年来的一个主要话题。
在第 45 届国际声学、语音和信号处理会议( ICASSP 2020 )上,语音转换论文占语音合成类论文的三分之一以上。
学术界和产业界的合作活动加速了研究社区的增长,例如 2016 年语音转换挑战( VCC ),该挑战首次在 INTERSPEECH 2016 年发布(《The voice conversion challenge》,《Multidimensional scaling of systems in the voice conversion challenge》,《Analysis of the voice conversion challenge 2016 evaluation results》)。
VCC 2016 专注于最基本的语音转换任务,即对 acoustic studio 中记录的并行训练数据进行语音转换。它建立了绩效基准的评估方法和协议,在社区中广泛采用。
VCC 2018 (《The voice conversion challenge: Promoting development of parallel and nonparallel methods》,《The voice conversion challenge 2018: Database and results》,《NU voice conversion system for the voice conversion challenge 2018》)提出了一个非并行训练数据挑战,并将语音转换与说话人验证研究的抗欺骗连接起来
VCC 2020 首次提出了跨语言语音转换挑战。我们将在本文中概述这一系列的挑战和公共资源。
本文的工作组织如下:在第二节中,我们介绍了语音转换的典型流程,包括特征提取、特征映射和波形生成。
在第三节中,我们研究了使用并行训练数据进行语音转换的统计建模。
在第四节中,我们研究了在没有并行训练数据的情况下语音转换的统计建模。
在第五节中,我们研究了使用并行训练数据进行语音转换的深度学习方法,并超越了并行训练数据。
在第六节中,我们解释了语音转换的评估技术。
在第七节和第八节中,我们总结了一系列语音转换的挑战,以及公开可用的语音转换研究资源。
我们在第九节总结。
2 典型语音转换流程
语音转换的目的是修改源说话人的声音,使其听起来好象是由目标说话人产生的。
换句话说,语音转换系统只修改与说话人相关的特征,如共振峰、基本频率( F0 )、语调、强度和持续时间,而保留与说话人无关的语音内容。
语音转换系统的核心模块实现语音转换功能。
我们将源语音信号表示为 x ,目标语音信号表示为 y 。
如后面将要讨论的,语音转换通常应用于语音的一些中间表示,或语音特征,这些特征是语音框架的特征。
我们用 x 和 y 表示源语音和目标语音特征。转换函数可以表示为:
![]()
其中 F(·) 在本文的其余部分中也称为帧映射函数。
如前文所示,一个典型的语音转换框架是由三个步骤实现的:1)语音分析;2)特征映射;3)语音重建;我们称之为分析-映射-重建管道。我们接下来再详细讨论。
2.1 语音分析与重构
语音分析与重构是这三个过程中的两个关键过程。
语音分析的目标是将语音信号分解为某种中间表示形式,以便对语音的声学特性进行有效的处理或修改。
在语音通信和语音合成方面,有很多有用的中间表示技术。它们对语音转换很方便。
一般来说,这些技术可以分为基于模型的表示和基于信号的表示。
在基于模型的表示中,我们假设语音信号是根据底层的物理模型(如源滤波器模型)生成的,并将一帧语音信号表示为一组模型参数。通过修改参数,我们可以对输入语音进行操作。
在基于信号的表示中,我们不假设任何模型,而是将语音表示为时域或频域可控元素的组成。
让我们用 x 表示源说话者的中间表示,语音分析可以用一个函数来描述:
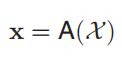
语音重构可以看作是语音分析的逆函数,对修改后的参数进行操作,产生可听的语音信号。它与语音分析串联工作。
例如,声码器(《A comparison between straight, glottal, and sinusoidal vocoding in statistical parametric speech synthesis》)用于表达具有一组可转换回语音波形的可控参数的语音帧。
采用 Griffin-Lim 算法,通过幅度修正后的修正短时傅里叶变换重构语音信号(《Signal estimation from modified short-time Fourier transform》)。
由于语音重构过程会影响输出语音的质量,因此语音重构也是语音转换研究中的重要课题之一。
将改进的中间表示和目标说话人的重构语音信号表示为 y 和 y = R(y) ,语音转换可由三个函数组成来描述:

它表示语音转换系统的典型流程为一个三步管道。
当逐帧进行映射时,如果在此过程中不修改语音持续时间,则转换后的语音特征个数 y 与源语音特征个数 x 相同。
语音分析和重构使语音转换成为可能,但就像其他信号处理技术一样,它们也不可避免地引入了伪影。许多研究都致力于将这些伪影降到最低。
接下来我们将讨论语音转换中最常用的语音分析和重构技术。
1)基于信号表示:
基音同步叠加加( PSOLA )是基于信号的表示技术的一个例子。
它将语音信号分解成重叠的语音片段(《Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones》),每个片段代表语音信号的一个连续音高周期。通过将这些语音片段与不同的音高周期重叠和相加,我们可以重构出不同语调的语音信号。由于 PSOLA 直接对时域语音信号进行操作,分析和重构不会引入显著的伪影。
尽管PSOLA技术可以有效地修改语音信号的基频,但它受到一些固有的限制(《Voice transformation using psola technique》,《Speaker transformation algorithm using segmental codebooks (STASC)》)。例如,未发声语音信号不是周期性的,时域信号的处理也不是简单的。
谐波加噪声模型( HNM )是另一种基于信号的表示方法。
它的工作原理是,语音信号可以表示为一个谐波分量加上一个以最大浊音频率为界限的噪声分量(《Applying the harmonic plus noise model in concatenative speech synthesis》)。
谐波分量被建模为谐波正弦波直到最大浊音频率的总和,而噪声分量被建模为高斯噪声,经过时变自回归滤波器滤波。
由于 HNM 分解是用一些可控的参数来表示的,因此可以方便地修改语音(《A system for voice conversion based on probabilistic classification and a harmonic plus noise model》,《Weighted frequency warping for voice conversion》)。
2)基于模型表示:
基于模型的技术假设输入信号可以用一个参数随时间变化的模型来表示。
一个典型的例子是源-滤波器模型,该模型将语音信号表示为由喉上声道形状决定的传递(滤波器)函数调制的喉头(源)激励的结果
声码器是一种语音编码器的缩写形式,最初是为了将语音通信所传输的数据量最小化而开发的。
它将语音编码成缓慢变化的控制参数,如线性预测编码和梅尔对数频谱近似(《Mel log spectrum approximation (MLSA) filter for speech synthesis》),这些参数描述了滤波器,并在接收端用源信息重新合成语音信号。
在语音转换中,我们通过修改可控制的参数,将源说话人的语音信号转换成目标说话人的语音信号。
大多数声码器是基于某种形式的语音产生源-滤波器模型设计的,例如带频谱包络的混合激励和声门声码器(《A comparison between straight, glottal, and sinusoidal vocoding in statistical parametric speech synthesis》)。
在语音合成和语音转换中, STRAIGHT 或基于加权谱自适应插值的语音转换与表示是最常用的语音编码器之一(《Restructuring speech representations using a pitch-adaptive time frequency smoothing and an instantaneous-frequency-based f0 extraction: Possible role of a repetitive structure in sounds》)。
它把语音信号分解成:1)在时间和频率上没有周期性的平滑谱图;2)一种用不动点算法估计的基频( F0 )轮廓;3)一种时频周期图,它捕获了噪声的频谱形状及其时间包络线。
STRAIGHT 在语音转换中被广泛使用,因为它的参数表示便于语音的统计建模,这允许对语音的简单操作(《Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory》,《Voice conversion using artificial neural networks》,《Wavelet analysis of speaker dependent and independent prosody for voice conversion》)。
参数化声码器在语音转换研究(《Voice conversion through vector quantization》,《Speaker adaptation and voice conversion by codebook mapping》,《Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory》,《Probabilistic feature mapping based on trajectory HMMs》,《Voice conversion from unaligned corpora using variational autoencoding Wasserstein generative adversarial networks》,《Parallel-data-free voice conversion using cycle-consistent adversarial networks》,《Unsupervised learning of disentangled and interpretable representations from sequential data》,《Learning latent representations for speech generation and transformation》)中被广泛应用于语音分析和重构,至今(《Exemplar-based voice conversion in noisy environment》,《Voice conversion based on non-negative matrix factorization using phoneme-categorized dictionary》,《Sparse representation of phonetic features for voice conversion with and without parallel data》)仍发挥着重要作用。
传统的参数化声码器是在一定的简化假设下近似人类语音产生的复杂机制。
例如,忽略 F0 与共振峰结构之间的相互作用,丢弃原来的相位结构(《Digital speech processing, synthesis, and recognition(revised and expanded)》)。
短时间窗内的平稳过程假设和定常线性滤波也会导致“机器语音”和“嗡嗡声”的产生。
当我们同时对 F0 和共振峰结构进行修改时,这些问题在语音转换中变得更加严重。
我们认为语音编码可以通过考虑参数之间的相互作用来改进。
3)WaveNet 声码器:
深度学习为参数化声码器的一些固有问题提供了解决方案。
WaveNet (《Wavenet: A generative model for raw audio》)是一种深度神经网络,它学习生成高质量的时域波形。由于它不假设任何数学模型,它是一个数据驱动的解决方案,需要大量的训练数据。
波形 X = x1, x2, …, xn 的联合概率可以分解为条件概率的乘积。

一个 WaveNet 是由许多剩余块构成的,每个块由 2 × 1 个扩展的因果卷积,一个门控激活函数和 1 × 1 的卷积组成。
通过附加辅助特征 h , WaveNet 也可以模拟条件分布 p(x|h) 。上图也可写成如下形式:

一个典型的参数化声码器可以对语音进行分析和重建。然而,目前大多数的 WaveNet 声码器只涵盖语音重建的功能。它以语音的一些中间表示形式作为输入辅助特征,生成语音波形作为输出。
WaveNet 声码器(《An investigation of multi-speaker training for wavenet vocoder》)在音质方面显著优于传统参数声码器。
它不仅可以学习输入特征与输出波形之间的关系,而且可以学习输入特征之间的相互作用。
它已被成功地采用作为最先进的语音合成(《Joint training framework for text-to-speech and voice conversion using multi-source tacotron and wavenet》,《Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions》,《Teacher-student training for robust tacotron-based TTS》,《Wavenet-based speech synthesis applied to czech》,《Deep voice: Real-time neural text-to-speech》)和语音转换(《An investigation of multi-speaker training for wavenet vocoder》,《Speaker-dependent wavenet vocoder》,《Statistical voice conversion with quasi-periodic wavenet vocoder》,《Refined wavenet vocoder for variational autoencoder based voice conversion》,《A voice conversion framework with tandem feature sparse representation and speaker-adapted wavenet vocoder》,《Group sparse representation with WaveNet Vocoder adaptation for spectrum and prosody conversion》,《Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions》,《Machine learning for limited data voice conversion》,《High-quality voice conversion using spectrogram-based wavenet vocoder》,《On the use of wavenet as a statistical vocoder》,《Wasserstein GAN and waveform loss-based acoustic model training for multi-speaker text-to-speech synthesis systems using a wavenet vocoder》,《A speaker-dependent wavenet for voice conversion with non-parallel data》,《A compact framework for voice conversion using wavenet conditioned on phonetic posteriorgrams》,《Wavenet factorization with singular value decomposition for voice conversion》,《Jointly trained conversion model and wavenet vocoder for non-parallel voice conversion using mel-spectrograms and phonetic posteriorgrams》)系统的一部分。
在 WaveNet 声音编码中,用声编码参数作为中间表示形式已经有了较好的研究前景。
利用直声编码参数,如 F0 、非周期性和频谱作为 WaveNet 的输入,研究了一种与说话人无关的 WaveNet 声码器(《An investigation of multi-speaker training for wavenet vocoder》)。通过这种方式, WaveNet 学会了时域波形和输入声编码参数之间的对应关系。
当这样的 WaveNet 声码器训练来自一个大的说话人群体的语音信号时,我们得到一个独立于说话人的声码器。
通过将与说话人相关的 WaveNet 声码器与说话人相关的数据进行适配,我们得到了一个与说话人相关的声码器,可以产生个性化的声音输出(《Adaptive wavenet vocoder for residual compensation in GAN-based voice conversion》,《Refined wavenet vocoder for variational autoencoder based voice conversion》)。
对 WaveNet 声码器的研究也为使用其他非声码参数作为输入提供了机会。
例如,最近的一项研究在 WaveNet 语音编码中采用了语音后图( PPG ),在非并行训练数据的语音转换中取得了很好的结果(《A speaker-dependent wavenet for voice conversion with non-parallel data》,《A compact framework for voice conversion using wavenet conditioned on phonetic posteriorgrams》,《Wavenet factorization with singular value decomposition for voice conversion》,《Jointly trained conversion model and wavenet vocoder for non-parallel voice conversion using mel-spectrograms and phonetic posteriorgrams》)。
另一项研究采用自编码器和嵌入说话人的潜码作为 WaveNet 声码器的语音表示(《Unsupervised speech representation learning using wavenet autoencoders》)。
4)神经声码器的最新进展:
最近,独立于说话人的基于 WaveRNN 的神经声码器(《Efficient neural audio synthesis》)变得流行起来,因为它可以从域内和域外的声谱图中产生类似人类的声音(《Towards achieving robust universal neural vocoding》,《A comparison of recent neural vocoders for speech signal reconstruction》,《Singing voice synthesis using deep autoregressive neural networks for acoustic modeling》)。
另一个获得高质量合成性能的著名神经声码器是 WaveGlow (《WaveGlow: A flow-based generative network for speech synthesis》)。 WaveGlow 是一种基于流的网络,能够从梅尔频谱图生成高质量的语音(《Real-time neural text-to-speech with sequence-to-sequence acoustic model and waveglow or single Gaussian wavernn vocoders》)。
WaveGlow 得益于 Glow 和 WaveNet 的优点,从而提供快速、高效和高质量的音频合成,而不需要自回归。
我们注意到 WaveGlow 仅使用一个具有单一代价函数的单一网络来实现,即最大化训练数据的可能性,这使得训练过程简单且稳定(《Parametric resynthesis with neural vocoders》)。
WaveNet 使用自回归( AR )方法对波形采样点的分布进行建模,这导致了较高的计算成本。作为自回归的替代方法,提出了一种神经源滤波器( NSF )波形建模框架(《Neural source-filter-based waveform model for statistical parametric speech synthesis》,《Neural harmonic-plus-noise waveform model with trainable maximum voice frequency for text-to-speech synthesis》)。
我们注意到, NSF 易于训练,并且可以快速生成波形。
据报道,它的速度比 WaveNet 声码器快 100 倍,但在大型语音语料库上也能达到相当的语音质量(《Neural source-filter waveform models for statistical parametric speech synthesis》)。
最近, Paralle WaveGAN (《Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram》)也被提出使用生成式对抗网络来生成高质量的声音。
Paralle WaveGAN 是一种无蒸馏和快速波形产生方法,通过联合优化多分辨率谱图和对抗损失函数来训练非自回归 WaveNet 。
我们注意到, Paralle WaveGAN 即使在其紧凑的架构下也能够产生高保真语音。
我们注意到,用 GANs 生成相干的原始音频波形具有挑战性。
另一种生成高质量音频波形的 GAN 方法被称为 MelGAN (《Melgan: Generative adversarial networks for conditional waveform synthesis》)。
MelGAN 证明了基于 GAN 的方法在语音合成、音乐领域翻译和无条件音乐合成中的高质量梅尔谱图反演的有效性。
2.2 特征提取
通过语音分析,我们得到了通常包含频谱和韵律成分的语音编码参数来表示输入语音。
声编码参数对语音进行了表征,我们可以在传输后重建语音信号。这在言语交流中尤为重要。
然而,这样的语音编码参数对于语音身份的转换可能不是最好的。
更多的时候,为了在语音转换中更有效地修改声学特性,我们将语音编码参数进一步转换为语音特征,我们称之为特征提取。
对于光谱成分,特征提取的目的是从高维原始光谱中得到低维表示。
一般来说,光谱特征能够很好地代表说话人的个性。
该特征既能很好地拟合光谱包络,又能转换回光谱包络。
它们应该有良好的插值特性,允许灵活的修改。
幅度谱可以扭曲到 Mel 或 Bark 频率尺度,这对语音转换有感知意义。
它也可以转化成倒谱域使用有限的系数使用离散余弦变换的对数大小。倒谱系数的相关性较小。这样,将高维量级谱转化为低维特征表示。
常用的语音特征包括梅尔倒谱系数( MCEP )、线性预测倒谱系数( LPCC )和谱线频率( LSF )。通常,语音框架由特征向量表示。
短时分析一直是语音分析中最实用的方法。不幸的是,它本质上忽略了语音转换中至关重要的时间上下文。
许多研究表明,多帧(《Exemplar-based sparse representation with residual compensation for voice conversion》,《An exemplar-based approach to frequency warping for voice conversion》)、动态特征(《Group sparse representation with WaveNet Vocoder adaptation for spectrum and prosody conversion》)、语音片段是特征映射的有效特征。
对于韵律成分,特征提取可以将韵律信号如基频( F0 )、非周期性( AP )、能量轮廓等分解为与说话人相关和独立的参数(《Wavelet analysis of speaker dependent and independent prosody for voice conversion》)。
这样,在特征映射的过程中,我们可以在转换与说话人相关的韵律模式的同时,延续与说话人无关的韵律模式。
2.3 特征映射
在典型的语音转换流程中,特征映射是将语音特征从声源修改到目标说话人。
谱映射的目的是改变声音的音色,而韵律转换的目的是修改韵律特征,如基频、语调和音长。
到目前为止,光谱制图仍然是许多语音转换研究的中心。
在训练过程中,我们从训练数据中学习到映射函数 F(·) 。
在运行推断时,映射函数转换声学特征。
本文的大部分内容是研究映射函数。
在第三节中,我们将讨论使用并行训练数据的传统统计建模技术。
在第四节中,我们将回顾不需要并行训练数据的统计建模技术。
在第五节中,我们将介绍一些深度学习方法,其中包括:1)成对说话者的并行训练数据;2)超越成对说话者的并行数据。
3 使用并行训练数据进行语音转换的统计建模
大多数传统语音转换技术都假定并行训练数据的可用性。换句话说,映射功能是根据源说话人和目标说话人说的相同语言内容的成对话语进行训练的。
语音转换研究始于 20 世纪 80 年代末的统计方法(《Acoustic characteristics of speaker individuality: Control and conversion》),可分为参数映射技术和非参数映射技术。
参数化技术对语音特征的基本统计分布及其映射进行假设。
非参数方法对数据做较少的假设,但寻求用最佳的映射函数拟合训练数据,同时保持一些泛化看不见的数据的能力。
参数化技术,如高斯混合模型( GMM )(《Continuous probabilistic transform for voice conversion》),动态核偏最小二乘回归, PSOLA 映射技术(《Voice transformation using psola technique》),代表了近年来的巨大成功。
语音转换的矢量量化方法是一种典型的非参数技术。它在源码本和目标码本(《Voice conversion through vector quantization》)[8]之间映射码字。该方法将源特征向量近似为源码本中最近的码字,并映射到目标码本中相应的码字。
为了减少量化误差,研究了模糊矢量量化(《Speaker adaptation and voice conversion by codebook mapping》,《Unsupervised speaker adaptation from short utterances based on a minimized fuzzy objective function》),即根据源特征向量在每一帧上确定单个簇的连续权值。
转换后的特征向量定义为映射码本质心向量的加权和。
最近,非负因子分解方法标志着一个成功的非参数实现。
我们将讨论一个在并行训练数据假设下的典型框架级映射范式,如下图所示:

在训练阶段,给定源说话人 x 和目标说话人 y 的并行训练数据,对源语音向量和目标语音向量进行帧对齐,得到成对的语音特征向量 z = {x, y} 。
动态时间翘曲是一种常用的基于特征的对齐技术。
语音识别器,配备语音知识,也可以用来进行基于模型的对齐。
在语音处理中,帧对齐已经得到了很好的研究。
在语音转换中,大量的文献都致力于帧级映射功能的设计。
3.1 高斯混合模型
在语音转换的高斯混合建模( GMM )方法(《Continuous probabilistic transform for voice conversion》)中,我们使用高斯混合模型表示源说话人和目标说话人两组光谱包络之间的关系。
高斯混合模型是一个连续的参数函数,它是训练为模型的光谱映射。
在(《Continuous probabilistic transform for voice conversion》),谐波加噪声( HNM )特征被用于特征映射,允许对语音信号进行高质量的修改。
GMM 方法被视为矢量量化方法(《Voice conversion through vector quantization》,《Speaker adaptation and voice conversion by codebook mapping》)的扩展,可改善语音质量。
但是,语音质量会受到一些因素的影响,如逐帧转换过程导致的频谱移动,其动态特性不合适,转换后的频谱过于平滑(《Voice conversion algorithm based on Gaussian mixture model with dynamic frequency warping of straight spectrum》,《Voice conversion algorithm based on Gaussian mixture model applied to straight》,《Spectral conversion based on maximum likelihood estimation considering global variance of converted parameter》)。
为了解决逐帧转换问题,研究了一种最大似然估计技术来建模光谱参数轨迹(《Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory》)。
该技术的目的是利用动态声学特征来估计适当的频谱序列。
为了解决过平滑问题,即模糊效应,研究了联合密度高斯混合模型( JD-GMM )(《Spectral voice conversion for text-to-speech synthesis》,《Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory》),采用极大似然估计方法对光谱特征序列及其方差进行联合建模,增加了光谱特征的全局方差。
JD-GMM 方法包括两个阶段:脱机训练和运行时转换阶段。
在训练阶段,采用高斯混合模型( GMM )对成对特征向量序列 z = {x, y} 的联合概率密度 p(z) 进行建模,表示源语音 x 和目标语音 y 的联合分布:

其中 K 为高斯分量个数, wk 为每个高斯分量的权重, μzk 和 Σ(z)k 分别是第 K 个高斯分量 N(z|μzk, Σ(z)k) 的均值向量和协方差矩阵。
为了估计 JD-GMM 的模型参数,使用期望最大化( EM )算法(《The expectation-maximization algorithm》,《What is the expectation maximization algorithm》,《Em algorithms of Gaussian mixture model and hidden Markov model》,《Theory and use of the em algorithm》)来最大化训练数据的似然性。
在运行时转换阶段,使用 JD-GMM 模型参数估计转换函数。
我们注意到, JD-GMM 训练方法能够稳健地提供模型参数的估计,特别是在训练数据量有限的情况下。
基于调制谱修正的后置滤波器被发现有助于解决统计建模中固有的过平滑问题(《Modulation spectrum-based post-filter for GMM-based voice conversion》),例如 GMM 方法,它有效地补偿了全局方差。
GMM 方法是一个参数解(《Maximum likelihood voice conversion based on GMM with straight mixed excitation》,《GMM-based voice conversion applied to emotional speech synthesis》,《GMM-based emotional voice conversion using spectrum and prosody features》,《Incorporating global variance in the training phase of GMM-based voice conversion》,《Improving the quality of standard GMM-based voice conversion systems by considering physically motivated linear transformations》)。
它代表了一种成功的统计建模技术,可以很好地处理并行训练数据。
3.2 动态核偏最小二乘
参数化技术家族还包括线性(《Voice transformation using psola technique》,《Speaker transformation algorithm using segmental codebooks (STASC)》)或非线性映射函数。
通过局部映射函数,每一帧语音都是独立于相邻帧进行转换的,这导致了输出的时间不连续。
为了考虑语音特征之间的时间依赖性,研究了动态核偏最小二乘( DKPLS )技术(《Voice conversion using dynamic kernel partial least squares regression》)。
该方法基于源特征的核变换,允许非线性建模,并连接相邻帧建模动力学。
非线性变换利用了 GMM 方法所没有的数据的全局特性。
据报道, DKPLS 在语音质量方面优于 GMM 方法(《Continuous probabilistic transform for voice conversion》)。这种方法简单有效,而且不需要大量的调优。
最近,研究了基于 DKPLS 的方法,通过特征组合策略来克服过拟合和过平滑问题(《Voice conversion based on feature combination with limited training data》)。
虽然对光谱特征映射的统计建模已经得到了很好的研究,但韵律转换通常只是通过简单的平移和缩放 F0 来实现,这不足以实现高质量的语音转换。
针对不同时间尺度上的不同语言单位,对韵律进行分层建模是一种先进的韵律转换技术(《Wavelet analysis of speaker dependent and independent prosody for voice conversion》,《A perceptual investigation of wavelet-based decomposition of f0 for text-to-speech synthesis》,《Wavelet-based decomposition of f0 as a secondary task for DNN-based speech synthesis with multi-task learning》,《Multi-layer f0 modeling for HMM-based speech synthesis》)。
DKPLS 创建了一个通过小波变换进行多尺度韵律转换的平台(《Hierarchical modeling of F0 contours for voice conversion》),与 F0 平移缩放技术相比,该平台在自然性方面有显著提高。
3.3 频率弯折
参数化技术,如 GMM (《Continuous probabilistic transform for voice conversion》)和 DKPLS (《Voice conversion using dynamic kernel partial least squares regression》),由于使用最小均方误差(《Voice conversion using artificial neural networks》)或最大似然(《Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory》)函数作为优化准则,通常会出现过平滑问题
结果,该系统产生的声学特征代表统计平均值,并不能捕捉所需的时间和光谱动力学细节。
此外,参数化技术通常使用低维特征,如第二节所讨论的,如梅尔倒谱系数( MCEP )或线谱频率( LSF ),以避免维数灾难。
然而,由于低分辨率,低维特征注定会丢失光谱细节。
统计平均和低分辨率特征都会导致输出语音的消音效果(《Voice conversion based on weighted frequency warping》)。
为了在转换过程中保留必要的光谱细节,引入了多种基于频率翘曲的方法。
频率翘曲技术通过频率翘曲函数将高分辨率源频谱直接转换为目标说话人的频谱。
在最近的文献中,翘曲函数要么用单个参数实现,如基于 VTLN 的方法(《VTLN-based crosslanguage voice conversion》,《VTLN-based voice conversion》,《Voice characteristics conversion for TTS using reverse VTLN》,《Non-linear frequency scale mapping for voice conversion in text-to-speech system with cepstral description》,《Pitch synchronous transform warping in voice conversion》),要么用分段线性函数表示(《Voice transformation using psola technique》,《Voice conversion based on weighted frequency warping》,《Voice conversion using dynamic frequency warping with amplitude scaling, for parallel or nonparallel corpora》),这已经成为主流的解决方案。
分段线性翘曲函数的目标是通过最小化光谱距离或最大化转换后的光谱与目标光谱之间的相关性,使源和目标光谱之间的一组频率对齐。
最近,参数频率翘曲技术与非参数基于范例的技术相结合,获得了良好的性能(《An exemplar-based approach to frequency warping for voice conversion》)。
3.4 非负矩阵分解
非负矩阵分解( Non-negative matrix factorization, NMF )(《Algorithms for non-negative matrix factorization》)是一种得到广泛应用的有效数据挖掘技术,特别是在语音增强(《Wavelet speech enhancement based on nonnegative matrix factorization》,《Supervised and unsupervised speech enhancement using nonnegative matrix factorization》)、语音去噪(《Speech enhancement using non negative matrix factorization and enhanced NMF》,《Speech denoising using nonnegative matrix factorization with priors》)、噪声和语音估计(《Speech enhancement under low SNR conditions via noise estimation using sparse and low-rank NMF with Kullback-Leibler divergence》)等高质量信号的重构中。
它将一个矩阵分解成两个矩阵,一个字典和一个激活矩阵,具有三个矩阵都没有负元素的性质。
在训练数据非常有限的情况下,基于 NMF 的技术被证明是有效的。
这标志着自矢量量化技术引入以来,非参数语音转换方法取得了重大进展。
成功的实现包括非负谱图反褶积(《Examplarbased voice conversion using non-negative spectrogram deconvolution》)、局部线性嵌入( LLE )(《Locally linear embedding for exemplar-based spectral conversion》)和单元选择(《Cute: A concatenative method for voice conversion using exemplar-based unit selection》)。
在基于 NMF 方法中,目标谱图是作为范例的线性组合构造的。因此,也会出现过平滑的问题。
为了克服过平滑的问题,我们开发了几种有效的技术,下面我们总结一下。
1)稀疏表示:
缓解过平滑问题的一种有效方法是将稀疏性约束应用于激活矩阵,称为基于范例的稀疏表示。
如下图所示,首先从源和目标的语音特征向量(我们称之为对齐范例)构建一对字典 A 和 B 。 [A; B] 也叫耦合字典。
在运行时,让我们把一个语音话语看作一个语音特征向量序列,这些特征向量构成一个语谱图矩阵。源词 X 的矩阵可以表示为:
![]()
由于谱图的非负性,采用 NMF 技术估计源激活矩阵 H , H 被限制为稀疏。数学上,我们通过最小化目标函数来估计 H :

其中 λ 是稀疏惩罚因子。为了估计激活矩阵 H ,使用了广义 Kullback-Leibler ( KL )散度。
假设源字典 A 和目标字典 B 可以共享同一个源激活矩阵 H 。
因此,转换后的目标说话人声谱图可以写成:

其中,激活矩阵 H 作为轴心,将源语 X 传递到目标语 Y 。
稀疏表示框架在语音转换中继续受到广泛关注。
最近的研究包括扩展到判别式嵌入图的 NMF 方法(《Parallel dictionary learning for multimodal voice conversion using matrix factorization》),频谱转换(《Sparse representation of phonetic features for voice conversion with and without parallel data》)的语音稀疏表示,以及在音色和韵律转换中的应用(《Exemplarbased sparse representation of timbre and prosody for voice conversion》,《Transformation of prosody in voice conversion》)。
2)语音稀疏表示:
由于帧级映射是在声特征级进行的,因此耦合字典 [A;B] 因此被称为声学词典。
利用训练数据的脚本和通用语音识别器,我们可以得到语音标签及其边界。
有研究表明,词典构建策略在语音转换中起着重要作用(《Dictionary update for NMF-based voice conversion using an encoder-decoder network》)。
根据运行时语音内容选择子字典的思想提高了(《Voice conversion based on non-negative matrix factorization using phoneme-categorized dictionary》)[的性能。
语音稀疏表示(《有和没有并行数据的语音转换的语音特征的稀疏表示》)是语音转换稀疏表示的扩展。
它是建立在语音子词典的思想上,并在运行时选择字典。
研究表明,在基于范例的稀疏表示语音转换中,多个语音子词典始终优于单个词典。
然而,语音稀疏表示在运行时依赖于语音识别器来帮助选择子字典。
3)组稀疏表示:
Sisman 等人提出了群稀疏表示(《Group sparse representation with WaveNet Vocoder adaptation for spectrum and prosody conversion》),在统一的数学框架下建立基于范例的稀疏表示(《Examplarbased voice conversion using non-negative spectrogram deconvolution》)和语音稀疏表示。
通过群稀疏正则化,只有与输入特征相关的语音子字典在运行推断时被激活。
语音稀疏表示既依赖于语音识别器进行训练,也依赖于运行时推理,而组稀疏表示在训练过程中,当我们构建语音字典时,只需要语音识别器。
有报道称,在进行频谱和韵律转换时,组稀疏表示的性能与语音稀疏表示相似(《Group sparse representation with WaveNet Vocoder adaptation for spectrum and prosody conversion》)。
4 使用非并行训练数据进行语音转换的统计建模
很容易理解,从并行的训练数据来训练映射函数比从非并行的训练数据来训练映射函数更直接。然而,并行训练数据并不总是可用的。
在现实世界的应用程序中,有时只有非并行数据可用。
直观地说,如果我们可以从非并行数据中推导出说话者之间的语音框架或片段的等价,我们就可以使用传统的线性转换参数训练来建立或细化映射函数,例如 GMM 、 DKPLS 或频率扭曲。
有很多人试图这样做。例如,一种想法是找到无监督特征集群之间的源-目标映射(《A first step towards text-independent voice conversion》)。
另一种方法是使用语音识别器对目标训练数据进行索引,这样我们就可以在运行时从目标数据库中为未知的源帧检索类似的帧(《Voice conversion for unknown speakers》)。
不幸的是,每一步都可能产生累积的误差,并可能导致较差的参数估计。
还有一项研究是使用为目标说话者训练的隐马尔可夫模型( HMM ),然后基于 HMM 的线性变换函数的参数进行估计,换算后的源向量相对于目标 HMM 表现出最大的似然性(《Quality-enhanced voice morphing using maximum likelihood transformations》)。
该方法与并行数据方法具有相当的性能。然而,它要求训练话语的正字法是已知的,这限制了它的使用。
接下来我们将讨论三大类研究及其代表性工作:1) INCA 算法,2)单元选择算法,3)说话人建模算法。
4.1 INCA 算法
INCA 是指最近邻搜索步长与转换步长对齐方法(《INCA algorithm for training voice conversion systems from nonparallel corpora》)的迭代组合。
它通过在目标声空间中寻找每个源向量的最近邻居来学习映射函数。
这是基于一个假设,基本最近邻方法的迭代改进,与语音转换系统串联,将导致渐进对齐改进。
其主要思想是利用前一次最近邻对齐后得到的中间语音 xks 作为下一次迭代的源语音:

在培训过程中,反复优化过程,直到当前的中间语音 xks 与目标语音 yt 足够接近。
INCA 代表了非并行训练数据问题的一个成功框架,其中最近邻搜索步骤( INCA 对齐)和转换步骤(参数映射函数)迭代优化映射函数,如下图所示。

INCA 最初是用 GMM 方法实现的(《Continuous probabilistic transform for voice conversion》)[113],用于语音转换,以估计线性映射函数。
由于INCA 不需要任何语音或语言信息,它不仅适用于非并行训练数据,也适用于跨语言语音转换。
实验表明,一个跨语言系统的 INCA 实现与在并行数据(《INCA algorithm for training voice conversion systems from nonparallel corpora》)上训练的语言内部对等体的性能相似。
INCA 进一步通过第三节讨论的 DKPLS 方法(《Voice conversion using dynamic kernel partial least squares regression》)为并行训练数据实施。
(《Voice conversion for non-parallel datasets using dynamic kernel partial least squares regression》)的想法是使用 INCA 对齐算法从源数据集和目标数据集找到相应的帧,这允许 DKPLS 回归找到对齐数据集之间的非线性映射。
据(《Voice conversion for non-parallel datasets using dynamic kernel partial least squares regression》)报道,INCA - DKPLS 实现产生的高质量语音与在相同数量的训练数据上使用并行训练数据实现的语音相当。
4.2 单位选择算法
在语音合成中,单元选择算法被广泛应用于自然语音的生成。
众所周知,它可以产生高的说话人相似度和语音质量(《Applying the harmonic plus noise model in concatenative speech synthesis》,《Optimising selection of units from speech databases for concatenative synthesis》,《High individuality voice conversion based on concatenative speech synthesis》),因为合成的波形是直接从目标说话人形成的声音单元(《Atr u-talk speech synthesis system》)。
单元选择算法从目标说话人的语音清单中优化单元选择。
有人建议(《Voice conversion of non-aligned data using unit selection》)利用单元选择合成系统从非并行数据中生成训练句子的并行版本。
有了这些伪并行数据,就可以很容易地应用我们在第三节中讨论的并行训练数据的统计建模技术。
虽然这种方法产生了令人满意的语音质量,但它需要一个庞大的语音数据库来开发语音清单,这在现实中并不总是实用的。
另一个想法是遵循我们在单位选择语音合成中所做的,通过定义一个语音特征向量为一个单位(《Text-independent voice conversion based on unit selection》)。
给定 M 个语音特征向量 X = {x1, x2, …, xm} 采用动态规划的方法,从目标说话人中找出代价函数最小的特征向量序列:
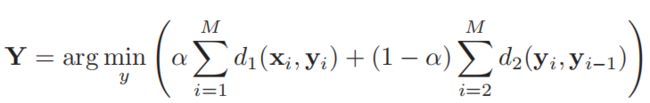
其中 d1(·) 表示源与目标特征向量之间的声距离, d2(·) 为两个目标特征向量之间的拼接代价。
利用声距离,我们可以保证从目标说话人处获取的语音特征与源语音特征接近。
利用连接代价,我们鼓励从目标说话人数据库中检索连续的语音帧在多帧段中一起检索。
如下图所示,单元选择算法是非参数解,因为我们没有对转换进行参数化建模:
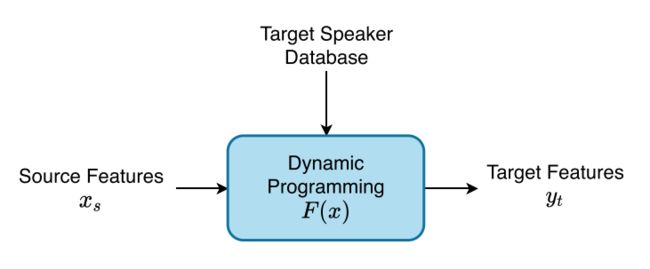
它通过应用动态规划从目标说话人数据库中寻找最佳特征向量序列来优化输出。
映射函数 Y = F(X) 由代价函数本身定义,并在话语层面进行优化。
4.3 说话人建模算法
对于非并行训练数据,可以很容易地使用独立于文本的说话者特征描述技术,其中可以通过一组参数(如 GMM 或 i-vector )对说话人建模。
可以使用这种说话人模型来执行语音转换。
Mouchtaris 等人(《Nonparallel training for voice conversion based on a parameter adaptation approach》)[157]使用了基于 GMM 的技术提前建模参考说话人之间的关系,并将该关系应用到新说话人。
Toda 等人(《Eigenvoice conversion based on Gaussian mixture model》)提出了一种特征语音方法,该方法执行两种映射,一种是从源说话人映射到从参考说话人训练的特征语音(或平均语音),另一个从特征音到目标说话人。
这些方法不需要并行训练数据,它们确实需要来自一些参考说话人的并行数据。
在说话人验证中,联合因子分析方法(《Frontend factor analysis for speaker verification》)将一个超向量分解为与说话人无关、说话人相关和通道相关的分量,每一个分量都用一组低维因子表示。
这样做的目的是为了将说话人与其他讲话内容分离开来,以便对说话人进行有效的验证。
受到这一想法的启发,我们认为(《Mixture of factor analyzers using priors from non-parallel speech for voice conversion》),类似的分解在语音转换中是有用的,在语音转换中,我们希望将说话人信息从语言内容中分离出来,并对说话人特定的成分进行因子分析。
通过因子分析,说话人特定成分可以通过因子负荷用一组低维潜在变量来表示。
其中一个想法(《Mixture of factor analyzers using priors from non-parallel speech for voice conversion》)是从非平行的先验数据中估计语音成分和因素负荷。
这样,在训练过程中,我们只估计一个低维的说话人身份因子和一个捆绑的协方差矩阵,而不是一个完整的转换函数从源目标的平行话语。
尽管估计转换函数仍然需要平行的语句,但使用之前的数据使我们能够从比传统 JD-GMM 所需的训练样本少得多的训练样本中获得可靠的模型(《Continuous probabilistic transform for voice conversion》)。
另一个想法是在 i-vector (《Frontend factor analysis for speaker verification》)说话人空间中执行语音转换,其中 i-vector 用于将说话人从语言内容中分离出来。
其主要动机是,无论说话人或说话内容如何, i-vector都可以以无监督的方式提取,这为源和目标说话内容不同甚至使用不同语言(《Frame alignment method for cross-lingual voice conversion》,《Personalized, crosslingual TTS using phonetic posteriorgrams》)的非并行数据场景开辟了新的可能性(《Cross-lingual voice conversion with bilingual phonetic posteriorgrams and average modeling》)。
Kinnunen 等人(《Non-parallel voice conversion using i-vector PLDA: Towards unifying speaker verification and transformation》)研究了一种在 i-vector 空间中将输入语音的声学特征向目标语音转移的方法。
其思想是学习一个将源话语的 i-vector 映射到目标话语的 i-vector 的函数。
通过映射函数,我们可以将源语音逐帧转换为目标语音。
这种技术不需要任何并行数据和文本转录。
5 深度学习语音转换
语音转换是一个训练数据稀缺的典型研究问题。
深度学习技术通常是数据驱动的,依赖于大数据。然而,这实际上是深度学习在语音转换中的优势。
深度学习为从大量可用的训练数据中获益开辟了许多可能性,这样语音转换任务就可以更多地专注于学习说话人特征的映射。
例如,在语音重建过程中,推断低层次的细节不应该是语音转换任务的工作,神经语音编码器可以从大型数据库中学习来完成这一工作(《Unsupervised speech representation learning using wavenet autoencoders》)。
学习如何表示一种口语的整个语音系统不应该是一个语音转换的任务,神经 ASR (《Voice conversion using sequence-to-sequence learning of context posterior probabilities》)或 TTS (《Cotatron: Transcription-guided speech encoder for any-to-many voice conversion without parallel data》)系统的通用声学模型可以从一个大型数据库中学习来完成这一任务。
通过利用大型数据库,我们解放了转换网络,不再使用它的能力来表示低级细节和一般信息,而是将重点放在说话人身份转换所需的高级语义上。
深度学习技术也改变了我们实现分析-映射-重建管道的方式。
为了有效映射,我们需要推导出足够的语音中间表示,这在第二节中已经讨论过了。
深度学习中的嵌入概念为推导中间表示提供了一种新的方法,例如,语言内容的隐码和说话人身份的嵌入。
这也使得说话人从说话内容中解脱出来更加容易。
在本节中,我们将总结深度学习如何帮助解决现有的研究问题,如并行和非并行数据语音转换。
我们还将回顾深度学习如何在语音转换研究中开辟新领域。
5.1 用于帧对齐并行数据的深度学习
关于语音转换的深度学习方法的研究从并行训练数据开始,我们使用神经网络作为改进的回归函数来近似框架级映射范式下的框架映射函数 y= F(x) 。
1)DNN映射函数:
早期基于 DNN 的语音转换方法的研究主要集中在频谱变换上。
DNN 映射函数 y = F(x) 与其他统计模型如 GMM 和 DKPLS 相比有一些明显的优势。
例如,它允许源特征和目标特征之间的非线性映射,并且对要建模的特征维度几乎没有限制。
我们注意到,对其他声学特征的转换,如基频和能量轮廓,也可以进行类似的操作(《Pitch transformation in neural network based voice conversion》)。
Desai 等人(《Voice conversion using artificial neural networks》)提出了一种 DNN 来映射低维谱表示,如梅尔倒谱系数( MCEP ),从源说话人到目标说话人。
Nakashika 等人(《Voice conversion in high-order eigen space using deep belief NETS》)提出使用深度信念网( DBNs )从源和目标倒谱系数中提取潜在特征,并使用一层隐含的神经网络在潜在特征之间进行转换。
Mohammadi 等人(《Voice conversion using deep neural networks with speaker-independent pre-training》)通过研究来自多个发言者的深度自编码器,进一步发展了这一想法,从而得到语音频谱特征的紧凑表示。
光谱的高维表示也在最近的研究中被用于光谱映射(《Sequence error (SE) minimization training of neural network for voice conversion》),以及动态特征和参数生成算法(《Speech parameter generation algorithms for HMM-based speech synthesis》)。
Chen 等人(《Voice conversion using deep neural networks with layer-wise generative training》)提出通过分层生成训练分别对源说话人和目标说话人的谱包络分布进行建模。
一般来说,用于频谱和/或韵律转换的 DNN 需要大量来自成对说话者的并行训练数据,这并不总是可行的。
但它为我们利用源和目标之外的多个说话人的语音数据,更好地建模源和目标说话人,并发现更好的特征表示来进行特征映射提供了机会。
2)LSTM映射函数:
为了在语音转换中建立跨语音帧的时间相关性模型, Nakashika 等人(《High-order sequence modeling using speaker-dependent recurrent temporal restricted Boltzmann machines for voice conversion》)探讨了循环时间受限玻尔兹曼机器( RTRBM )的使用,这是一种循环神经网络。
LSTM ( Long-Short Term Memory, LSTM )(《Long short-term memory》,《Learning to forget: Continual prediction with LSTM》)在序列到序列建模中的成功,启发了 LSTM 在语音转换中的研究,提高了语音输出的自然性和连续性。
LSTM 网络架构由一组内存块和门组成,支持存储和访问远程上下文信息(《LSTM: A search space odyssey》)。
LSTM 可以学习用于语音转换的最佳上下文信息量。
双向 LSTM ( BLSTM )网络有望从正向序列和反向序列(《Personalized, crosslingual TTS using phonetic posteriorgrams》)中捕获序列信息并维护远程上下文特征。
Sun 等人(《Voice conversion using deep bidirectional long short-term memory based recurrent neural networks》)和 Ming 等人(《Deep bidirectional LSTM modeling of timbre and prosody for emotional voice conversion》)通过叠加 BLSTM 网络架构的多个隐藏层,提出了一种深度双向 LSTM 网络( Deep Bidirectional LSTM Network, DBLSTM ),即使不使用动态特征,其性能也优于 DNN 语音转换。
虽然基于 DBLSTM 的语音转换方法产生高质量的合成语音,但它通常需要大量的源说话人和目标说话人的语音语料库来进行训练,这限制了实际中的应用范围。
与 GMM 方法一样, DNN 和 LSTM 技术在训练数据准备过程中也依赖于外部帧对准器。
在运行时,转换过程遵循典型的三步流水线流程,在转换过程中不改变语音时长。
5.2 用于并行数据含有注意力机制的编码器-解码器
语音转换的研究问题主要围绕对齐和映射展开,这两个问题在训练和运行时推理时都是相互关联的。
在训练过程中,更精确的对齐有助于建立更好的映射函数,这就解释了为什么我们更喜欢平行的训练数据。
在运行时推理时,框架级映射范式在转换期间不会改变语音的持续时间。
虽然可以对语音转换输出的持续时间进行建模和预测,但系统地将持续时间模型和映射模型结合起来并不容易。
深度学习为这一研究问题提供了新的解决方案。
编码器-解码器结构神经网络中的注意机制(《Neural machine translation by jointly learning to align and translate》,《Attention is all you need》)带来范式变化。
注意力的概念首次成功地应用于机器翻译(《Neural machine translation by jointly learning to align and translate》)、语音识别(《Listen, attend and spell: A neural network for large vocabulary conversational speech recognition》)和序列对序列语音合成(《Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions》,《Tacotron: Towards end-to-end speech synthesis》,《Deep voice 3: 2000-speaker neural text-to-speech》,《Efficiently trainable textto-speech system based on deep convolutional networks with guided attention》),这导致了许多语音转换的平行研究(《Sequenceto-sequence acoustic modeling for voice conversion》,《AttS2S-VC: Sequence-to-sequence voice conversion with attention and context preservation mechanisms》)。
通过注意机制,神经网络在训练过程中同时学习特征映射和对齐。
在运行推断时,网络根据它所学的内容自动决定输出时间。换句话说,帧对齐器不再需要了。
有几种基于递归神经网络的变化,如序列到序列转换网络( SCENT )(《Sequenceto-sequence acoustic modeling for voice conversion》)和 AttS2S-VC (《AttS2S-VC: Sequence-to-sequence voice conversion with attention and context preservation mechanisms》)。
他们关注的是广泛使用的编解码器架构(《Learning phrase representations using RNN encoderdecoder for statistical machine translation》,《Effective approaches to attention-based neural machine translation》)。
假设我们有一个源语音 x = {x1, x2,…, xt} 。
编码器网络首先将输入特征序列转换为隐藏表示, h = {h1, h2,…, hTh} 以较低的帧率与 Th < Ts ,这是适合解码器处理的。
在每个解码器时间步长,注意模块根据注意概率聚合编码器输出并产生上下文向量。然后,解码器利用上下文向量逐帧预测输出的声学特征。
此外,设计了一个后滤波网络来提高转换后的声学特征的准确性,以生成转换后的语音 y = {y1, y2,…, yTy} 。
在训练过程中,注意机制学习源序列和目标序列之间的映射动态。
在运行推断时,解码器和注意力机制相互作用,同时执行映射和对齐。
整体架构如下图所示:

虽然递归神经网络是序列到序列转换的有效实现,但最近的研究表明,卷积神经网络也能很好地学习长期依赖关系(《Wavenet: A generative model for raw audio》,《Convolutional sequence to sequence learning》)。
它采用了一种注意机制,有效地使编码和解码的并行计算成为可能。
在解码过程中,因果卷积设计允许模型以自回归的方式产生输出序列。
Kameoka 等人提出了一种用于语音转换的卷积神经网络实现(《ConvS2S-VC: Fully convolutional sequence-to-sequence voice conversion》),称为 ConvS2S-VC 。
最近的研究表明, ConvS2S-VC 在成对和多对多语音转换方面都优于循环神经网络(《AttS2S-VC: Sequence-to-sequence voice conversion with attention and context preservation mechanisms》)。
带有注意力的编码器-解码器结构标志着与框架级映射范式的背离。
注意不执行逐帧映射,而是允许解码器处理多个语音帧,并在解码过程中使用软组合来预测输出帧。
在注意机制下,转换后的话语持续时间与源语话语持续时间有明显差异,反映了源语与目标语的说话风格差异。
这代表了一种同时处理光谱和韵律转换的方法。
研究将语音质量的提高归因于有效的注意机制。注意机制也代表了放松语音转换中并行数据的严格要求的第一步。
5.3 超越成对说话人的并行数据
在第三节和第四节中,我们研究了基于并行训练数据和非并行训练数据的语音转换统计建模。
深度学习的出现为语音转换研究开辟了新天地。
我们现在超越了平行和非平行训练数据的范例。
传统上,非并行训练数据指的是需要源-目标说话者对的非并行话语的情况。
然而,最近的研究表明,深度学习可以在不需要并行数据的情况下实现许多语音转换场景。
在本节中,我们将这些研究总结为四种场景:
1)成对说话者的非并行数据
2)利用 TTS 系统
3)利用 ASR 系统
4)将说话人从说话内容中解脱出来
5.3.1 成对说话人的非并行数据
非并行训练数据的语音转换是一项类似于图像-图像转换的任务(《Image-to-image translation with conditional adversarial networks》,《Unpaired image-to-image translation using cycle-consistent adversarial networks》,《Stargan: Unified generative adversarial networks for multi-domain image-to-image translation》,《Few-shot unsupervised image-to-image translation》,《Learning attribute representations with localization for flexible fashion search》),它是在不需要并行训练数据的情况下找到从源域到目标域的映射。
让我们来比较一下图像对图像翻译和语音转换之间的相似之处。
在图像翻译,我们想翻译一匹斑马,我们保护马的结构和改变马的外套的斑马(《Unpaired image-to-image translation using cycle-consistent adversarial networks》,《Attribute manipulation generative adversarial networks for fashion images》,《Deep learning approaches for attribute manipulation and textto-image synthesis》,《Efficient multiattribute similarity learning towards attribute-based fashion search》,《StarGAN v2: Diverse image synthesis for multiple domains》),在语音转换,我们想改变另一个声音,同时保留语言、韵律的内容。
CycleGAN 基于对抗学习的概念(《Generative adversarial NETS》),即训练生成模型在两个神经网络(称为生成器( G )和判别器( D ))之间的最小-最大博弈中寻找解。
众所周知,在一些不存在成对训练数据的任务上,如图像处理和合成(《Unpaired image-to-image translation using cycle-consistent adversarial networks》,《Deep learning approaches for attribute manipulation and textto-image synthesis》,《Multimodal unsupervised image-to-image translation》,《Toward multimodal image-to-image translation》,《Semantically consistent text to fashion image synthesis with an enhanced attentional generative adversarial network》,《Semantically consistent hierarchical text to fashion image synthesis with an enhanced-attentional generative adversarial network》,《High-resolution image synthesis and semantic manipulation with conditional gans》)、语音增强(《Cycle-consistent speech enhancement》)、语音识别(《Cross-domain speech recognition using nonparallel corpora with cycle-consistent adversarial networks》)、语音合成(《Voice conversion using conditional cyclegan》,《Speech synthesis of children s reading based on cycleGAN model》)和音乐翻译(《TimbreTron: A wavenet (cycleGAN (CQT (audio))) pipeline for musical timbre transfer》),它都能取得显著的效果(《Unpaired image-to-image translation using cycle-consistent adversarial networks》)。
由于语音数据是非并行的,很难实现对齐。 Kaneko 和 Kameoka 首先研究了 CycleGAN (《Highquality nonparallel voice conversion based on cycle-consistent adversarial network》,《Parallel-data-free voice conversion using cycle-consistent adversarial networks》,《CycleGAN-VC: Non-parallel voice conversion using cycle-consistent adversarial networks》,《Cycle GANVC2: Improved cycle GAN-based non-parallel voice conversion》),其中包含三个损失函数:对抗损失、周期一致性损失和身份映射损失,以学习源和目标说话人之间的正向和反向映射。
对抗性损失衡量了如何区分转换特征和源特征 x 或目标特征 y 的数据分布。对于正向映射,它的定义如下:

转换后的数据分布与目标数据分布越接近,损失越小。
对抗性损失只告诉我们 GX→Y 是否遵循目标数据的分布,并不能确保上下文信息(代表我们希望从源传递到目标的一般句子结构)得到保留。
为了保证 x 和 GX→Y (x) 之间的上下文信息保持一致,引入了循环一致性损失,如下图所示:
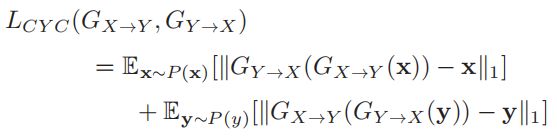
其中 || · ||1 为 L1 范数函数,即已知能产生更清晰的光谱特征的最小绝对误差。
这种损失鼓励 GX→Y 和 GY→X 通过循环转换找到最佳的伪对 (X, Y) 。
为了鼓励生成器找到保留输入和输出之间潜在语言内容的映射(《Unsupervised cross-domain image generation》),引入了身份映射损失,如下所示:

结合这三种损失函数,我们可以得到 CycleGAN (《Parallel-data-free voice conversion using cycle-consistent adversarial networks》)的整体损失函数(《CycleGAN-VC: Non-parallel voice conversion using cycle-consistent adversarial networks》)。
CycleGAN 代表了一个成功的深度学习实现,从成对说话者的非并行数据中找到最优伪对。
它不需要任何帧对齐机制,如动态时间弯曲或注意。
实验结果表明,在非并行训练数据下, CycleGAN 的训练性能与基于 GMM 的系统在两倍并行数据上的训练性能相当。
此外,通过对抗性训练,有效地克服了过平滑问题,这是导致语音质量下降的主要因素之一。
我们注意到,最近研究了 CycleGAN-VC2 ( CycleGAN-VC 的改进版本(《Cycle GANVC2: Improved cycle GAN-based non-parallel voice conversion》)),它通过合并三种新技术进一步改进了 CycleGAN :改进的目标(两步对抗损失)、改进的生成器( 2-1-2D CNN )和改进的鉴别器( PatchGAN )。
CycleGAN 已成功应用于单语(《Highquality nonparallel voice conversion based on cycle-consistent adversarial network》,《Voice conversion with cyclic recurrent neural network and fine-tuned wavenet vocoder》)、跨语语音转换(《On the study of generative adversarial networks for cross-lingual voice conversion》)、情感语音转换(《Transforming spectrum and prosody for emotional voice conversion with non-parallel training data》,《Converting anyone s emotion: Towards speaker-independent emotional voice conversion》)和灵活节奏语音转换(《Rhythm- flexible voice conversion without parallel data using cycle-GAN over phoneme posteriorgram sequences》)。
与编码器-解码器结构不同, CycleGAN 遵循生成建模体系结构,该体系结构不显式地为一些内部表示建模,以支持灵活的操作,如语音标识、语音持续时间和情感。
因此,它更适合于特定源对和目标对之间的语音转换。
尽管如此,它代表了非并行数据语音转换的一个重要里程碑。
5.3.2 利用 TTS 系统
我们已经讨论了不涉及文本的语音转换的深度学习架构。
语音转换的一个重要方面是将语言内容从源语传递到目的语。
语音转换和 TTS 系统在某种意义上是相似的,它们都以产生具有适当语言内容的高质量语音为目标。
TTS 系统为语音遵循语言内容提供了一种机制。
利用 TTS 机制的想法可以通过不同的方式来激励。
首先,在一个大型语音数据库上训练 TTS 系统,在给定语言内容的基础上提供高质量的语音重建机制;其次, TTS 系统具有语音转换所需的质量注意机制。
编码器-解码器模型的关注,最近显示了相当大的成功建模各种复杂的序列-序列问题。
Tacotron (《Teacher-student training for robust tacotron-based TTS》,《Tacotron: Towards end-to-end speech synthesis》,《WaveTTS: Tacotron-based TTS with joint time-frequency domain loss》,《Modeling prosodic phrasing with multi-task learning in tacotron-based TTS》,《Expressive TTS training with frame and style reconstruction loss》)代表了一种成功的文本到语音( TTS )实现,它已经扩展到语音转换(《Joint training framework for text-to-speech and voice conversion using multi-source tacotron and wavenet》,《Sequenceto-sequence acoustic modeling for voice conversion》,《Transfer learning from speech synthesis to voice conversion with non-parallel training data》)。
利用 TTS 知识的策略建立在下图所示的共享注意力知识和/或共享解码器架构的思想之上。
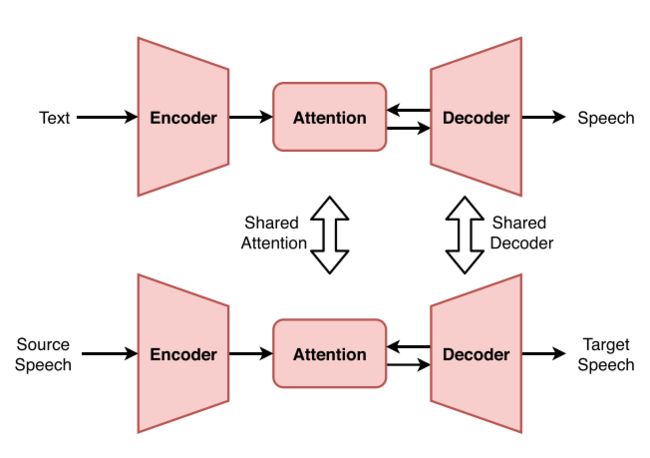
Zhang 等人(《Transfer learning from speech synthesis to voice conversion with non-parallel training data》)提出了一种语音转换网络迁移学习技术,该技术从 TTS 注意机制衍生的语音上下文向量进行学习,并与 TTS 系统共享解码器,是这种杠杆的典型例子。
Zhang 等人在扩展 Tacotron 模型体系结构的基础上,提出了文本-语音和语音转换联合训练系统体系结构,该体系结构具有双输入、双注意机制的多源序列-序列模型。
该系统仅以文本作为输入,进行语音合成。
该系统也可以单独使用语音,或同时使用文本和语音,表示为混合 TTS & VC ,作为语音转换的输入。
使用通过 TTS 联合训练获得语言信息的解码器对多源编解码器模型进行训练,如上图中的共享解码器所示。
实验表明,联合训练在运行推断时对语音转换任务有无文本输入都有一定的改善。
Park 等人提出了一种名为 Cotatron 的语音转换系统,该系统建立在多扬声器 Tacotron TTS 架构之上(《Cotatron: Transcription-guided speech encoder for any-to-many voice conversion without parallel data》)。
在运行时推理时,使用预先训练的 TTS 系统来推导源语音的说话人无关的语言特征。
这个过程是由输入语音的转录来指导的,因此,在运行时推理时需要源语音的文本转录。
该系统使用 TTS 编码器提取与说话人无关的语言特征,或解开说话人身份。
解码器以与注意一致的说话人无关的语言特征为输入,以目标说话人身份为条件,生成目标说话人的声音。
这样,语音转换就利用了 TTS 的注意机制或共享注意,如上图所示。
Cotatron 的设计是为了执行一对多的语音转换。一项研究(《Voice transformer network: Sequence-to-sequence voice conversion using transformer with text-to-speech pretraining》)与(《Cotatron: Transcription-guided speech encoder for any-to-many voice conversion without parallel data》)有着相似的动机,但该研究基于 Transformer 而不是 Tacotron ,建议从学习过的 TTS 模型中转移知识,从而从大规模、易于访问的 TTS 语料中获益。
Zhang 等(《Improving sequence-to-sequence voice conversion by adding textsupervision》)提出在训练过程中使用文本监督对序列到序列模型(《Sequenceto-sequence acoustic modeling for voice conversion》)进行改进。
设计了一种多任务学习结构,在序列对序列模型的中间层添加辅助分类器,将语言标签预测作为第二任务。
语言标签可以通过手动或自动校准工具获得。
与语言标号目标,编码器和解码器被期望产生有意义的中间表示是语言通知。文本文本只在训练期间需要。
实验表明,使用语言标签进行多任务学习可以有效地提高模型的对齐质量,从而缓解发音错误等问题。
深度学习的神经表征促进了 TTS 和语音转换之间的交互。
通过利用 TTS 系统,我们希望通过坚持语言内容来改进语音转换的训练和运行时推理。
然而,这类技术通常需要大量的训练语料库。
最近的研究引入了一个框架,用于创建有限数据 VC 系统(《Voice transformer network: Sequence-to-sequence voice conversion using transformer with text-to-speech pretraining》,《Bootstrapping non-parallel voice conversion from speaker-adaptive text-to-speech》,《Nautilus: A versatile voice cloning system》),通过自举从扬声器自适应 TTS 模型。
关于语音转换如何在不涉及大量训练数据的情况下从 TTS 系统中受益,值得未来的研究。
5.3.3 利用 ASR 系统
用于语音转换的深度学习方法通常需要一个大型的平行语料库来进行训练。
这部分是因为我们想要学习描述语音系统的潜在表示法。
对训练数据的要求限制了潜在应用的范围。
我们知道,大多数 ASR 系统已经用大量的语料库进行了训练。
它们已经用不同的方式很好地描述了语音系统。
问题是如何利用 ASR 系统中的潜在表示进行语音转换。
其中一个想法是使用序列到序列学习的 ASR 模型产生的上下文后验概率序列来生成目标语音特征序列(《Voice conversion using sequence-to-sequence learning of context posterior probabilities》)。
在该模型中,除了使用语音识别器作为编码器,语音合成器作为解码器外,系统具有与前文类似的编解码器结构。
另一项研究是通过 ASR 系统来指导序列到序列语音转换模型,该系统用瓶颈特征来增强输入(《Sequenceto-sequence acoustic modeling for voice conversion》。
最近,一种端到端的语音到语音序列换向器 Parrotron (《Parrotron: An end-to-end speech-to-speech conversion model and its applications to hearing-impaired speech and speech separation》)被研究。
Parrotron 学习将任何有多个口音和缺陷的说话者的语音图谱转换为单个预定义目标说话者的声音。
Parrotron 通过使用辅助 ASR 解码器来实现这一点,以编码器潜在表示为条件来预测输出语音的文本。
Parrotron 的多任务训练优化解码器生成目标语音,同时约束潜在表示只保留语言信息。
ASR 解码器的目的是将说话者的身份从语音中分离出来。上述技术均采用了具有注意力结构的编解码器。
语音转换的另一种方法是,语音由两个组成部分组成,即说话人依赖的组成部分和说话人独立的组成部分。
如果我们能够将语音信号分解为这两种成分,我们就可以继续保留前者,而只对后者进行转换才能实现语音转换。
平均建模技术代表了(《On the use of I-vectors and average voice model for voice conversion without parallel data》)的成功实现之一,其中我们构建了一个映射函数来将语音后图(《Phonetic posteriorgrams for many-to-one voice conversion without parallel data training》)[转换为声学特征。
PPG 特性来源于 ASR 系统,可以认为是说话人独立的。
我们从多说话人,非并行语音数据训练映射函数。这样,就不需要为每个目标说话者训练一个完整的转换模型。在目标语音量较小的情况下,该平均模型可以适用于目标语音。
平均模型的训练和适应如下图所示:

沿着这个方向还有一些后续研究,例如, Tian 等人提出了 PPG 到波形的转换(《A speaker-dependent wavenet for voice conversion with non-parallel data》),以及将说话人身份作为条件(《Average modeling approach to voice conversion with non-parallel data》)的平均模型(《Frontend factor analysis for speaker verification》)。
Zhou 等人提出使用 PPG 作为跨语言语音转换的语言特征(《Cross-lingual voice conversion with bilingual phonetic posteriorgrams and average modeling》)。
Liu 等人提出将 PPG 用于情感语音转换(《Multi-target emotional voice conversion with neural vocoders》)。
Zhang 等人还表明,平均模型框架可以从使用误差减少网络的少量并行训练数据中受益(《Error reduction network for DBLSTM-based voice conversion》)。
5.3.4 将说话人从说话内容中解脱出来
在语音转换的语境中,语音可以看作是说话人语音身份和语言内容的组成部分。
如果我们能够将说话人从语言内容中解脱出来,我们就可以独立于语言内容改变说话人的身份。
自动编码器(《Autoencoding beyond pixels using a learned similarity metric》)是语音解缠和重构的常用技术之一。
还有其他一些技术,如实例归一化(《One-shot voice conversion by separating speaker and content representations with instance normalization》)和矢量量化(《One-shot voice conversion by vector quantization》,《Vqvc+: One-shot voice conversion by vector quantization and u-net architecture》),可以有效地将说话人从内容中分离出来。
自动编码器学习将输入复制为输出。因此,不需要并行训练数据。
编码器学习用隐码表示输入,解码器学习从隐码重建原始输入。
潜在代码可以看作是一个信息瓶颈,一方面让我们传递必要的信息,如与说话人无关的语言内容,以实现完美的重构,另一方面又迫使一些信息被丢弃,如说话人、噪声和信道信息(《Unsupervised learning of disentangled and interpretable representations from sequential data》)。
变分自编码器( VAE )(《Auto-encoding variational bayes》)是自编码器的随机版本,它是编码器在潜在表示上产生分布,而不是确定的潜在码,而解码器则根据这些分布的样本进行训练。
变分自编码器比确定性自编码器更适合于合成新样本。
Chorowski 等人(《Unsupervised speech representation learning using wavenet autoencoders》)通过研究三种自编码神经网络如何从语音数据中学习表示,从而将说话人身份从语言内容中分离出来,提供了对三种自编码器的一种比较。
研究表明,离散表示,即从 VQ-VAE (《Neural discrete representation learning》,《Generating diverse high- fidelity images with vq-vae-2》)获得的潜码,保留了最多的语言内容,同时也是最具说话人不变性的。
最近,为了改进编码过程,研究了一种 VQ-VAE 的群潜伏嵌入技术,该技术将嵌入字典分组,使用最近群原子的加权平均作为潜伏嵌入(《Group latent embedding for vector quantized variational autoencoder in non-parallel voice conversion》)。
基于 VAE 概念的语音转换框架(《Voice conversion from non-parallel corpora using variational auto-encoder》)如下图所示。
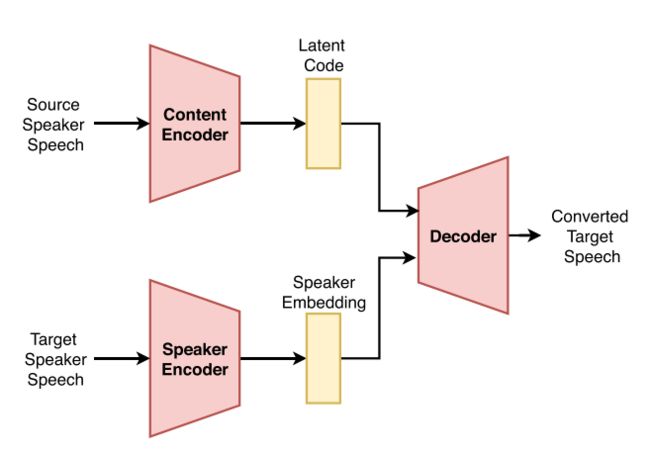
译码器本身潜在的话语通过调节编码器的代码提取出来,并分别在说话人编码,这可能是一个独热向量(《Voice conversion from non-parallel corpora using variational auto-encoder》,《Voice conversion based on cross-domain features using variational auto encoders》)为一组说话人,或一个 i-vector (《Frontend factor analysis for speaker verification》,《Many-to-many voice conversion based on bottleneck features with variational autoencoder for non-parallel training data》)瓶颈说话人表示,或 d-vector (《Non-parallel voice conversion using variational autoencoders conditioned by phonetic posteriorgrams and D-vectors》)的开放式说话人。
通过显式地使解码器适应于说话人身份,编码器被迫从多说话人数据库中捕获潜在代码中与说话人无关的信息。
就像其他自动编码器一样, VAE 解码器往往产生过平滑的语音。
这对于语音转换来说是有问题的,因为网络可能会产生质量较差的嗡嗡声。
生成对抗网络( GANs )(《Unsupervised representation disentanglement using cross domain features and adversarial learning in variational autoencoder based voice conversion》)被提出作为过度平滑问题的解决方案之一(《Sequence-tosequence voice conversion with similarity metric learned using generative adversarial networks》)。
GANs 提供了一个训练数据生成器的一般框架,它可以欺骗试图区分生成器产生的真实数据和虚假数据的真/假鉴别器(《Self-attention generative adversarial networks》,《Coupled generative adversarial networks》,《Edge-GAN: Edge conditioned multi-view face image generation》)。
将 GAN 概念融入 VAE 中,研究了 VAE-GAN 在非并行训练数据(《Voice conversion from unaligned corpora using variational autoencoding Wasserstein generative adversarial networks》)下的语音转换和跨语言语音转换(《On the study of generative adversarial networks for cross-lingual voice conversion》)。
研究表明, VAE- GAN (《Unsupervised representation disentanglement using cross domain features and adversarial learning in variational autoencoder based voice conversion》)比标准的 VAE 方法(《Voice conversion from non-parallel corpora using variational auto-encoder》,《Many-to-many voice conversion based on bottleneck features with variational autoencoder for non-parallel training data》)产生更自然的发音。
最近一项关于序列到序列非并行语音转换的研究(《Transferring source style in non-parallel voice conversion》)表明,可以明确地模拟语音的其他方面,如源节奏、说话风格和情感到目标语音的转换。
6 语音转换评价
有效的语音质量评估需要验证算法,衡量技术进步,并与最先进的系统进行基准测试。
通常,我们会根据客观和主观的衡量来报告结果。
为了提供一个客观的评价,需要一个参考的演讲。
常见的客观评价指标包括频谱的梅尔倒谱失真( MCD )(《Mel-cepstral distance measure for objective speech quality assessment》),韵律的 PCC (《Pearson correlation coefficient》)和 RMSE (《Root mean square error (RMSE) or mean absolute error (MAE)? Arguments against avoiding RMSE in the literature》,《Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance》,《Speech quality assessment》)。
我们注意到,这些指标并不总是与人类的感知相关,部分原因是它们测量的是声音特征的失真,而不是人类实际听到的波形。
主观评价指标,如平均意见评分( MOS )(《Spectral voice conversion for text-to-speech synthesis》,《Mean opinion score (MOS) revisited: Methods and applications, limitations and alternatives》,《Optimization of an objective measure for estimating mean opinion score of synthesized speech》,《Measuring speech quality for text-to-speech systems: Development and assessment of a modified mean opinion score (MOS) scale》),偏好测试(《Exemplar-based sparse representation with residual compensation for voice conversion》,《Design and evaluation of a voice conversion algorithm based on spectral envelope mapping and residual prediction》)和最好-最差标度(《Best worst scaling: Theory and methods》)可以代表内在的自然性和与目标的相似度。
我们注意到,主观评价要有意义,需要大量的听众,但在实践中并不总是可能的。
6.1 客观评价
1)频谱转换:
为了提供一个客观的评价,首先我们需要一个目标说话人所说的参考话语。
理想情况下,转换后的语音与参考语音非常接近。
我们可以通过比较它们的光谱距离来测量它们之间的差异。但是,不能保证转换后的语音和参考语音的长度相同。
在这种情况下,需要一个帧对齐器来建立帧级映射。
梅尔谱失真( MCD )(《Mel-cepstral distance measure for objective speech quality assessment》)[246]常用来测量两个光谱特征之间的差异(《Group sparse representation with WaveNet Vocoder adaptation for spectrum and prosody conversion》,《The voice conversion challenge》,《Deepconversion: Voice conversion with limited parallel training data》,《Phone-aware LSTM-RNN for voice conversion》)。
它计算之间的转换和目标梅尔倒谱系数,或 MCEPs ,(《Articulatory features for expressive speech synthesis》,《Mel frequency cepstral coefficients for music modeling》) , y 和 y. 。
假设每个 MCEP 向量由 24 个系数,我们有 y = {mc k, i} 和 y ={mtk, i} 帧 k , i 表示转换和目标 MCEPs 第 i 个系数。
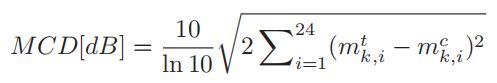
我们注意到,较低的 MCD 表示较好的性能。
然而, MCD 值并不总是与人类感知相关。
因此,也会进行主观评价,如 MOS 和相似度评分。
2)韵律转换:
语音韵律的特征是语音时长、能量轮廓和音高轮廓。
为了有效测量转换语音的韵律模式与参考语音的接近程度,我们需要对这三个方面进行测量。
转换后的语音和参考语音之间的对齐提供了有关语音持续时间彼此差异有多大的信息。
我们可以推导出平均偏离理想对角线路径的帧数,例如帧干扰(《Perceptual evaluation of singing quality》),以报告语音持续时间的差异。
皮尔逊相关系数( PCC )(《Group sparse representation with WaveNet Vocoder adaptation for spectrum and prosody conversion》,《Transforming spectrum and prosody for emotional voice conversion with non-parallel training data》)和均方根误差( RMSE )已被广泛用于评价两个话语之间的韵律轮廓或能量轮廓的线性相关性。
接下来我们以两个韵律轮廓的测量为例。转换后的对齐对与目标 F0 序列之间的 PCC 如下所示:
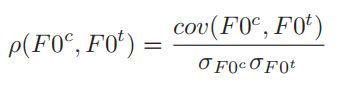
其中 σF0c 和 σF0t 分别为转换后的 F0 序列( F0c )和目标 F0 序列( F0t )的标准差。
我们注意到 PCC 值越高, F0 转换性能越好。
转换后的 F0 和对应的目标 F0 之间的 RMSE 定义为:

其中 F0ck 和 F0tk 分别表示转换后的 F0 特征和目标 F0 特征。 K 是 F0 序列的长度,即帧的总数。
我们注意到一个较低的 RMSE 值代表更好的 F0 转换性能。同样的测量方法也适用于能量轮廓。
其他被普遍接受的韵律传递指标包括 F0 帧误差( FFE )(《Reducing F0 frame error of F0 tracking algorithms under noisy conditions with an unvoiced/voiced classification frontend》)和总节距误差( GPE )(《A method for fundamental frequency estimation and voicing decision: Application to infant utterances recorded in real acoustical environments》)。
我们注意到 GPE 报告其音高值超过 20% 与参考值不同的浊音帧的百分比,而 FFE 报告包含 20% 音高错误或语音判定错误的帧的百分比(《Towards end-to-end prosody transfer for expressive speech synthesis with tacotron》)。
6.2 主观评价
平均意见得分( Mean Opinion Score, MOS )在听力考试(《The NU-naist voice conversion system for the voice conversion challenge 2016》,《Voice conversion using deep bidirectional long short-term memory based recurrent neural networks》,《A voice conversion framework with tandem feature sparse representation and speaker-adapted wavenet vocoder》,《Group sparse representation with WaveNet Vocoder adaptation for spectrum and prosody conversion》,《On the analysis and evaluation of prosody conversion techniques》,《Transformation of spectral envelope for voice conversion based on radial basis function networks》,《Crosslingual voice conversion-based polyglot speech synthesizer for indian languages》,《Robust processing techniques for voice conversion》,《Spectral mapping using artificial neural networks for voice conversion》)中得到了广泛的应用。
在 MOS 实验中,听者用 5 分制对转换后的声音质量进行评分: 5 分制为优秀, 4 分制为良好, 3 分制为一般, 2 分制为差, 1 分制为差。
有几种评估方法与 MOS 类似,例如:1) DMOS 结构(《Speaker adaptation for HMM-based speech synthesis system using MLLR》,《Low-complexity, nonintrusive speech quality assessment》,《Are we using enough listeners? No! an empirically-supported critique of interspeech 2014 TTS evaluations》),这是一种退化或差分 MOS 测试,要求听众率样本对该引用;2) MUSHRA (《Potential biases in MUSHRA listening tests》,《Voice conversion using GMM with enhanced global variance》,《On the analysis of training data for wavenet-based speech synthesis》),即多个刺激隐藏参考和锚,并要求参与者少于 MOS 获得统计上显著的结果。
另一种流行的主观评价方法是偏好测验,也称 AB/ABX 测验(《Spectral voice conversion for text-to-speech synthesis》,《Voice conversion using deep bidirectional long short-term memory based recurrent neural networks》,《Text-independent voice conversion based on state mapped codebook》)或 XAB 测验(《Voice conversion based on maximum-likelihood estimation of spectral parameter trajectory》,《Voice conversion algorithm based on piecewise linear conversion rules of formant frequency and spectrum tilt》)。
在 AB 测试中,给听者提供两个语音样本,要求听者指出哪一个具有更多的某种属性;例如,就自然性或相似性而言。
在 ABX 检验中,与 AB 检验类似,给出两个样本,但也给出一个额外的参考样本。
听众需要判断 A 或 B 是否更像X的自然程度、相似性,甚至情感品质(《Transforming spectrum and prosody for emotional voice conversion with non-parallel training data》)。
在 XAB 测试中,先将原始目标语音样本呈现给听者,然后随机生成一对转换后的语音。
我们注意到同时使用 AB 、 ABX 或 XAB 测试来比较多个 VC 系统是不实际的。
MUSHRA 是电信语音质量测试的另一种类型(《1534-1, Method for the subjective assessment of intermediate sound quality (MUSHRA)》),其中参考自然语音和其他几个相同内容的转换样本以随机顺序呈现给听众。
听众被要求在 0 到 100 之间对每个样本的语音质量进行评分。
众所周知,人们善于选择极端情况,但当面对一长串选项时,他们对介于两者之间的事物的偏好可能是模糊和不准确的。
针对语音转换质量评估(《Sparse representation of phonetic features for voice conversion with and without parallel data》),提出了最佳最差尺度( BWS )(《Best worst scaling: Theory and methods》),每次只向听众提供几个随机选择的选项。
有了许多这样的 BWS 决策,最佳最差扩展可以处理一长串选项,并产生比 MOS 和偏好测试更具区别性的结果,如语音质量排名。
我们注意到主观度量可以代表语音转换系统的内在自然性和相似性。
然而,这样的评估可能是耗时和昂贵的,因为它们涉及大量的听众。
6.3 使用深度学习方法进行评估
知觉质量评价的研究试图利用心理声学动机的计算模型来近似人的判断。
它提供了关于人类如何在听力测试中感知语音质量的见解,并提出了在语音通信、语音增强、语音合成、语音转换和任何其他语音产生或传输应用中所需要的评估指标。
语音质量感知评价( PESQ )(《Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs》)是 ITU-T 的推荐标准,被广泛应用于行业标准。它提供了客观的语音质量评价,预测了人类感知到的语音质量。
然而, PESQ 公式需要参考语音的存在,这在很大程度上限制了它在语音转换应用中的使用,并激发了不需要参考语音的知觉评价研究。
那些不需要参考语音的度量被称为非侵入性评价度量。
例如, Fu 等人提出了 Quality-Net (《Quality-net: An endto-end non-intrusive speech quality assessment model based on BLSTM》),它是预测 PESQ 评级的端到端的模型,是人类评级的代理。
Yoshimura 等人(《A hierarchical predictor of synthetic speech naturalness using neural networks》)、Patton等人(《AutoMOS: Learning a non-intrusive assessor of naturalness-of-speech》)提出了一种基于 CNN 的自然预测器来预测人类 MOS 评分,以及其他非侵入性评估指标(《An evaluation of synthetic speech using the PESQ measure》,《Prediction of perceived sound quality of synthetic speech》,《Objective evaluation measures for speaker-adaptive HMM-TTS systems》)。
Lo 等人(《MOSNET: Deep learning based objective assessment for voice conversion》)[285]提出了另一种基于深度神经网络的非侵入性评估技术 MOSNet ,它学习预测人类 MOS 评分。
MOSNet 评分在系统水平上与人类 MOS 评分高度相关,在言语水平上与人类 MOS 评分高度相关。
虽然 MOSNet 是一种非侵入性的自然度评价指标,但它也可以被修改和重新用于预测目标语音和转换语音之间的相似度评分。
它为 VCC 2018 数据集上的人类评分提供具有公平相关值的相似度评分。
MOSNet 标志着自动感知质量评估(《Comparison of speech representations for automatic quality estimation in multi-speaker text-tospeech synthesis》)的最新进展,它是免费和开源的。
最后但并非最不重要的是, Frechet 深度语音距离( FDSD , cFDSD )和核深度语音距离( KDSD , cKDSD )都被发现与语音生成的 MOS 有很好的相关性(《High fidelity speech synthesis with adversarial networks》)。
我们注意到 Frechet 深层语音距离是由 Frechet 初始距离( FID )(《GANs trained by a two time-scale update rule converge to a local Nash equilibrium》)所激发的,而内核深层语音距离是由内核初始距离( KID )(《Demystifying MMD GANs》)所激发的。
在这两个框架中,用于评估语音生成的 DeepSpeech 音频识别网络已经取代了最初的图像识别网络。
7 声音转换的挑战
在本节中,我们将概述一系列语音转换挑战,这些挑战使用公共数据集和评估指标为算法的公平比较提供共享任务。
语音转换挑战赛( VCC )自 2016 年开始,每年举办两次。
在挑战中,组织者提供一个公共数据库。参与者使用自己的技术建立语音转换系统,组织者评估转换后的语音的表现。
主要的评估方法是一种听力测试,在这种测试中,众包评估者会对演讲者的自然度和相似度进行排名。
2016 年的挑战提供了使用并行训练数据库的标准语音转换任务(《The voice conversion challenge》)。
2018 年的挑战包括使用非并行数据库的更高级的转换场景(《The voice conversion challenge 2018: Promoting development of parallel and nonparallel methods》)。
2020 年的挑战提出了一个跨语言语音转换研究问题。
VCC 2016 、 VCC 2018 和 VCC 2020 的总结见下表。

7.1 使用深度学习方法进行评估
如前所述,许多语音转换方法都是数据驱动的,因此需要语音数据来训练模型和进行转换评估。
为了精确地比较这些数据驱动的方法,需要一个明确指定培训和评估数据的公共数据库。
然而,这种通用数据库直到 2016 年才存在。在没有通用数据库的情况下,研究人员在尝试任何新想法之前,必须用自己的数据库重新实现其他系统。
在这种情况下,不能保证重新实现的系统在原工作中达到预期的性能。
为了解决同样的问题, TTS 社区在 2005 年推出了第一个暴雪挑战。
从那时起,这个挑战定义了各种 TTS 标准数据库,并使 TTS 的比较更加公平和容易。
VCC 的动机与暴雪挑战完全相同。 VCC 介绍了一些用于语音转换的标准数据库,并定义了常用的训练和评估协议。
所有参赛者为挑战提交的转换演讲都已公开发布。
通过这种方式,研究人员可以将他们的语音转换系统的性能与其他最先进的系统进行比较,而不需要重新实现。
另一个对语音转换标准数据库的需求来自于生物特征说话人识别领域。
由于语音转换技术可能被误用攻击说话人验证系统,需要有抗欺骗干扰对策(《Spoofing and countermeasures for speaker verifi- cation: A survey》)。这也称为表示攻击检测。
反欺骗技术旨在区分生物识别认证系统的虚假人工输入和真实输入。
如果有足够的关于欺骗数据的知识和数据,可以构造一个二进制分类器来拒绝人工输入。
因此,常用的 VCC 数据库对于防欺骗研究也很重要。
利用来自高级语音转换系统的许多转换语音数据,生物识别领域的研究人员可以开发抗欺骗模型,以加强对说话人识别系统的防御,并评估其漏洞。
7.2 2016 语音转换挑战概述
我们首先概述 2016 年语音转换挑战(The voice conversion challenge)及其数据集。
VCC 2016 定义了并行语音转换任务及其评估协议,作为语音转换中的第一个共享任务。
平行数据集包含 162 个由源和目标说话人说出的常见句子。
目标语和源语分别是四个以美国英语为母语的人(两位女性和两位男性)。
在挑战中,参与者开发转换系统并为所有可能的源-目标对组合产生转换语音。
VCC 2016 数据库中总共包含了 8 位发言者(加上 2 位未使用的发言者)。用于评价的测试句数为 54 。
排名采用的评价方法主要是对转换样本与目标说话人的感知自然度和说话人相似度进行主观评价。
自然度的评估使用标准的五分制平均意见评分( MOS )测试,范围从 1 (完全不自然)到 5 (完全自然)。
使用相同/不同的范式对说话人相似性进行评估(《Analysis of the voice conversion challenge 2016 evaluation results》)。
实验对象被要求听两个音频样本,然后用四个分制来判断它们是否是同一位说话者发出的语音信号:相同,绝对确定,不确定,不同。
由于感知到的说话人与目标说话人的相似度和感知到的语音质量并不一定相关,因此使用散点图来观察这两个方面之间的权衡是很重要的。
在 2016 年的挑战中, 17 名参与者提交了他们的转换结果。两百名英语母语的听众参加了听力测试。
据报道,采用 GMM 和波形滤波的最佳系统在自然度判断的 5 点尺度评估中平均获得 3.0 ,其转换后的语音样本约 70% 被听者判断为与目标说话人相同。
但是,也证实了目标自然语音与转换语音之间仍有很大的差距。
我们观察到,在当时,实现良好的质量和说话人相似度仍然是一个未解决的挑战。
更多 VCC 2016 的细节可以在(《Analysis of the voice conversion challenge 2016 evaluation results》)找到。最佳性能系统的细节在(《The NU-naist voice conversion system for the voice conversion challenge 2016》)中报告。
7.3 2018 语音转换挑战概述
接下来,我们概述了 2018 年语音转换挑战(《The voice conversion challenge 2018: Promoting development of parallel and nonparallel methods》)及其数据集。
VCC 2018 提供了两个任务,并行和非并行语音转换任务。为每个任务定义一个数据集及其评估协议。
并行转换任务的数据集与 2016 年挑战的数据集相似,除了它有较少的由源和目标说话人发出的常见话语。
目标和源说话人分别是四个以美国英语为母语的人(两个女性和两个男性),但是,他们与 2016 年挑战使用的使用者不同。
与 2016 年的挑战一样,参与者被要求开发转换系统,并为所有可能的源-目标组合生成转换后的数据。
VCC 2018 首次引入非并行语音转换任务。将并行任务中的同一目标说话者数据作为目标。
然而,与平行转换任务不同的是,源说话人是四个以美国英语为母语的人(二女二男),他们的话语也与目的语者有所不同。
与并行语音转换任务类似,所有可能的源-目标对组合的转换数据都需要由参与者生成。
2018 年 VCC 数据库共收录了 12 位发言者。每个源和目标演讲者都有一组 81 句的训练数据,这是 VCC 2016 的一半。用于评价的测试句数为 35 个。
在 2018 年的挑战中, 23 名参与者向并行转换任务提交了他们的转换结果,其中 11 人额外参与了非并行转换任务。 2018 年挑战赛采用了与 2016 年挑战赛相同的评估方法,共有 260 名以英语为母语的大众听众参加了听力测试。
据报道,在这两个任务中,最好的系统使用电话编码器和神经声编码器获得了平均 4.1 在 5 点尺度评估的自然性判断和大约 80% 的转换语音样本被听者判断为目标说话人相同。
也有报道称,与文献报道的结果相比,最好的系统在并行和非并行任务中都有类似的性能。
在 VCC 2018 中,引入了欺骗干扰对策,作为对语音质量主观评价的补充,汇聚了语音转换和说话人验证研究社区。
有关 2018 年挑战的更多细节可参见(《The voice conversion challenge 2018: Promoting development of parallel and nonparallel methods》)。(《The NU non-parallel voice conversion system for the voice conversion challenge 2018》,《Wavenet vocoder with limited training data for voice conversion》)报道了性能最好的系统的细节。
从这一挑战中,我们观察到新的语音波形产生范式,如小波网和电话编码,为语音转换领域带来了重大进展。
后续的文献(《Sequence-to-sequence acoustic modeling for voice conversion》,《Non-parallel sequence-to-sequence voice conversion with disentangled linguistic and speaker representations》)取得了进一步的改进,新的 VC 系统超过了挑战的最佳性能已经被报道。
7.4 2020 语音转换挑战概述
2020 语音转换挑战(《Voice conversion challenge 2020: Intra-lingual semiparallel and cross-lingual voice conversion》)包括两个任务:1)同一语言(英语)的非并行训练;2)不同语言的非平行培训(英语芬兰语、英语德语和英语普通话)。
在第一个任务中,每个参与者使用多达 70 个话语(包括 20 个英语平行话语和 50 个英语非平行话语)作为训练数据,训练所有源和目标说话者对的语音转换模型。
总的来说,将开发 16 个语音转换模型(即 4 个源 4 个目标)。在第二个任务中,每个参与者为所有源和目标说话者对开发语音转换模型,每个说话者最多使用 70 个话语(即,源说话者使用英语,目标说话者使用芬兰语、德语或汉语)作为训练数据。总的来说,将发展 24 个转换系统(即 4 个来源和 6 个目标)。
在 2020 挑战中, 31 名参与者向第一个任务提交了结果, 28 名参与者向第二个任务提交了结果。
参与者被允许混合和组合不同的源说话者数据,以训练说话者独立的模型。
此外,参与者还可以使用已发布的训练数据的正字法抄写来开发他们的语音转换系统。
最后,参与者可以自由地对发布的训练数据进行手工标注,可以有效地提高转换后的语音质量。
2020 年挑战赛组织者还在新数据库上建立了几个基准系统,包括上一届挑战赛的顶层系统。
发布了基于 CycleVAE 的基线和基于 VC 的 Cascade ASR + TTS 的代码,让参与者可以轻松构建基础系统,专注于自己的创新。
2020 年挑战的特点是多方面的评估。除了传统的评价指标,该挑战还报告了转换语音的语音识别、说话人识别和抗欺骗评价结果。
根据最后的报告,令人鼓舞的是,在第一个任务中,几个系统的说话人相似度分数非常接近目标说话人自然说话的相似度分数。
然而,没有一个系统达到人类水平的自然。第二个任务更具挑战性。虽然我们观察到整体的自然度和相似度分数低于第一个任务,但最佳系统的 MOS 分数高于 4.0 。
7.5 相关挑战 — ASVspoof Challenge
针对自动说话人验证的欺骗干扰能力是语音转换的一个相关主题,也被组织为技术挑战。
ASVspoof 系列挑战就是这样的活动,每两年举办一次,始于 2013 年。就像在语音转换挑战中一样,组织者向参与者发布了一个公共数据库,其中包括许多对欺骗音频(转换、生成音频或重放音频)和真实音频,参与者使用自己的技术构建反欺骗模型。
主办方对参与者提交的抗欺骗结果的检测精度进行排序。
2015 年,建立了第一个包含各种类型的使用语音转换和 TTS 系统的欺骗音频的反欺骗干扰数据库。
该数据库成为自动说话人验证( ASV )社区的参考标准(《ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge》,《ASVspoof: The automatic speaker verification spoofing and countermeasures challenge》)。
2017 年挑战赛的主要焦点是重放任务,其中收集了大量真实世界的重放语音数据(《The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection》)。 2019 年,建立了一个更大的数据库,包括转换、生成和回放语音数据(《ASVspoof 2019: Future horizons in spoofed and fake audio detection》)。
2016 年和 2018 年语音转换挑战中性能最好的系统也被用于生成高级欺骗音频(《ASVspoof 2019: A large-scale public database of synthetic, converted and replayed speech》)。这些挑战表明,一些反欺骗系统在检测欺骗音频方面比人类听众表现更好。
8 资源
除了上述的语音转换挑战数据库, CMU-Arctic 数据库(《The CMU arctic speech databases》)和 VCTK 数据库(《CSTR VCTK corpus: English multi-speaker corpus for cstr voice cloning toolkit》)也很受欢迎,用于语音转换研究。
CMU-Arctic 数据库目前的版本有 18 个说英语的人,他们每个人都从古腾堡计划( Project Gutenberg )的已版权保护的文本中精心挑选出相同的一套约 1150 句话。
这适用于平行语音转换,因为句子对所有的说话者来说都是通用的。当前版本( 0.92 )的 CSTR VCTK 语料库收录了 110 位不同方言的英语使用者的语音数据。
每位演讲者朗读约400句,这些句子都是从报纸、彩虹段落和用于演讲口音档案的启启性段落中挑选出来的。由于彩虹通道和启发式段落是所有发言者共同的,该数据库可用于并行和非并行语音转换。
由于神经网络需要大量数据,而对看不见的说话者的泛化是成功转换的关键,因此大规模、但低质量的数据库,如 LibriTTS 和 VoxCeleb ,也被用于训练一些必要的组件(如说话者编码器)进行语音转换。
LibriTTS 语料库(《LibriTTS: A corpus derived from LibriSpeech for text-tospeech》)[有总计 2,456 人发表的 585 小时转录语音数据。该语料库的录制条件和音质都不理想,但适合于训练说话人编码网络或推广任意到任意说话人映射网络。
VoxCeleb 数据库(《VoxCeleb: Largescale speaker verification in the wild》)是一个更大规模的语音数据库,包含 6000 多名发言者的约 2800 小时未转录的语音。这是一个适合训练噪声鲁棒的扬声器编码器网络的数据库。
有很多训练 VC 模型的开源代码。
例如, spocket (《sprocket: Open-source voice conversion software》)支持基于 GMM 的转换, ESPnet (《ESPnet: End-to-end speech processing toolkit》)支持级联 ASR 和 TTS 系统。
此外,GitHub上的社区编写了许多基于神经网络的语音转换的开源代码。
9 结论
这篇文章提供了语音转换技术的全面概述,涵盖到 2020 年 8 月的基本原理和实践。
我们揭示了从统计方法到深度学习的潜在技术及其关系,并讨论了它们的前景和局限性。
我们还研究了语音转换的评估技术。
此外,我们报告了一系列语音转换的挑战和资源,为研究人员和工程师开始语音转换研究提供了有用的信息。