马尔可夫链、隐马尔科夫模型、贝叶斯网络、因子图
文章目录
- 一. 马尔可夫链以及隐马尔可夫模型
-
- 1.1 概念
- 1.2 举例说明隐马尔可夫模型
- 二. 贝叶斯网络
- 三. 因子图
贝叶斯网络是很多概率模型的基础,对于slam研究也是一项必须掌握的数学理论工具。
一. 马尔可夫链以及隐马尔可夫模型
1.1 概念
我们先来了解一下马尔可夫相关的概念。
- 马尔可夫性质(Markov property):在随机过程中,未来状态的条件概率分布仅依赖于当前状态,而与过去状态无关。
- 马尔可夫链(Markov chain):又称离散时间马尔科夫链(discrete-time Markov chain,缩写为DTMC)。下一状态的概率分布只能由当前状态决定,与时间序列中前面的状态无关。其实也就是马尔可夫性质。在马尔可夫链的每一步,系统根据概率分布,可以从一个状态变到另一个状态,也可以保持当前状态。状态的改变叫做转移,与不同的状态改变相关的概率叫做转移概率。
- 隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,其描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来进一步的分析。
- 马尔可夫模型中,状态对于观察者来说是直接可见的,状态的转移概率便是全部的参数。
- 隐马尔可夫模型中,状态并不是直接可见的,但受状态影响的某些变量是可见的。每一个状态在可能输出的符号上都有一概率分布。因此输出符号的序列能够透露出状态序列的一些信息。
1.2 举例说明隐马尔可夫模型
假如你有三种骰子D4,D6,D8,分别表示骰子为4,6,8面体,其中D6为最常见的骰子,他们每个面出现的概率分别为1/4,1/6,1/8。
现在假设你随机从里面选一个骰子,然后得到一串数字:1 6 3 5 2 7 3 5 2 4。这串数字叫可见状态链。除此之外你还有一串隐含状态链,也就是骰子的序列,比如可能为:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8。这个过程如下:
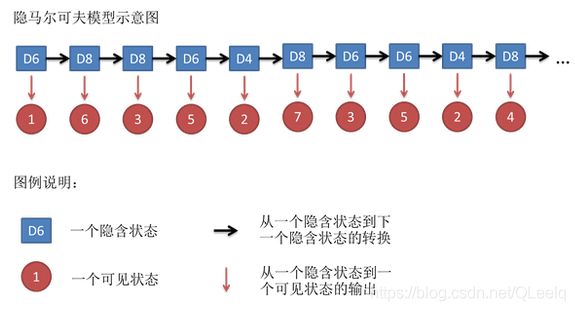
HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。

隐马尔可夫模型的应用:
预测(filter):已知模型参数和某一特定输出序列,求最后时刻各个隐含状态的概率分布。
平滑(smoothing):已知模型参数和某一特定输出序列,求中间时刻各个隐含状态的概率分布. 通常使用forward-backward> 算法解决。
解码(most likely explanation): 已知模型参数,寻找最可能的能产生某一特定输出序列的隐含状态的序列,
通常使用Viterbi算法解决。
二. 贝叶斯网络
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型,于1985年由Judea Pearl首先提出。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(Directed Acyclic Graph)。
节点:表示一个属性。它们可以是观察到的变量或隐变量、未知参数等。
节点间(弧):代表属性间的概率依赖关系P(B|A)。
一条弧由一个属性A指向另外一个属性B,说明属性A的取值可以对属性B的取值产生影响,由于是有向无环图,A、B间不会出现有向回路。
A:弧尾,因,parents
B:弧头,果,children
1. head-to-head
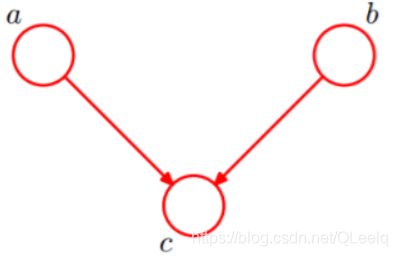
由上图可知:P(a,b,c)=P(a)P(b)P(c|a,b)成立。a,b为独立的。
2. tail-to-tail
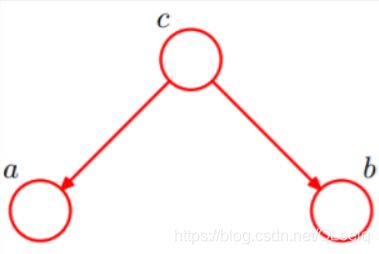
c未知的情况下:P(a,b,c)=P©P(a|c)P(b|c),此时没法得出P(a,b) = P(a)P(b),所以a,b不独立
c已知的情况下:P(a,b|c)=P(a,b,c)/P©,a,b独立。
3. head-to-tail
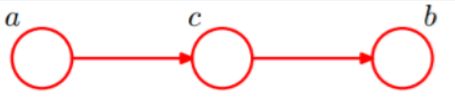
c未知的情况:P(a,b,c)=P(a)P(c|a)P(b|c),但不能推出P(a,b) = P(a)P(b),a,b不独立。
c已知的情况:a,b独立。
head-to-tail其实就是一个链式网络,且它为马尔科夫链。

三. 因子图
所谓因子图就是对函数进行因子分解得到的一种概率图。一般包含两个节点,变量节点和函数节点。我们知道,一个全局函数通过因式分解能够分解为多个局部函数的乘积,这些局部函数和对应的变量关系就体现在因子图上。
g ( x 1 , x 2 , x 3 , x 4 , x 5 ) = f A ( x 1 ) f B ( x 2 ) f C ( x 1 , x 2 , x 3 ) f D ( x 3 , x 4 ) f E ( x 3 , x 5 ) g(x_1,x_2,x_3,x_4,x_5)=f_A(x_1)f_B(x_2)f_C(x1,x2,x3)f_D(x_3,x_4)f_E(x_3,x_5) g(x1,x2,x3,x4,x5)=fA(x1)fB(x2)fC(x1,x2,x3)fD(x3,x4)fE(x3,x5)
其中 f A , f B , f C , f D , f E f_A,f_B,f_C,f_D,f_E fA,fB,fC,fD,fE为各函数,表示变量直接的关系,可以是条件概率也可以是其他关系,对应的因子图为:

或者:

参考:
https://www.cnblogs.com/skyme/p/4651331.html
https://blog.csdn.net/v_july_v/article/details/40984699