2021/2022李宏毅机器学习笔记-self attention
sophisticated Input
到目前為止我们的Network的Input都是一个向量不管是在预测这个,YouTube观看人数的问题上啊,还是影像处理上啊,我们的输入都可以看作是一个向量,然后我们的输出,可能是一个数值,这个是
Regression,可能是一个类别,这是Classification
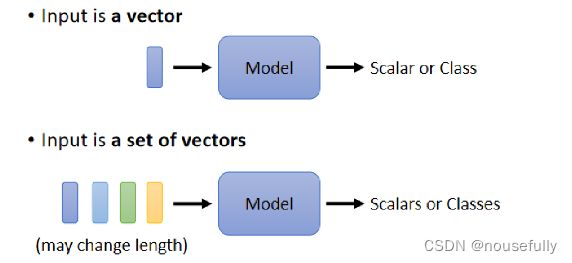
但假设我们遇到更復杂的问题呢,假设我们说输入是多个向量,而且这个输入的向量的数目是会改变的呢
我们刚才在讲影像辨识的时候我还特别强调我们假设输入的影像大小都是一样的,那现在假设每次我们Model输入的Sequence的数目Sequence的长度都不一样呢,,那这个时候应该要怎麼处理?
Vector Set as Input
文字处理
假设我们今天要Network的输入是一个句子,每一个句子的长度都不一样,每个句子里面词汇的数目都不一样

如果我们把一个句子裡面的每一个词汇,都描述成一 个向量那我们的Model的输入,就会是一-个Vector Set,而且这个Vector Set的大小,每次都不一样,句子的长度不一样那你的Vector Set的大小就不一样
那怎麼把一个词汇表示成一个向量最简单的做法是One-Hot的Encoding
你就开一个很长很长的向量,这个向量的长度跟世界上存在的词汇的数目是一样多的,每一个维度对应到一个词汇.Apple就是100,Bag就是010,Cat就是001,以此类推
但是这样子的表示方法有一个非常严重的问题, 它假设所有的词汇彼此之间都是没有关系的,从这个向量里面你看不到: Cat跟Dog都是动物所以他们比较接近,Cat跟Apple-个动物一 个植物,所以他们比较不相像。这个向量里面,没有任何语义的资讯
有另外一个方法叫做Word Embedding
Word Embedding就是,我们会给每一个词汇一个向量,而这个向量是有语义的资讯的
如果你把Word Embedding画出来的话,你会发现,所有的动物可能聚集成一-团,所有的植物可能聚集成一团,所有的动词可能聚集成一团等等
Word Embedding,会给每一个词汇一个向量,而一个句子就是一排长度不一的向量。
声音信号
一段声音讯号其实是一排向量,怎麼说呢,我们会把一 -段声 音讯号取一个范围,这个范围叫做一个Window

把这个Window裡面的资讯描述成一个向量,这个向量就叫做一个Frame,在语音上,我们会把一个向量叫做一个Frame,通常这个Window的长度就是25个Millisecond。
把这麼一个小段的声音讯号变成一个Frame,变成一 个向量就有百百种做法那这边就不细讲
一小段25个Millisecond裡面的语音讯号,為了要描述一整段的声音讯号, 你会把这个Window往右移一点,通常移动的大小是10个Millisecond。
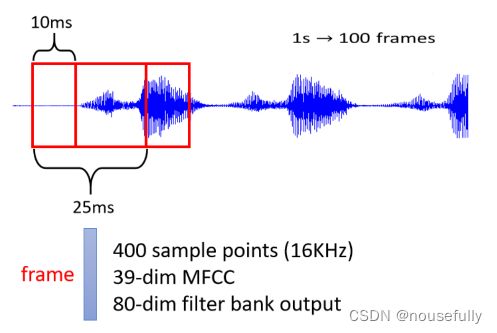
一段声音讯号, 你就是用一串向量来表示,而因為每一个Window啊, 他们往右移都是移动10个Millisecond,所以一秒鐘的声音讯号有100个向量,所以一分鐘的声音讯号,就有这个100乘以60,就有6000个向量
所以语音其实很复杂的,一-小段的声音讯号,它裡面包含的资讯量其实是非常可观的
图
一个Graph 一个图,也是一堆向量,我们知道说Social Network就是一个Graph
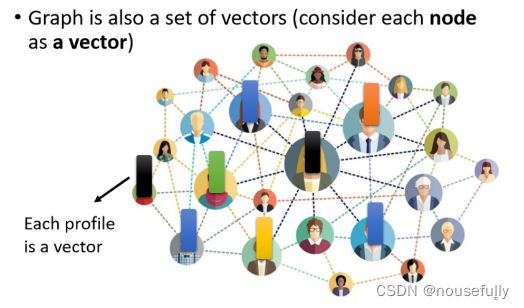
在Social Network.上面每一个节点就是一个人,然后节点跟节点之间的edge就是他们两个的关系连接,比如说是不是朋友等
而每一个节点可以看作是一个向量,你可以拿每-个人的比如说他的Profile裡面的资讯啊,他的性别啊他的年龄啊,他的工作啊他讲过的话啊等等把这些资讯用一个向量来表示
所以一个Social Network -个Graph,你也可以看做是一堆的向量所组成的
分子信息
一个分子,它也可以看作是一个Grape
What is the output?
1、每一个向量都有一个对应的Label
当你的模型,看到输入是四个向量的时候,它就要输入四个Label,而每一个Label,它可能是一个数值,那就是regression的问题,如果每个Label是一个Class,那就是一个Classfication的问题
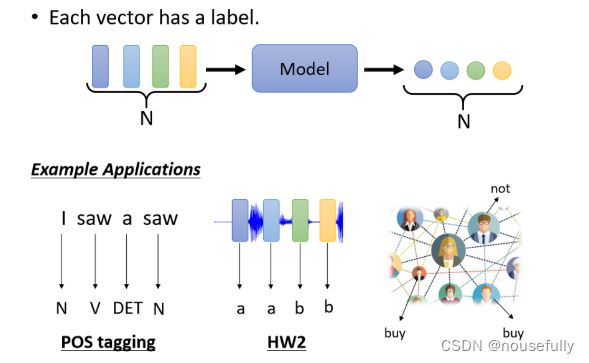
举例来说 在文字处理上,假设你今天要做的是POS Tagging,POStagging就是词性标注,你要让机器自动决定每一个词汇 它是什么样的词汇,它是名词 还是动词 还是形容词等等
这个任务啊,其实并没有很容易,举例来说,你现在看到一个句子,I saw a saw
这并不是打错,并不是“我看一个看”,而是“我看到一 个锯子,这个第二个saw当名词用的时候,它是锯子,那所以机器要知道第一个saw是个动词,第二个saw虽然它也是个saw,但它是名词,但是每一个输入的词汇,都要有一个对应的输出的词性
这个任务就是,输入跟输出的长度是一样的Case,这个就是属于第一个类型的输出
那如果是语音的话你可以想想看我们作业二就是这样子的任务
虽然我们作业二,没有给大家-个完整的Sequence,我们是把每一个每一 个每一 个Vector分开给大家了,但是串起来就是一段声音讯号裡面,有一串Vector 每一个Vector你都要决定,它是哪一Phonetic,这是一个语音辨识的简化版。
或者是如果是Social Network的话,就是给一个Graph
你的ModeI要决定每一个节点它有什麼样的特性,比如说他会不会买某一个商品,这样我们才知道说,要不要推荐某一个商品给他。
所以以上就是举输入跟输出数目一样的例子
2、一整个Sequence,只需要输出一个Label
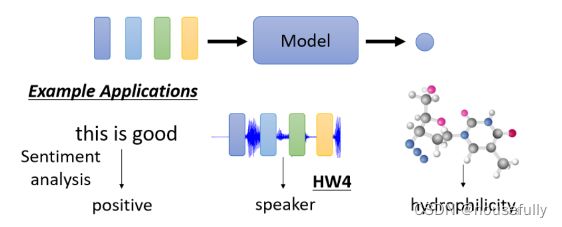
举例来说如果是文字的话,我们就说Sentiment Analysis
Sentiment Analysis就是给机器看- -段话, 它要决定说这段话是正面的还是负面的
那你可以想像说这种应用很有用,假设你的公司开发了-一个產品,这个產品上线了,你想要知道网友的评价怎麼样,但是你又不可能一-则一则网友的留言都去分析,那也许你就可以用这种,Sentiment
Analysis的技术,让机器自动去判读说,当- -则贴文裡面有提到某个產品的时候,它是正面的还是负面的,那你就可以知道你的產品,在网友心中的评价怎麼样,这个是Sentiment Analysis给一整个句子,只需要一个Label,那Positive或Negative,,那这个就是第二类的输出
那如果是语音的例子的话呢,在作业四裡面我们会做语者辨认,机器要听一段声音,然后决定他是谁讲的
或者是如果是Graph的话呢,今天你可能想要给一个分 子然后要预测说这个分子,比如说它有没有毒性,或者是它的亲水性如何,那这就是给一-个Graph输出一个Label
3、机器要自己决定,应该要输出多少个Label
我们不知道应该输出多少个Label,机器要自己决定,应该要输出多少个Label,可能你输入是N个向量,输出可能是N'个Label,為什麼是N,机器自己决定
这种任务又叫做sequence to sequence的任务,那我们在作业五会有sequence to sequence的作业,所以这个之后我们还会再讲
●翻译就是sequence to sequence的任务,因為输入输出是不同的语言,它们的词汇的数目本来就不会一样多
●或者是语音辨识也是,真正的语音辨识也是一 个sequence to sequence的任务,输入- -句话,然后输出一段文字,这也是一 个sequence to sequence的任务
第二种类型有作业四,感兴趣可以去看看作业四的程式,那因為上课时间有限,所以上课,我们今天就先只讲第一个类型,也就是输入跟输出数目一样多的状况
Sequence Labeling
那这种输入跟输出数目- -样多的状况又叫做Sequence Labeling,你要给Sequence裡面的每一个向量都给它一个Label,那要怎麼解Sequence Labeling的问题呢
那直觉的想法就是我们就拿个Fully-Connected的Network
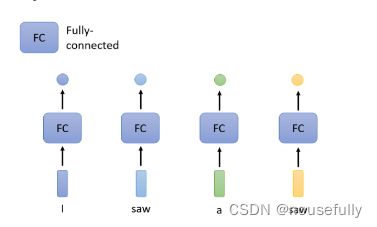
然后虽然这个输入是一个Sequence,但我们就各个击破,不要管它是不是一 个Sequence,把每一 个向量,分别输入到Fully-Connected的Network裡面
然后Fully-Connected的Network就会给我们输出,那现在看看你要做的是Regression还是Classification,产生正确的对应的输出,就结束了,
那这麼做显然有非常大的瑕疵,假设今天是,词性标记的问题你给机器一个句子,| saw a saw,对Fully-Connected Network来说,后面这一个saw跟前面这个saw完全一模一样,它们是同一个词汇
既然ully-Connected的Network输入同一个词汇,它没有理由输出不同的东西
但实际上,你期待第一个saw要输出动词,第二个saw要输出名词,但对Network来说它不可能做到,因為这两个saw明明是一模一样的你叫它一一个要输出动词,-一个要输出名词,它会非常地困惑,完全不知道要怎麼处理
所以怎么办,有没有可能让Fully-Connected的Network,考虑更多的,比如说.上下文的Context的资讯呢,这是有可能的,你就把前后几个向量都串起来,一起丢到Fully-Connected的Network就结束了
在作业二裡面,我们不是 只看一个Frame,去判断这个Frame属於哪一 个Phonetic, 也就属於哪一个音标,而是看这个Frame的前面五个加后面五个,也就总共看一个Frame,来决定它是哪一个音标
所以我们可以给Fully-Connected的Network,-整个Window的资讯,让它可以考虑一 -些 上下文的,跟我现在要考虑的这个向量,相邻的其他向量的资讯
但是这样子的方法还是有极限,作业二就算是给你Sequence的资讯,你考虑整个Sequence,你可能也很难再做的更好啦,作业二考虑前后五个Frame,其实就可以得到很不错的结果了,所以你要过Strong Baseline,重点并不在于考虑整个Sequence,你就不需要往那个方向想了,用助教现有给你的Data,你就可以轻易的过Strong Baseline,
但是真正的问题,但是如果今天我们有某一个任务 ,不是考虑一个Window就可以解决的,而是要考虑一整个Sequence才能够解决的话,那要怎麼办呢?
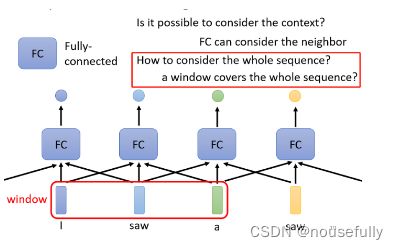
所以有没有更好的方法,来考虑整个Input Sequence的资讯呢,这就要用到我们接下来要跟大家介绍的,Self-Attention这个技术
Self-Attention
Self-Attention的运作方式就是,Self-Attention会吃一整个Sequence的资讯
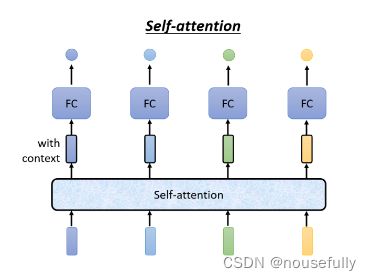
然后你Input几个Vector,它就输出几个Vector,比如说你这边Input-个深蓝色的Vector,这边就给你-个另外一个Vector
这边给个浅蓝色,它就给你另外一个Vector,这边输入4个Vector,它就Output 4个Vector
那这4个Vector有什麼特别的地方呢,这4个Vector,他们都是考虑一整个Sequence以后才得到的,那等一下我会讲说elf-Attention,怎麼考虑一整个Sequence的资讯
所以这边每一个向量 我们特别给它一个黑色的框框代表说它不是一个普通的向量
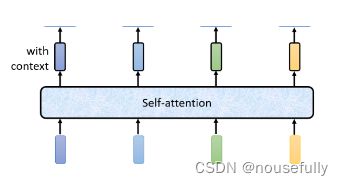
如此一来你这个Fully-Connected的Network,它就不是 只考虑一个非常小的范围,或一个小的Window,而是考虑整个Sequence的资讯,再来决定现在应该要输出什麼样的结果,这个就是Self-Attention。
Self-Attention不是只能用一次,你可以叠加很多次
所以可以把Fully-Connected的Network,跟Self-Attention交替使用
●Self-Attention处理整个Sequence的资讯
●Fully-Connected的Network,专注於处理某一 个位置的资讯
●再用Self-Attention,再把整个Sequence资讯再处理一 次
●然后交替使用Self-Attention跟Fully-Connected
self-Attention过程
Self-Attention的Input,它就是一串的Vector,那这个Vector可能是你整个Network的Input,它也可能是某个Hidden Layer的Output,所以我们这边不是用x来表示它,

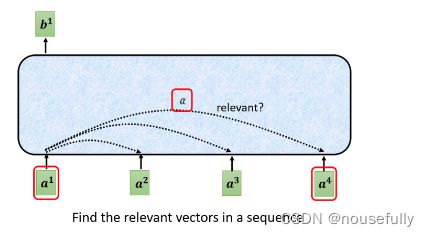
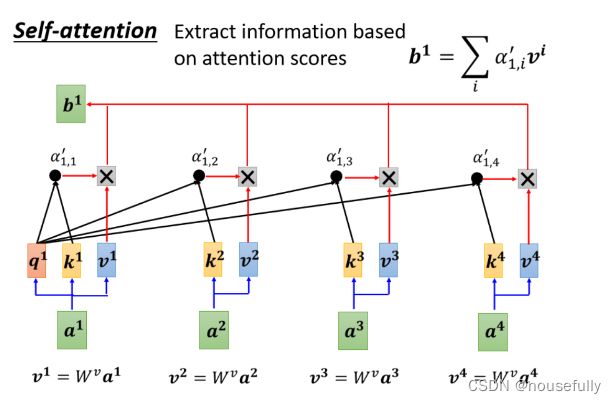
我们用a来表示它,代表它有可能是前面已经做过一些处理, 它是某个Hidden Layer的Output,那Input一排a这个向量以后,Self-Attention要Output另外-排b这个向量
那这每一个b都是考虑了所有的a以后才生成出来的,所以这边刻意画了非常非常多的箭头,告诉你bl考虑了a1到a4产生的,b2考虑a1到a4产生的,b3,b4也是一样,考虑整个input的sequence,才產生出来的
这里有一个特别的机制,这个机制是根据a1这个向量,找出整个很长的sequence裡面,到底哪些部分是重要的,哪些部分跟判断a1是哪一个label是有关系的,哪些部分是我们要决定a1的class,决定a1的
regression数值的时候,所需要用到的资讯
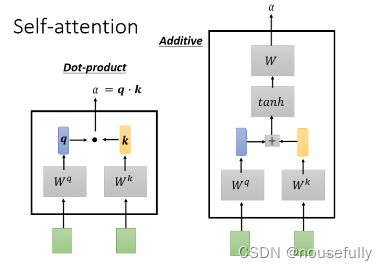
我们这边用a1, 2来代表说,Query是1提供的,Key是2提供的时候,这个1跟2他们之间的关联性,这个a这个关联性叫做Attention的Score,叫做Attention的分数,
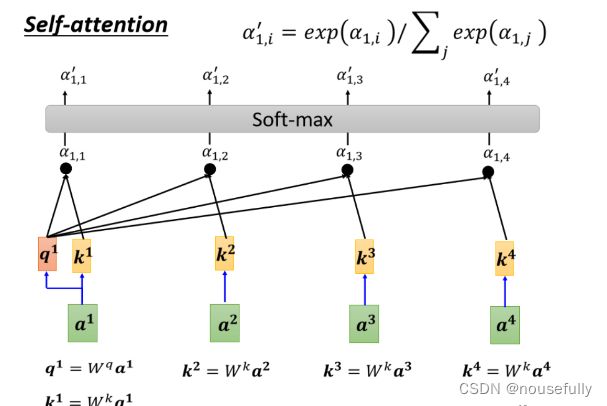
所以谁的那个Attention的分数最大,谁的那个v就会Dominant你抽出来的结果
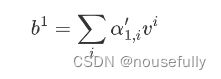
矩阵的角度

所以每一个 a得到q kv,其实就是把输入的这个,vector sequence乘上三个不同的矩阵,你就得到了q,得到了k,跟得到了v .
下一步是,每一个q 都会去跟每一个k,去计算这个inner product,去得到这个attention的分数,那得到attention分数这一件事情,如果从矩阵操作的角度来看,它在做什麼样的事情呢


矩阵跟向量相乘

但Self-attention,不是只能用在NLP相关的应用,上,它还可以用在很多其他的问题上,
self-attention for Image

那其实Self-attention,还可以被用在影像上,Self attention
那到目前為止我们在讲Self-attention的时候,我们都说Self-attention适用的范围是:输入是一个
vector set的时候
一张图片啊,我们把它看作是一个很长的向量,那其实一张图片,我们也可以换一个观点,把它看作是一个vector的set。
所以我们其实可以换一个角度,影像这个东西,其实也是一个vector set,它既然也是-个vector set的话,你完全可以用Self-attention来处理一张图片,那有没有人用Self-attention来处理一张图片呢
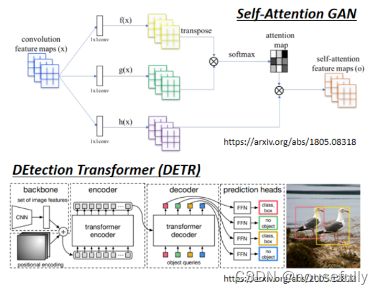
那这边就举了两个例子,来给大家参考,那现在把Self-attention用在影像处理上,也不算是一个非常石破天惊的事情。
我们可以来比较一下,Self-attention跟CNN之间,有什么样的差异或者是关联性,如果我们今天,是用Self-attention来处理一张图片代表说, 假设这个是你要考虑的pixel,那它产生query,其他pixel产生key,
