深度学习——目标检测学习笔记
参考教材:https://zh-v2.d2l.ai/
文章目录
- 1.目标检测
-
- 1.1 边界框
- 1.2 锚框
- 1.3 交并比(IoU)
- 1.4 非极大值抑制(non-maximum suppression,NMS)
- 2.目标检测算法(基于锚框)
-
- 2.1 R-CNN
- 2.2 Fast R-CNN
-
- 兴趣区域(RoI)池化层
- 2.3 Faster R-CNN
- 2.4 Mask R-CNN
- 2.5 单发多框检测(SSD)
1.目标检测
获取图像中目标的类别和具体位置,这类任务被称为目标检测(object detection)或目标识别(object recognition)。
1.1 边界框
通常使用边界框(bounding box)来描述对象的空间位置。 边界框是矩形的,由矩形左上角的以及右下角的 x 和 y 坐标决定;另一种常用的边界框表示方法是边界框中心的 (x,y) 轴坐标以及框的宽度和高度。原点在图片的左上角,水平方向为x轴,垂直方向为y轴。

两种边界框转换及描绘边界框代码如下:
import torch
import matplotlib.pyplot as plt
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
"""(x1,y1)表示边界框左上角的坐标,(x2,y2)表示右下角的坐标"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
"""(cx,cy)表示边界框中心点的坐标,w和h分别是边界框的宽高"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
def bbox_to_rect(bbox, color):
# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:((左上x,左上y),宽,高)
return plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2] - bbox[0], height=bbox[3] - bbox[1],
fill=False, edgecolor=color, linewidth=2)
if __name__ == '__main__':
img = plt.imread('./images/catdog.jpg')
# bbox是边界框的英文缩写
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
boxes = torch.tensor((dog_bbox, cat_bbox))
# 检测边界框转换函数功能是否正确
print(box_center_to_corner(box_corner_to_center(boxes)) == boxes)
fig = plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'))
plt.show()
1.2 锚框
以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框, 这些边界框被称为锚框(anchor box)。
假设输入图像的高度为H,宽度为W。 以图像的每个像素为中心生成不同形状的锚框:缩放比为s∈(0,1],宽高比为r>0。
下面的例子中,则是以(250,250)这个像素点为中心,生成了5个不同(s,r)的锚框。

1.3 交并比(IoU)
J(A,B) = A∩B|A∪B,用来衡量锚框和真实边界框之间的相似度。0表示两个框无重叠,1表示完全重叠,IoU值越高表示重叠部分越多。

1.4 非极大值抑制(non-maximum suppression,NMS)
输入图片后,会生成多个锚框,有可能很多锚框的重叠性很高,都是围绕着同一个目标。非极大值抑制则用来合并属于同一目标的类似的预测边界框。
对于一个预测边界框B,模型会计算每个类别的预测概率。假设最大的预测概率为 p ,则该概率所对应的类别即为预测的类别,并将 p 称为预测边界框 B 的置信度(confidence)。在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表 L 。然后通过以下步骤操作排序列表 L :
- 选出置信度最高的预测边界框B1作为基准,然后将所有与B1的IoU超过预定阈值threshold的非基准预测边界框从L中移除。
- 再选出置信度第二高的预测边界框B2作为又一基准,将所有与B2的IoU超过预定阈值threshold的非基准预测边界框从L中移除。
- 重复以上过程,直到L中的所有预测边界框都曾被用作基准。此时,L中任意一对预测边界框的IoU都小于阈值;因此,没有一对边界框过于相似。
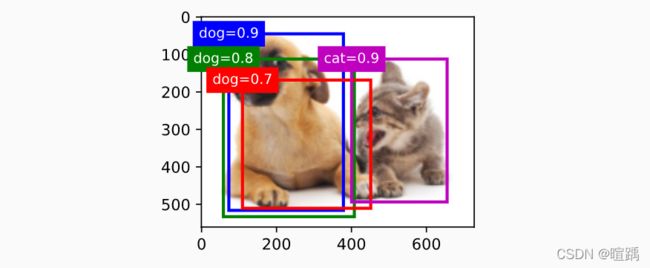
置信度列表L(按置信度高低排序):蓝框(dog=0.9)、紫框(cat=0.9)、绿框(dog=0.8)、红框(dog=0.7),假设threshold为0.5
- 以蓝框为基准,可以看出蓝框与绿框和红框的IoU均大于0.5,于是去除绿框和红框。此时L剩下蓝框和紫框。
- 以紫框为又一基准,其与蓝框的IoU小于0.5,均保留。
- 结束操作,L最后只剩下蓝框和紫框。

2.目标检测算法(基于锚框)
基于锚框的目标检测算法通常会在输入图像中采样大量的锚框区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)。
2.1 R-CNN
区域卷积神经网络(region-based CNN或regions with CNN features,R-CNN)模型如下图:

- 使用启发式搜索算法来选择锚框
- 使用预训练模型来对每个锚框抽取特征
- 训练一个SVM来对类别分类
- 训练一个线性回归模型来预测边缘框偏移
R-CNN模型通过预训练的卷积神经网络有效地抽取了图像特征,但它的速度很慢。从一张图像中选出上千个锚框,需要上千次的卷积神经网络的前向传播来执行目标检测。
2.2 Fast R-CNN
兴趣区域(RoI)池化层

对于任何形状为H×W的锚框,指定输出的H1×W1,该锚框会被划分为H1×W1的子区域,每个子区域的大小约为(H/H1)×(W/W1),其中的最大元素作为该子区域的输出。因此,兴趣区域池化层可从形状各异的锚框区域中均抽取出形状相同的特征。
Fast R-CNN模型如下图:

- 使用CNN对图片抽取特征
- 使用RoI池化层对每个锚框生成固定长度特征,卷积神经网络的输出和锚框区域作为输入,输出各个锚框区域抽取的特征
- 将n个特征提取后的锚框放入全连接层,其输出有两个。一个是形状为 n×q ( q 是类别的数量)的输出,用于预测类别(softmax);一个是形状为n×4的输出,用于预测边界框
Fast R-CNN相比R-CNN,不再对每个锚框使用CNN进行特征抽取,而是对整张图片进行特征抽取,因此速度有所提升。
2.3 Faster R-CNN
Faster R-CNN模型如下图:

- 使用一个区域提议网络来替代启发式搜索来获得质量更好的锚框
区域提议网络作为Faster R-CNN模型的一部分,是和整个模型一起训练得到的。区域提议网络能够学习到如何生成高质量的锚框区域,从而在减少锚框区域数量的情况下,仍保持目标检测的精度。
2.4 Mask R-CNN
Mask R-CNN模型如下图:

Mask R-CNN将兴趣区域汇聚层替换为了兴趣区域对齐层,使用双线性插值(bilinear interpolation)来保留特征图上的空间信息,从而更适于像素级预测。
兴趣区域对齐层的输出包含了所有与兴趣区域的形状相同的特征图。 它们不仅被用于预测每个兴趣区域的类别和边界框,还通过额外的全卷积网络预测目标的像素级位置。
2.5 单发多框检测(SSD)
SSD模型如下图:

- 一个基础网络用于抽取特征;然后多个卷积层块用于减半高宽,目的是扩大每个单元在其输出特征图中的感受野
- 每一阶段都生成锚框,底部阶段拟合小物体,顶部阶段拟合大物体
- 对每个锚框预测类别和边界框