用R语言做数据分析——时间序列分类

时间序列分类是根据已标注的时间序列建立一个分类模型,然后使用分类模型预测未标记时间序列的类别。从时间序列中抽取出新特征肯呢个有助于提高分类模型的性能。特征提取技术有奇异值分解(SVD)、离散傅立叶变换(DFT)、离散小波变换(DWT)、分段积累近似法(PAA)、连续重要点(PIP)、分段线性表示,以及符号表示。
基于原始数据的分类
我们使用party包来演示在原始数据上进行时间序列分类。在调用函数ctree()前,首先将类别标签转换为分类值,这样做可以避免得到一个像1.35这样的实数值。分析代码如下:
> classId <- rep(as.character(1:6), each=100)
> sc <- read.table("./synthetic_control.data", header=F, sep="")
> newSc <- data.frame(cbind(classId, sc))
> library(party)
> ct <- ctree(classId~., data=newSc,controls=ctree_control(minsplit=30,minbucket=10,maxdepth=5))
> pClassId <- predict(ct)
> table(classId, pClassId)
pClassId
classId 1 2 3 4 5 6
1 97 0 0 0 0 3
2 1 93 2 0 0 4
3 0 0 96 0 4 0
4 0 0 0 100 0 0
5 4 0 10 0 86 0
6 0 0 0 87 0 13
> (sum(classId==pClassId))/nrow(sc)
[1] 0.8083333
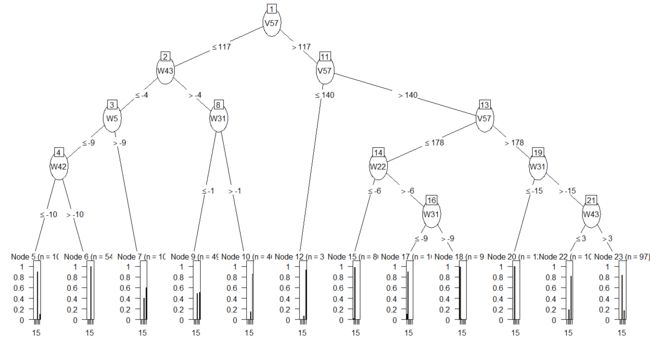
> plot(ct,ip_args=list(pval=FALSE),ep_args=list(digits=0))

基于特征提取的分类
接下来,我们使用离散小波变换(DWT)从时间序列中提取特种呢个,然后建立分类模型。小波变换通过小波来表示多分辨率。哈尔小波变换是最简单的离散小波变换。另一个常用的特征提取技术是离散傅立叶变换(DFT)。
下面的例子是使用哈尔过滤器提取DWT系数。wavelets包用于实现离散小波变换,其中函数dwt(x,filter,n.levels,...)计算DWT系数,x为一个单变量或多变量的时间序列,filter指明所使用的小波过滤器,n.levels指明需要分解的层数,该函数返回一个dwt对象,其中槽W包包含小波系数,V包包含相似系数。原始时间序列还可以使用wavelets包中的idwt()函数通过逆离散小波变换进行重构。分析代码如下:
> library(wavelets)
> wtData <- NULL
> for(i in 1:nrow(sc)) {
+ a <- t(sc[i,])
+ wt <- dwt(a, filter="haar", boundary="periodic")
+ wtData <- rbind(wtData, unlist(c(wt@W, wt@V[[wt@level]])))
+ }
> wtData <- as.data.frame(wtData)
> wtSc <- data.frame(cbind(classId, wtData))
> ct <- ctree(classId~., data=wtSc, controls=ctree_control(minsplit=30,minbucket=10,maxdepth=5))
> pClassId <- predict(ct)
> table(classId, pClassId)
pClassId
classId 1 2 3 4 5 6
1 97 3 0 0 0 0
2 1 99 0 0 0 0
3 0 0 81 0 19 0
4 0 0 0 63 0 37
5 0 0 16 0 84 0
6 0 0 0 1 0 99
> (sum(classId==pClassId))/nrow(wtSc)
[1] 0.8716667
> plot(ct,ip_args=list(pval=FALSE),ep_args=list(digits=0))
k-NN分类
k-NN分类同样适用于时间序列,它找出与新实例最邻近的k个对象,再根据投票机制给该实例打上类标号。然而原始的k-NN分类算法搜索k个最邻近对象需要的时间复杂度为O(n^2),n为数据的大小。因此,在处理大的时间序列数据时需要建立一个高效的索引。使用Arya和Mount's ANN库,RANN包能够以O(n log n)的时间复杂度快速地搜索最邻近对象。下面的例子是在没有建立索引的时间序列数据集上进行k-NN分类。
> k <- 20
> newTS <- sc[501,] + runif(100)*15
> distances <- dist(newTS, sc, method="DTW")
> s <- sort(as.vector(distances), index.return=TRUE)
> table(classId[s$ix[1:k]])
4 6
1 19
对于新时间序列数据的20个最邻近对象,其中有3个属于类别4,有17个属于类别6。根据投票机制选择类标号频率最大的,即新时间序列归属于类别6。