编译pytorch版本的PreciseRoIPooling
编译pytorch版本的PreciseRoIPooling中遇到的问题
- 找不到cuda include cuda_runtime_api的问题
- nvcc fatal : Unsupported gpu architecture 'compute_86'
- 关于cuda版本兼容性的问题
Dimp模型中使用pr pooling来池化目标区域(ROI)特征,以此初始化滤波器,使用到的prroi_pool模块来自于github,在编译过程中遇到些问题。
找不到cuda include cuda_runtime_api的问题
cudacontext.h:5:10: fatal error: cuda_runtime_api.h: no such file or directory
找不到cuda_runtime_api.h文件,该文件在cuda安装目录下的include下,但是pytorch能够正常寻找和使用cuda以及相应的库(因为etc/profile或.bashrc已经包含了cuda路径/usr/local/cuda/bin和lib路径/usr/local/cuda/lib64,nvcc 也正常)。
在pytorch运行py文件的configurations配置中Environment variables也正常继承了系统变量(cuda path),在该位置增加/usr/local/cuda/include也没有作用,总之是环境变量export path的问题,可能是写法不对,修改为如下形式:
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
这是nvidia官方CUDA Quick Start Guide的写法(改为了软链接路径),修改之后就没有上述问题了。可惜已经修改完成,没有记下来原来的写法。
nvcc fatal : Unsupported gpu architecture ‘compute_86’
机器是rtx 3080的显卡,驱动是460,使用的是cuda11.0的版本,pytorch 1.7.1,编译第二步就会出现nvcc的问题,主要是30系列的显卡cuda及驱动支持的兼容性问题,我也没搞清楚是怎么回事。问题:
Using /home/xx/.cache/torch_extensions as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /home/xx/.cache/torch_extensions/_prroi_pooling/build.ninja...
Building extension module _prroi_pooling...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
...
FAILED: prroi_pooling_gpu_impl.cuda.o
...
nvcc fatal : Unsupported gpu architecture 'compute_86'
...
ninja: build stopped: subcommand failed.
...
subprocess.CalledProcessError: Command '['ninja', '-v']' returned non-zero exit status 1.
RuntimeError: Error building extension '_prroi_pooling'
把cuda升级到11.1以上就可以了,虽然还是会给一堆警告:
/usr/local/cuda-11.1
Using /home/luo/.cache/torch_extensions as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /home/luo/.cache/torch_extensions/_prroi_pooling/build.ninja...
Building extension module _prroi_pooling...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
ninja: no work to do.
Loading extension module _prroi_pooling...
关于cuda版本兼容性的问题
有关的部分内容。
官方cuda兼容性与算力文档。
cuda与驱动要求关系表: cuda 11.0支持到sm_80,也就是8.0算力的架构,但是对安倍架构的30系列(sm_86,对应算力8.6,官方文档里还是8.0)并不包含:
cuda 11.0支持到sm_80,也就是8.0算力的架构,但是对安倍架构的30系列(sm_86,对应算力8.6,官方文档里还是8.0)并不包含:
 然后是驱动与cuda的兼容性问题:
然后是驱动与cuda的兼容性问题:
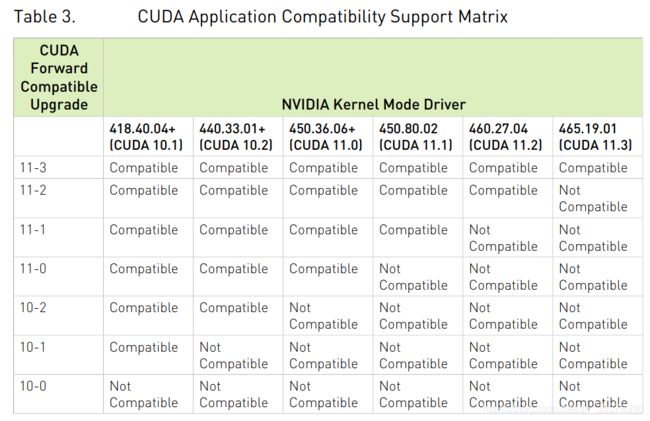 机器上默认安装了460的驱动,对应于11.2的cuda版本,但cuda装了11.0。。。
机器上默认安装了460的驱动,对应于11.2的cuda版本,但cuda装了11.0。。。
但是pytorch能够使用,tensorflow 2.4.1则干脆的多,直接罢工:
NotFoundError: No algorithm worked!
或者是cudnn初始化异常:
2021-04-19 17:01:38.239670: E tensorflow/stream_executor/cuda/cuda_dnn.cc:336] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[node my_model/conv2d/Conv2D (defined at /main.py:45) ]] [Op:__inference_train_step_527]
Errors may have originated from an input operation.
Input Source operations connected to node my_model/conv2d/Conv2D:
images (defined at /main.py:98)
加入如下内容可以临时应付:
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
# Restrict TensorFlow to only allocate 4GB of memory on the first GPU
try:
tf.config.experimental.set_virtual_device_configuration(gpus[0],[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=4096)])
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Virtual devices must be set before GPUs have been initialized
print(e)
但是cuda的兼容性问题还是存在的:
2021-04-19 18:59:59.096866: W tensorflow/stream_executor/gpu/asm_compiler.cc:235] Your CUDA software stack is old. We fallback to the NVIDIA driver for some compilation. Update your CUDA version to get the best performance. The ptxas error was: ptxas fatal : Value 'sm_86' is not defined for option 'gpu-name'
2021-04-19 18:59:59.096958: W tensorflow/stream_executor/gpu/redzone_allocator.cc:314] Unimplemented: /usr/local/cuda-11.0/bin/ptxas ptxas too old. Falling back to the driver to compile.
Relying on driver to perform ptx compilation.
Modify $PATH to customize ptxas location.
This message will be only logged once.
2021-04-19 18:59:59.207513: W tensorflow/stream_executor/gpu/asm_compiler.cc:235] Your CUDA software stack is old. We fallback to the NVIDIA driver for some compilation. Update your CUDA version to get the best performance. The ptxas error was: ptxas fatal : Value 'sm_86' is not defined for option 'gpu-name'
2021-04-19 18:59:59.320780: W tensorflow/stream_executor/gpu/asm_compiler.cc:235] Your CUDA software stack is old. We fallback to the NVIDIA driver for some compilation. Update your CUDA version to get the best performance. The ptxas error was: ptxas fatal : Value 'sm_86' is not defined for option 'gpu-name'
2021-04-19 18:59:59.433035: W tensorflow/stream_executor/gpu/asm_compiler.cc:235] Your CUDA software stack is old. We fallback to the NVIDIA driver for some compilation. Update your CUDA version to get the best performance. The ptxas error was: ptxas fatal : Value 'sm_86' is not defined for option 'gpu-name'
...
但是目前的tensorflow 2.4.1只支持到cuda 11.0,tensorflow 2.5.0 rc开始支持11.2 (sm_86: cuda>=11.1),换句话说要等到2.5.0之后才能在30系列卡上使用tensorflow发挥最大算力:
“Devices of compute capability 8.6 have 2x more FP32 operations per cycle per SM than devices of compute capability 8.0. While a binary compiled for 8.0 will run as is on 8.6, it is recommended to compile explicitly for 8.6 to benefit from the increased FP32 throughput.“
https://docs.nvidia.com/cuda/ampere-tuning-guide/index.html#improved_fp32