神经网络与深度学习学习笔记(一)——基本概念
1.什么是神经网络和深度学习
随着神经科学、认知科学的发展,我们逐渐知道人类的智能行为都和大脑活动有关。受到人脑神经系统的启发,早期的神经科学家构造了一种模仿人脑神经系统的数学模型,称为人工神经网络,简称神经网络。在机器学习领域,神经网络是指由很多人工神经元构成的网络结构模型,这些人工神经元之间的连接强度是可学习的参数。
典型的神经元结构大致可分为细胞体和细胞突起:
(1) 细胞体(Soma)中的神经细胞膜上有各种受体和离子通道,胞膜的受体可与相应的化学物质神经递质结合,引起离子通透性及膜内外电位差发生改变,产生相应的生理活动:兴奋或抑制。
(2) 细胞突起是由细胞体延伸出来的细长部分,又可分为树突和轴突.
a ) 树突(Dendrite)可以接收刺激并将兴奋传入细胞体。每个神经元可以有一或多个树突。
b ) 轴突(Axon)可以把自身的兴奋状态从胞体传送到另一个神经元或其他组织。每个神经元只有一个轴突。
神经元可以接收其他人工神经网络是为模拟人脑神经网络而设计的一种计算模型,它从结构、实现机理和功能上模拟人脑神经网络。人工神经网络与生物神经元类似,由多个节点(人工神经元)互相连接而成,可以用来对数据之间的复杂关系进行建模。不同节点之间的连接被赋予了不同的权重,每个权重代表了一个节点对另一个节点的影响大小。每个节点代表一种特定函数,来自其他节点的信息经过其相应的神经元的信息,也可以发送信息给其他神经元。神经元之间没有物理连接,两个“连接”的神经元之间留有20纳米左右的缝隙,并靠突触(Synapse)进行互联来传递息,形成一个神经网络,即神经系统。突触可以理解为神经元之间的连接“接口”,将一个神经元的兴奋状态传到另一个神经元。一个神经元可被视为一种只有两种状态的细胞:兴奋和抑制。神经元的状态取决于从其他的神经细胞收到的输入信号量,以及突触的强度(抑制或加强)。当信号量总和超过了某个阈值时,细胞体就会兴奋,产生电脉冲。电脉冲沿着轴突并通过突触传递到其他神经元。下图给出了一种典型的神经元结构。

人工神经网络是为模拟人脑神经网络而设计的一种计算模型,它从结构、实现机理和功能上模拟人脑神经网络。人工神经网络与生物神经元类似,由多个节点(人工神经元)互相连接而成,可以用来对数据之间的复杂关系进行建模。不同节点之间的连接被赋予了不同的权重,每个权重代表了一个节点对另一个节点的影响大小。每个节点代表一种特定函数,来自其他节点的信息经过其相应的权重综合计算,输入到一个激活函数中并得到一个新的活性值(兴奋或抑制)。从系统观点看,人工神经元网络是由大量神经元通过极其丰富和完善的连接而构成的自适应非线性动态系统。
而机器学习(Machine Learning,ML)就是让计算机从数据中进行自动学习,得到某种知识(或规律)。
以手写体数字识别为例,我们需要让计算机能自动识别手写的数字。比如下图中的例子,识别图中手写的数字。要识别手写体数字,首先通过人工标注大量的手写体数字图像(即每张图像都通过人工标记了它是什么数字),这些图像作为训练数据,然后通过学习算法自动生成一套模型,并依靠它来识别新的手写体数字。这个过程和人类学习过程也比较类似,我们教小孩子识别数字也
是这样的过程。这种通过数据来学习的方法就称为机器学习的方法。

图片来源:LeCunY,CortesC,BurgesCJ,1998. MNISThandwrittendigitdatabase[EB/OL]
2.基本概念
首先介绍机器学习中的一些基本概念:样本、特征、标签、模型、学习算法等。
一个标记好特征以及标签的个体看作一个样本(Sample),也经常称为示例(Instance)。一组样本构成的集合称为数据集(Data Set)。 在很多领域,数据集也经常称为语料库(Cor-
pus)。一般将数据集分为两部分:训练集和测试集。训练集(Training Set)中的样本是用来训练模型的,也叫训练样本(Training Sample),而测试集(Test Set)中的样本是用来检验模型好坏的,也叫测试样本(Test Sample)。我们通常用一个维向量 = [1,2,⋯,]T 表示一个个体的所有特征构成的向量,称为特征向量(Feature Vector),其中每一维表示一个特征。并不是所有的样本特征都是数值型,需要通过转换表示为特征向量。而个体的标签通常用标量来表示。假设训练集由 个样本组成,其中每个样本都是独立同分布的(Identi-cally and Independently Distributed,IID),即独立地从相同的数据分布中抽取的,记为
![]()
给定训练集,我们希望让计算机从一个函数集合ℱ = {1(),2(),⋯}中自动寻找一个“最优”的函数()来近似每个样本的特征向量和标签之间的真实映射关系.对于一个样本,我们可以通过函数()来预测其标签的值
![]()
如何寻找这个“最优”的函数()是机器学习的关键,一般需要通过学习算法(Learning Algorithm)来完成。(在 有 些 文 献 中, 学习算法也叫作学习器(Learner))这个寻找过程通常称为学习(Learning)或训练(Training)过程。
3.理论和定理
在机器学习中,有一些非常有名的理论或定理,对理解机器学习的内在特性非常有帮助。
3.1 PAC学习理论
先放PAC学习相关理论的一个总结:同等条件下,模型越复杂泛化误差越大。同一模型在样本满足一定条件的情况下,样本数量越大,模型泛化误差越小,因此还可以说模型越复杂越吃样本。
机器学习有三个元素:模型、学习准则、优化算法。所谓机器学习就是用优化算法从假设空间中选择一个假设,使此假设能符合给定的数据描述。因此优化算法通俗的讲就是假设选择算法。
而PAC学习理论不关心假设选择算法,他关心的是能否从假设空间H 中学习一个好的假设 h ?此理论不关心怎样在假设空间中寻找好的假设,只关心能不能找得到。现在我们在来看一下什么叫“好假设”?只要满足两个条件(PAC辨识条件)即可:
- 近似正确:泛化误差 E(h) 足够小
- E(h)越小越好,最好泛化误差能等于0,但一般不可能。那么我们就把E(h)限定在医德很小的数
 之内,即只要假设h满足E(h)
之内,即只要假设h满足E(h)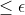 ,我们就认为h是正确的。
,我们就认为h是正确的。 - 可能正确
- 不指望假设h百分之百是近似正确(即E(h)),只要很可能是近似正确的就可以。我们给定一个值
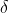 ,假设h满足P(h近似正确)
,假设h满足P(h近似正确)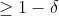 。
。
综上两点,就得到了PAC(可能近似正确,probably approximate correct)可学习的定义。简单的讲就是模型在短时间内利用少量的(多项式级别)样本能够找到一个假设  ,使其满足
,使其满足 ![]()
![]()
3.2 没有免费午餐定律
没有免费午餐定理(No Free Lunch Theorem,NFL)是由Wolpert和Mac-erday在最优化理论中提出的。没有免费午餐定理证明:对于基于迭代的最优化算法,不存在某种算法对所有问题(有限的搜索空间内)都有效。如果一个算法对某些问题有效,那么它一定在另外一些问题上比纯随机搜索算法更差。也就是说,不能脱离具体问题来谈论算法的优劣,任何算法都有局限性。必须“具体问题具体分析”。没有免费午餐定理对于机器学习算法也同样适用。不存在一种机器学习算法适合于任何领域或任务。如果有人宣称自己的模型在所有问题上都好于其他模型,那么他肯定是在吹牛。
3.3 没有免费午餐定律
奥卡姆剃刀(Occam’sRazor)原理是由14世纪逻辑学家WilliamofOccam提出的一个解决问题的法则:“如无必要,勿增实体”。奥卡姆剃刀的思想和机器学习中的正则化思想十分类似:简单的模型泛化能力更好。如果有两个性能相近的模型,我们应该选择更简单的模型。因此,在机器学习的学习准则上,我们经常会引入参数正则化来限制模型能力,避免过拟合。
3.4 丑小鸭定理
丑小鸭定理(Ugly Duckling Theorem)是1969年由渡边慧提出的[Watan-abe, 1969]。
“丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大”,这个定理初看好像不符合常识,但是仔细思考后是非常有道理的。因为世界上不存在相似性的客观标准,一切相似性的标准都是主观的。如果从体型大小或外貌的角度来看,丑小鸭和白天鹅的区别大于两只白天鹅的区别;但是如果从基因的角度来看,丑小鸭与它父母的差别要小于它父母和其他白天鹅之间的差别。
4.参考文献
邱锡鹏,《神经网络与深度学习》