[论文阅读笔记]图像修复篇:Context Encoders: Feature Learning by Inpainting 2016CVPR
Context Encoders: Feature Learning by Inpainting 2016CVPR
文章下载链接:https://openaccess.thecvf.com/content_cvpr_2016/papers/Pathak_Context_Encoders_Feature_CVPR_2016_paper.pdf
基于pytorch代码下载:https://github.com/eriklindernoren/PyTorch-GAN
基于tensorflow代码下载:https://github.com/pathak22/context-encoder
一篇比较经典的生成模型用于图像恢复。
注:自用。若有措辞不严谨,认知有误的地方还请指出!
Abstract
无监督视觉特征学习算法,driven by context-based pixel prediciton
context Encoders的任务:既需要理解整个图像的内容,还需要产生对确实区域的合理假设。
损失函数:a standard pixel-wise reconstruction loss 和 a reconstruction plus an adversarial loss(后者产生更清晰的结果,因为它能更好地处理输出中的多个模式(不理解这句话))
context Encoders的优势:可以捕获外表也可以捕获视觉结构的语义。
实验:在分类,检测,分割任务上验证了我们学习的特征对CNN预训练的有效性。另外,context Encoders也能用于语义修复任务,或非参数方法的初始化(不懂)
1. Introduction
问题背景:人类的视觉世界十分多样,结构化,可以理解这种结构。本文探索CV算法是否也可以像人类一样,探索CNN也可能学习和预测这种结构。
![[论文阅读笔记]图像修复篇:Context Encoders: Feature Learning by Inpainting 2016CVPR_第1张图片](http://img.e-com-net.com/image/info8/36a35c31a16f4cf991c216694cb95aa8.jpg)
context Encoders的结构类似于autoencoder,都是先编码为一个紧凑的特征表达形式,再进行解码重构。但是这样的表达只是压缩了图像内容,没有学习到一个具有语义意义的表达。Denoising autoencoders也只是处理局部且低维的污染,本文的context Encoders需要填补一个大面积的缺失,不能从附近像素中获得提示,需要更深的语义理解,并需要在大空间范围内综合高级特征的能力。
context Encoders以完全无监督的方式训练。图像修复的任务本质上是一个multi-model,有多种方式填补缺失区域同时需要维持和给定内容的一致性。本文通过损失函数解决这个问题,通过联合训练context Encoders以使重构损失和对抗损失最小化。重构损失L2捕获缺失区域的整体结构,对抗损失从分布中挑选出特别的模式。
context Encoders是第一个能够为语义填充(即较大的缺失区域)提供合理结果的参数修复算法。
2. Related Work
(略)
3. Context encoders for image generation
![[论文阅读笔记]图像修复篇:Context Encoders: Feature Learning by Inpainting 2016CVPR_第2张图片](http://img.e-com-net.com/image/info8/4a51e054890f475690466c15c4e1f2a2.jpg)
编码器
源于AlexNet结构。但没有采用ImageNet的预训练模型,而是用带有随机初始化的权重从头开始训练。
但是如果编码器的架构中只有卷积层,就不会有信息直接从特征图的一个角落传递给另一个。这是因为卷积层将搜索特征图连接在一起,但是没有直接连接所有的位置在一个特定的特征图内。目前来讲,信息传递过程由全连接层或inner product层处理,所有的激活函数和彼此直接相连。在context Encoders中,潜在的特征维度(即编码器压缩后的特征维度)是6*6*256=9216,将编码器和解码器全连接会导致参数爆炸(超过100M!)。为了缓解这个问题,使用a channel-wise fully-connected layer去连接编码器的特征到解码器。
a channel-wise fully-connected layer
本质上是一个带有分组的全连接层,旨在在每个特征图的激活函数内传播信息。
如果输入层由m个大小为n*n的特征图,这个层将会输出m个n*n的特征图。但是,这层没有连接不同特征图的参数,只传递特征图内的信息。因此这个层的参数数量是mn^4(全连接层的参数是m^2*n^4)。随后是步幅为1的卷积,可跨通道传播信息。
解码器
由5个带有learned filters的up-convolutional layers组成,每层带有ReLU激活函数。
损失函数
通过回归缺失(丢失)区域的groun truth来训练context Encoders。 但是,通常有多种与上下文相符的同样合理的方式来填充缺失的图像区域。通过a decoupled joint loss function去处理这个问题。重构损失L2捕获缺失区域的整体结构,和其内容保持一致性,但是会趋于平均多种模型。对抗损失做一个看起来真实的预测从分布中挑选出具体的模式。
重构损失L2
![]()
实验发现l1和l2没有显著差异。l2会导致图像模糊,它通常无法捕获任何高频细节。这是由于L2(或L1)损失通常更倾向于模糊的解。因为最小化平均像素方向的误差,但会导致平均图像模糊。
对抗损失
判别器的目的是区别输入是真的图片还是假的图像
对抗损失的公式
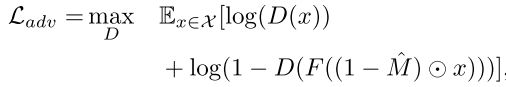
训练时交替使用SGD对生成器和对抗器优化。
总体损失
![]()
![]()
5.1 图像修复的实施细节
没有调节对抗损失,也没有给编码器添加噪声。对Context Encoder用了比判别器高出10倍的学习率。为了进一步强调预测内容的一致性,预测了一个稍微大点的patch,这个patch覆盖了缺失部分。在训练时,用了10倍多的权重用于重构损失在被覆盖区域。
实验结果展示,如果缺失区域中低级纹理特征更丰富,则纹理合成方法效果更好。本文方法在语义上总是对齐的(可能会模糊,但是不会瞎填)
一些结果图