数据学习(5)·K-means 聚类和PCA算法
作者的课堂笔记[email protected]
Preview
- K-means 聚类
- 主成分分析(Principal Component Analysis)
无监督学习
和有监督学习类似,但是数据没有标签。给定输入数据,发现简化的特征,同时和输入的特征拥有同样的信息量。
一般来说,好的表示一般是低维度的,或者是稀疏表示的,也就是说大部分是0,又或者是独立的表示。
1 K-means 聚类问题
输入数据 { x ( 1 ) . . . . . x ( m ) } , x ( i ) ∈ R d \{x^{(1)}.....x^{(m)}\},x^{(i)}\in R^d {x(1).....x(m)},x(i)∈Rd,K-means聚类将输入数据分成k类, k ≤ n k≤n k≤n来最小化每个类别内的平方和(WCSS).
a r g m i n C ∑ j = 1 k ∑ x ∈ C j ∣ ∣ x − μ j ∣ ∣ 2 argmin_C\sum_{j=1}^k\sum_{x\in C_j}||x-\mu_j||^2 argminCj=1∑kx∈Cj∑∣∣x−μj∣∣2
等价问题:
- 最小化每个类内的方差 ∑ j = 1 k ∣ C j ∣ V a r ( C j ) \sum_{j=1}^k|C_j|Var(C_j) ∑j=1k∣Cj∣Var(Cj).
- 最小化点之间的成对平方偏差在同一集群中: ∑ i = 1 k 1 2 ∣ C i ∣ ∑ x , x ‘ ∈ C i ∣ ∣ x − x ‘ ∣ ∣ 2 \sum_{i=1}^k\frac{1}{2|C_i|}\sum_{x,x`\in C_i}||x-x`||^2 ∑i=1k2∣Ci∣1∑x,x‘∈Ci∣∣x−x‘∣∣2
- 最大化类与类之间的距离(BCSS).
1.1 K-means聚类算法
- 优化K-means聚类是一个NP-hard问题,在欧式空间中。
- 通常通过启发式,迭代算法。
Lloyd’s 算法

1.2 K-means聚类讨论
- K-means学习k维的稀疏表示,比如x使用one-hot编码, z ∈ R k z\in R^k z∈Rk.
z j ( i ) = 1 i f c ( i ) = j , o t h e r w i s e 0 z_j^{(i)}=1 \quad if \quad c^{(i)}=j,otherwise \quad0 zj(i)=1ifc(i)=j,otherwise0
算法收敛于局部最优解,所以初始值的选择很重要! - 怎样初始化 μ \mu μ?均匀随机抽样(K-means++),或者基于距离的采样。
- 怎么选择K?交叉验证或者G-means。
2 PCA(Principal Component Analysis)
消除特征之间的相关性,同时减少噪音。
给出 { x ( 1 ) , . . . , x ( m ) } , x ( i ) ∈ R n \{x^{(1)},...,x^{(m)}\},x^{(i)}\in R^n {x(1),...,x(m)},x(i)∈Rn.
- 发现一个线性的正交变换W: R n − R k R^n-R^k Rn−Rk针对输入数据。
- W 是将最大方差的方向和新坐标轴的方向对齐。

正则化x,以便让 m e a n ( x ) = 0 , S t d e v ( x j ) = 1 mean(x)=0,Stdev(x_j)=1 mean(x)=0,Stdev(xj)=1 - x ( i ) : = x ( i ) − M e a n ( x ) x^{(i)}:=x^{(i)}-Mean(x) x(i):=x(i)−Mean(x)
- x j ( i ) : = x j ( i ) / S t d e v ( x j ) x^{(i)}_j:=x^{(i)}_j/Stdev(x_j) xj(i):=xj(i)/Stdev(xj)

2.1 PCA表示学习
PCA 目标:
- 发现主要的组成 u 1 , . . . . . , u n u_1,.....,u_n u1,.....,un他们相互正交,也就是不相关。
- x x x的大部分变化将由 k < < n k<<n k<<n的 k k k个主成分来解释。
PCA 的主要操作:
- 发现 x x x的投影, u 1 T x u_1^Tx u1Tx覆盖最大的方差。
- 对 j = 1 , 2 , . . . . , n j=1,2,....,n j=1,2,....,n同样上述操作,找出互相正交的 u 1 , . . . . . , u j u_1,.....,u_j u1,.....,uj个方向。
2.2 寻找主成分
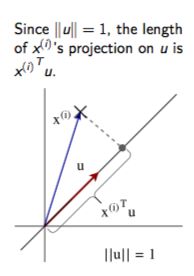
投影的方差:
1 m ∑ i = 1 m ( x ( i ) T u ) 2 = 1 m ∑ i = 1 m u T x ( i ) x ( i ) T u = u T ( 1 m ∑ i = 1 m x ( i ) x ( i ) T ) u = u T Σ u \frac{1}{m}\sum_{i=1}^m(x^{(i)^T}u)^2=\frac{1}{m}\sum_{i=1}^mu^Tx^{(i)}x^{(i)^T}u=u^T(\frac{1}{m}\sum_{i=1}^m x^{(i)}x^{(i)^T})u=u^T\Sigma u m1∑i=1m(x(i)Tu)2=m1∑i=1muTx(i)x(i)Tu=uT(m1∑i=1mx(i)x(i)T)u=uTΣu
Σ : \Sigma: Σ:是样本的协方差矩阵。
2.3 第一主要成分
发现一个 u 1 u_1 u1最大化投影方差:
u 1 = a r g m a x u : ∣ ∣ u ∣ ∣ = 1 u T Σ u u_1=argmax_{u:||u||=1}u^T\Sigma u u1=argmaxu:∣∣u∣∣=1uTΣu
u 1 u_1 u1被称为 x x x的第一主成分。同时 u 1 u_1 u1是协方差矩阵的最大特征向量。
证明: u 1 u_1 u1是协方差矩阵的最大特征向量。
使用拉格朗日函数:
L ( u ) = − u T Σ u + β ( u T u − 1 ) L(u)=-u^T\Sigma u+\beta(u^Tu-1) L(u)=−uTΣu+β(uTu−1)
最小化 L ( u ) L(u) L(u).
∂ L ∂ u = − 2 Σ u + 2 β u = 0 \frac{\partial L}{\partial u}=-2\Sigma u+2\beta u=0 ∂u∂L=−2Σu+2βu=0
所以 Σ u = β u \Sigma u=\beta u Σu=βu,因此 u 1 u_1 u1是 Σ \Sigma Σ的特征向量。 u = v j u=v_j u=vj,是第 j j j大的特征值对应的特征向量。
u T Σ u = v j T Σ v j = λ j v j T v j = λ j u^T\Sigma u=v_j^T\Sigma v_j=\lambda_jv_j^Tv_j=\lambda_j uTΣu=vjTΣvj=λjvjTvj=λj
因此 u 1 = v 1 u_1=v_1 u1=v1特征向量对应最大的特征值。
证明:第j个主成分, u j u_j uj是第j大的协方差矩阵的特征向量。
j=2
u 2 = a r g m a x ∣ ∣ u ∣ ∣ = 1 , u 1 T u = 0 u T Σ u u_2=argmax_{||u||=1,u_1^Tu=0}u^T\Sigma u u2=argmax∣∣u∣∣=1,u1Tu=0uTΣu
拉格朗日函数:
L ( u ) = − u T Σ u + β 1 ( u T u − 1 ) + β 2 ( u 1 T u ) L(u)=-u^T\Sigma u+\beta_1(u^Tu-1)+\beta_2(u_1^Tu) L(u)=−uTΣu+β1(uTu−1)+β2(u1Tu)
最小化 L ( u ) : L(u): L(u):
β 2 = 0 , Σ u = β 1 u \beta_2=0, \Sigma u=\beta_1u β2=0,Σu=β1u
最大化 u T Σ u = λ , u 2 u^T\Sigma u=\lambda,u_2 uTΣu=λ,u2必须是第二大特征值对应的特征向量 β 1 = λ 2 \beta_1=\lambda_2 β1=λ2.
2.4 PCA性质
- 主成分投影的方差是: V a r ( x T u j ) = u j T Σ u j = λ j Var(x^Tu_j)=u_j^T\Sigma u_j=\lambda_j Var(xTuj)=ujTΣuj=λj,j=1,2…n
- % 由第j主成分解释的方差可以被表示成 λ j ∑ i = 1 n λ i \frac{\lambda_j}{\sum_{i=1}^n\lambda_i} ∑i=1nλiλj
- 同样可通过前K主成分解释 ∑ j = 1 k λ j ∑ j = 1 n λ j \frac{\sum_{j=1}^k\lambda_j}{\sum_{j=1}^n\lambda_j} ∑j=1nλj∑j=1kλj
2.5 PCA 投影
样本在主成分空间的投影:
z ( i ) = [ x ( i ) T u 1 . . . . x ( i ) T u n ] ∈ R n z^{(i)}=\begin{bmatrix}x^{(i)^T}u_1\\....\\x^{(i)^T}u_n\end{bmatrix}\in R^n z(i)=⎣⎡x(i)Tu1....x(i)Tun⎦⎤∈Rn
矩阵表示:
z ( i ) = [ . . . . . . . . . . . . u 1 . . . . u n . . . . . . . . . . . . ] T x ( i ) = W T x ( i ) , o r Z = X W z^{(i)}=\begin{bmatrix}....&....&....\\u_1&....&u_n\\....&....&....\end{bmatrix}^Tx^{(i)}=W^Tx^{(i)},or \quad Z=XW z(i)=⎣⎡....u1....................un....⎦⎤Tx(i)=WTx(i),orZ=XW
仅用前K个主成分用来降维。
2.5 PCA理解
PCA移除了输入数据的冗余。
Z = X W Z=XW Z=XW为PCA的投影数据。
c o v ( Z ) = 1 n Z T Z = 1 n ( X W ) T ( X W ) = W T ( 1 n X T X ) W = W T Σ W cov(Z)=\frac{1}{n}Z^TZ=\frac{1}{n}(XW)^T(XW)=W^T(\frac{1}{n}X^TX)W=W^T\Sigma W cov(Z)=n1ZTZ=n1(XW)T(XW)=WT(n1XTX)W=WTΣW
因为 Σ \Sigma Σ是对称的,有特征值,特征分解为:
Σ = W Λ W T \Sigma =W\Lambda W^T Σ=WΛWT
W = [ . . . . . . . . . . . . u 1 . . . . u n . . . . . . . . . . . . ] , Λ = [ λ 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . λ n ] W=\begin{bmatrix}....&....&....\\u_1&....&u_n\\....&....&....\end{bmatrix},\Lambda=\begin{bmatrix}\lambda_1&....&....\\....&....&....\\....&....&\lambda_n\end{bmatrix} W=⎣⎡....u1....................un....⎦⎤,Λ=⎣⎡λ1............................λn⎦⎤
c o v ( Z ) = W T ( W Λ W T ) W = Λ cov(Z)=W^T(W\Lambda W^T)W=\Lambda cov(Z)=WT(WΛWT)W=Λ
主成分变换 X W XW XW对角化 X X X的样本协方差矩阵。
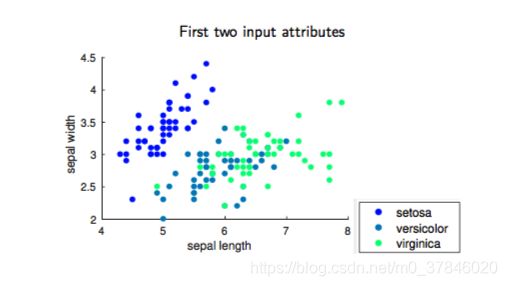
2.6 PCA例子
鸢尾花数据

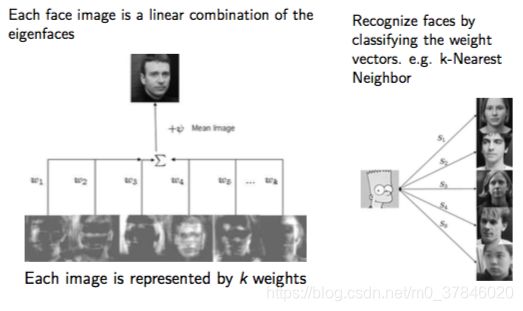
人脸特征

2.7 PCA 的缺点
- 只考虑了数据特征之间的线性关系
- 假设数据是真实并且连续的
- 假设输入空间的近似正态性(但在实践中,对于非正态分布的数据仍然可以很好)
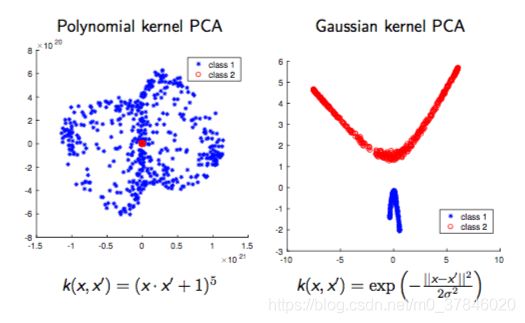
非正态分布输入:

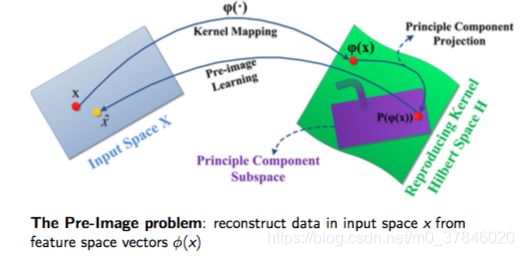
2.7 PCA核心
利用PCA特征提取。

线性的PCA假设数据在 R n R^n Rn是可分的.
非线性推广:
- 将数据投影到更高维度使用特征映射。 R n → R d ( d ≥ n ) R^n \rightarrow R^d(d≥n) Rn→Rd(d≥n)
- 特征映射通过定义核函数 K ( x ( i ) , x ( j ) ) = ϕ ( x ( i ) ) T ϕ ( x ( j ) ) K(x^{(i)},x^{(j)})=\phi(x^{(i)})^T\phi(x^{(j)}) K(x(i),x(j))=ϕ(x(i))Tϕ(x(j))或者核矩阵 K ∈ R m × n K\in R^{m\times n} K∈Rm×n
特征映射数据的样本的协方差矩阵:
Σ = 1 m ∑ i = 1 m ϕ ( x ( i ) ) ϕ ( x ( i ) ) T ∈ R d × d \Sigma=\frac{1}{m}\sum_{i=1}^m\phi(x^{(i)})\phi(x^{(i)})^T\in R^{d\times d} Σ=m1i=1∑mϕ(x(i))ϕ(x(i))T∈Rd×d
让 ( λ k , v k ) , k = 1 , . . . . d (\lambda_k,v_k),k=1,....d (λk,vk),k=1,....d是 Σ \Sigma Σ的特征分解。
Σ v k = λ k v k \Sigma v_k=\lambda_k v_k Σvk=λkvk
x ( l ) x^{(l)} x(l)在第k主成分 v k v_k vk的PCA投影是:
ϕ ( x ( l ) ) T v k \phi(x^{(l)})^Tv_k ϕ(x(l))Tvk
为了避免计算 ϕ ( x ( l ) ) \phi(x^{(l)}) ϕ(x(l)),于是:
Σ v k = ( 1 m ∑ i = 1 m ϕ ( x ( i ) ) ϕ ( x ( i ) ) T ) v k = λ k v k \Sigma v_k=(\frac{1}{m}\sum_{i=1}^m\phi(x^{(i)})\phi(x^{(i)})^T)v_k=\lambda_kv_k Σvk=(m1i=1∑mϕ(x(i))ϕ(x(i))T)vk=λkvk
把 v k v_k vk写成 ϕ ( x ( 1 ) ) . . . . ϕ ( x ( m ) ) \phi(x^{(1)})....\phi(x^{(m)}) ϕ(x(1))....ϕ(x(m))的线性组合:
v k = ∑ i = 1 m α k i ϕ ( x ( i ) ) v_k=\sum_{i=1}^m\alpha_k^i\phi(x^{(i)}) vk=i=1∑mαkiϕ(x(i))
x ( l ) x^{(l)} x(l)的PCA投影通过使用K函数表示:
ϕ ( x ( l ) ) T v k = ϕ ( x ( l ) ) T ∑ i = 1 m α k i ϕ ( x ( i ) ) = ∑ i = 1 m α k i K ( x ( l ) , x ( i ) ) \phi(x^{(l)})^Tv_k=\phi(x^{(l)})^T\sum_{i=1}^m\alpha_k^i\phi(x^{(i)})=\sum_{i=1}^m\alpha_k^iK(x^{(l)},x^{(i)}) ϕ(x(l))Tvk=ϕ(x(l))Ti=1∑mαkiϕ(x(i))=i=1∑mαkiK(x(l),x(i))
怎么计算 α k i \alpha_k^i αki:
Σ v k = ( 1 m ∑ i = 1 m ϕ ( x ( i ) ) ϕ ( x ( i ) ) T ) v k = λ k v k \Sigma v_k=(\frac{1}{m}\sum_{i=1}^m\phi(x^{(i)})\phi(x^{(i)})^T)v_k=\lambda_kv_k Σvk=(m1i=1∑mϕ(x(i))ϕ(x(i))T)vk=λkvk
用 v k = ∑ i = 1 m α k i ϕ ( x ( i ) ) v_k=\sum_{i=1}^m\alpha_k^i\phi(x^{(i)}) vk=∑i=1mαkiϕ(x(i))代替:
K α k = λ k m α k K\alpha_k=\lambda_km\alpha_k Kαk=λkmαk
于是 α k = [ α k 1 . . . . α k m ] \alpha_k=\begin{bmatrix}\alpha_k^1\\....\\\alpha_k^m\end{bmatrix} αk=⎣⎡αk1....αkm⎦⎤可以通过求K的特征分解来得出。
正则化 α k \alpha_k αk以便于使 v k T v k = 1 v_k^Tv_k=1 vkTvk=1
v k T v k = ∑ i = 1 m ∑ j = 1 m α k i α k j ϕ ( x ( i ) ) T ϕ ( x ( j ) ) = α k T K α k = λ k m ( α k T α k ) v_k^Tv_k=\sum_{i=1}^m\sum_{j=1}^m\alpha_k^i\alpha_k^j\phi(x^{(i)})^T\phi(x^{(j)})=\alpha_k^TK\alpha_k=\lambda_km(\alpha_k^T\alpha_k) vkTvk=i=1∑mj=1∑mαkiαkjϕ(x(i))Tϕ(x(j))=αkTKαk=λkm(αkTαk)
∣ ∣ α k ∣ ∣ 2 = 1 λ k m ||\alpha_k||^2=\frac{1}{\lambda_km} ∣∣αk∣∣2=λkm1
当 E ( ϕ ( x ) ) ≠ 0 E(\phi(x))\ne0 E(ϕ(x))̸=0,我们需要重新计算 ϕ ( x ) \phi(x) ϕ(x):
ϕ ^ ( x ( i ) ) = ϕ ( x ( i ) ) − 1 m ∑ l = 1 m ϕ ^ ( x ( l ) ) \hat\phi(x^{(i)})=\phi(x^{(i)})-\frac{1}{m}\sum_{l=1}^m\hat\phi(x^{(l)}) ϕ^(x(i))=ϕ(x(i))−m1l=1∑mϕ^(x(l))
中心化之后的K函数:
K ^ i , j = ϕ ^ ( x ( i ) ) T ϕ ^ ( x ( j ) ) \hat K_{i,j}=\hat \phi(x^{(i)})^T\hat \phi(x^{(j)}) K^i,j=ϕ^(x(i))Tϕ^(x(j))
矩阵表示:
K ^ = K − 1 m K − K 1 m + 1 m K 1 m , 1 m = [ 1 m . . . . 1 m . . . . . . . . . . . . 1 m . . . . 1 m ] \hat K=K-1_mK-K1_m+1_mK1_m,\quad 1_m=\begin{bmatrix}\frac{1}{m}&....&\frac{1}{m}\\....&....&....\\\frac{1}{m}&....&\frac{1}{m}\end{bmatrix} K^=K−1mK−K1m+1mK1m,1m=⎣⎡m1....m1............m1....m1⎦⎤
然后使用 K ^ \hat K K^来计算PCA.

- 经常在聚类、异常检测中使用PCA.
- 投影到k维约简子空间一般是不可能的.
2.8 总结
表示学习:
- 把一些特征表达的更加简单和便于理解。
- 通常在特征提取、降维、分类问题中使用。
