干货!基于深度学习的向量嵌入技术在时间序列相似性查询中的应用
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
相似性搜索是时间序列分析的一个基本操作。根据最近的研究,基于iSAX的索引在相似性搜索中达到了目前的最优水平。然而,它们的性能在高频、弱时序相关或其他特定于数据集的属性下会显著降低。在这项工作中,我们提出了一种基于深度神经网络的新型时间序列摘要DEA,并专为学习DEA设计了网络架构SEAnet。为了有效地在海量数据集上训练SEAnet,我们提出了一种新的时间序列采样算法SEASam与传统iSAX和其他架构相比,使用SEAnet学习的DEA在7个不同的合成与真实数据集上都达到了最优的近似搜索水平。论文代码、预训练模型和数据集均已开源在htps://qtwang.github.io/kdd21-seanet。
本期AI TIME PhD直播间,我们邀请到巴黎大学博士生——王齐童,为我们带来报告分享《基于深度学习的向量嵌入技术在时间序列相似性查询中的应用》。

王齐童,巴黎大学在读博士生,在Themis Palpanas教授的指导下进行基于机器学习的时间序列管理与挖掘研究,同时关注相关技术在神经科学、天体物理等领域的实际应用。已在相关领域发表多篇论文。
个人主页是https://qtwang,github.io。
01
背 景
时间序列是将观测值按照时间发生的先后顺序(或其他领域相关的顺序定义)排列而成的数列。比如随着时间变化生成的人体脑电图数据(下图左),以及按照时间顺序生成的地震波数据(下图右),里面都展示了在同一时间段的不同时间序列。

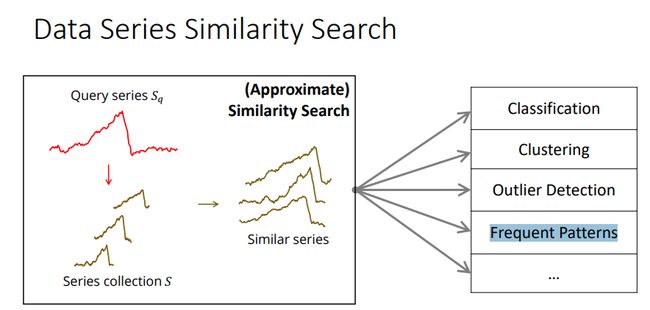
对时间序列进行相似性查询即给定一个时间序列和时间序列数据集,使用某些相似性度量的方法(本文采用欧氏距离进行相似性度量),按相似性排序,查找与给定序列最相似的时间序列。在本文中,采用近似查询的方式,即查询目标放宽为接近最相似序列即可。相似性查询在分类任务、聚类任务、异常点检测、频繁模式挖掘中都发挥很重要的作用,比如作为最近邻分类器的底层技术。
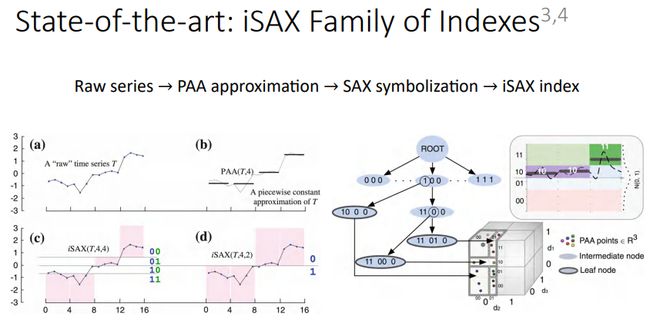
目前时间序列相似性查询的工作中,SOTA方法之一是基于iSAX索引的相似性查询。iSAX方法的基本思路是首先将给定的原始时间序列(a)使用PAA进行降维(b),即均匀分段后每段取均值;然后将每段的值通过SAX符号化进行离散处理形成一个符号编码(c),就可以通过在每段中使用不同的编码位数(d)构建前缀树,从而实现时间序列的索引。一般来讲,当我们需要查询非常大量级(比如亿条以上)的时间序列时,iSAX是最常用的方法。
iSAX方法非常依赖PAA对原始时间序列进行近似处理的效果。当PAA对时间序列描述的不够好,那iSAX的表现也会受到很大影响,比如下图这个例子,灰色线表示原始时间序列,蓝色线表示使用DFT(离散傅里叶变换)来拟合原始时间序列,绿色线表示PAA方法。在左图展示的一条随机游走序列中,PAA和DFT都可以较好的模拟原始序列,保留序列的趋势;但在右图展示的Deep1B(图像嵌入)序列中,PAA的近似值基本是0,没有描述序列趋势。所以,当遇到Deep1B这类弱时序相关(且相对高频)的序列时,iSAX的表现就不会那么好。

本文提出的解决方法是用适用性更好的时间序列低维描述技术,也就是向量嵌入(DEA),来代替PAA构建索引。下图是对上面两个序列加入了DEA方法进行描述(红色线),可以看出DEA在这两个序列的表现都是最贴合原始序列的,即总结描述能力最强的。

02
方 法
如何生成一个可在大规模序列数据集上进行相似性查询的高效DEA呢?
(1)SEANet
本文提出了SEANet,该网络是一个dilated ResNet(含空洞卷积的ResNet),其空洞卷积是指数级增长的,并且加入了一个Sum of Squares (SOS) 约束。
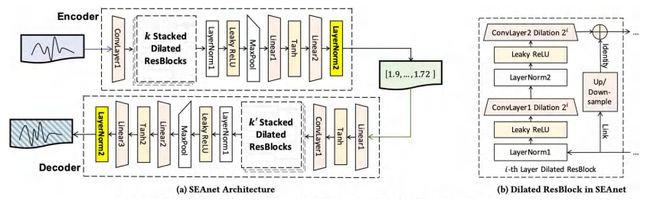
下图(a)是SEANet的总体架构,图(b)是空洞卷积残差块的详细逻辑展示。SEANet在encoder和decoder的末尾都加了一个归一化层,作为SOS约束的一部分;这对提高DEA质量是很有帮助的。另外在很多工作中,向量嵌入模型只有encoder,但在SEANet中专门保留了decoder。原因是由于decoder需要还原原始序列,因此DEA中会为此保留一些序列自身特有的信息,从而增加彼此之间的区分度。这作为一种特别的约束来防止DEA坍缩到一些简单解(比如全部为0)是很有效的。
损失函数部分采用了一个复合损失函数的形式,第一项是Compression error(序列压缩误差),将成对的原始序列映射到嵌入空间,序列对在嵌入空间的距离和原始空间的距离越接近越好;第二项 Reconstruction error(序列重建误差),即原始序列和重建的嵌入序列越接近越好。图中蓝色部分的系数是专为SOS约束设计的,细节可以参考论文原文。

(2)SEAsam
那如何在大规模数据集上有效地训练模型呢?本文采取采样的方式,称为SEAsam(SEA-sampling),在大规模数据集上进行序列采样,在采样后的数据集上进行训练,然后将训练好的模型在整个数据集上进行相似性查询。
本文对排序的设计思路是首先对高维的时间序列进行排序,相邻的序列被放置在相近的位置上(类似[1, 2, 3, …, 9, 10],但不需要是单调序列),在排列的数据集上进行均匀间隔采样;从而利用这种非参方法,尽可能地使采样集的分布逼近数据集的分布。
本文提出了用时间序列的InvSAX表示进行排序。下图示例如何将SAX表示转化成InvSAX表示:收集每段的第一个bit值,放到InvSAX最前的4个bit;然后再收集每段的第二个bit值,放到InvSAX的4-8个bit中;以此类推,得到完整的InvSAX。然后按照生成的InvSAX的二进制数值的前后顺序进行排序,得到带序的数据集,然后就可以均匀间隔采样了。

03
实 验
数据集:本文采用的数据集包含3个合成数据集(RandWalk, F5, F10)和4个真实数据集(Seismic, SALD, Deep1B, Astro),详细信息如下。

Baseline方法:PAA(也即标准iSAX)
其他对比方法:
• SEAnet-nD (没有decoder的SEANet版本)
• TimeNet, FDJNet, InceptionTime(针对相似性查询进行了必要的修改)
实验结果:
下面是本文方法和其他时间序列相似性查询在不同数据集上的对比,在后面几个真实数据集上,本文算法的优势更大。

提
醒
论文:
《ImGAGN: Imbalanced Network Embedding via Generative Adversarial Graph Networks》
点击阅读原文
即可观看分享回放哦!
今日视频推荐
整理:爱国
审核:王齐童
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

我知道你在看哟

点击“阅读原文”查看精彩回放