案例实战:用户评论情感分析模型
目录
- 一.案例背景
- 二.读取数据
- 三.中文分词
- 四. 构造特征变量和目标变量
-
- 1.数据向量化
- 2.目标变量的提取
- 五.神经网络模型搭建和使用
-
- 1.划分数据集
- 2.搭建神经网络模型
- 3.模型使用
- 总结
一.案例背景
情感分析是自然语言处理领域最为经典的应用之一,一直长盛不衰,特别是互联网发展极大提高了每个人的参与度,网上购物,美团外卖等,很多人都会买完东西都会去填写几句简单的评价,我们很多时候比如买一个东西都会先从淘宝或者京东上进行查看,当两种货物基本差不多的时候,我们会去看买家评论,根据好评的多少进行抉择,用户在电商平台上面发布的产品评价中包含着用户的偏好信息,利用情感分析模型可以从产品评价的评价中获得用户的情感及对产品属性的偏好,在此基础上,就可以进一步利用智能推荐系统向用户推荐他们更喜欢的产品,以增加用户的黏性,挖掘一些潜在的利润。
二.读取数据
import pandas as pd
df = pd.read_excel(r"D:\Python\产品评价.xlsx")
df.head()
数据读取结果查看:
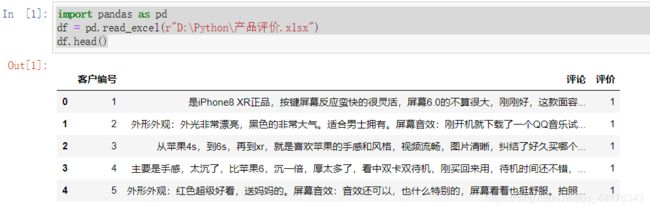
三.中文分词
中文分词:英文分词比较简单,见到空格和标点符号就说明是一个词汇,而中文分词就是将一句话拆分成一些词语,在python中有专门的中文分词库jieba库,cut()函数专门进行对指定的文本内容进行分词。
import jieba
word = jieba.cut(df.iloc[0]['评论'])
result = " ".join(word)
print(result)
执行结果:
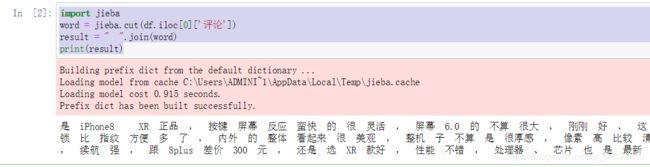
上面代码只是对第一行进行分割,下面通过循环进行对所有的进行分割。
words= []
for i,row in df.iterrows():
word = jieba.cut(row['评论'])
result = ' '.join(word)
words.append(result)
print(words)
执行结果:

四. 构造特征变量和目标变量
1.数据向量化
上面我们已经将每一条评论消息分词完毕存储到words列表中,下面需要将文本类型的数据转换成数值类型的数据,以便构成特征变量以及训练模型,python一般用CountVectorizer()函数,将文本数据转换为数值数据。将每个词就构成这个评论的词袋,最开始是为英文做的单词向量化,词袋就是一个字典,每个词就是字典的键,对应的编号就是字典的值。
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer() #将文本转换为数值,构成特征向量
X = vect.fit_transform(words)
X = X.toarray()
查看向量化后的词袋
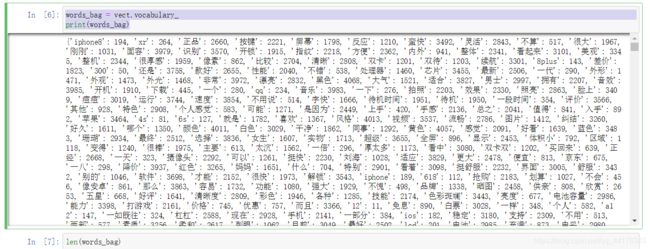
向量化后的词袋就是对评论进行去重,在对不同的词进行编号。
words_bag = vect.vocabulary_
print(words_bag)
执行结果:
*-
查看一下词袋中有多少个词:
len(words_bag)
执行结果:

转换格式
为了方便我们查看,我们可以转化成DataFrame格式。
import pandas as pd
pd.DataFrame(X) #为了更好地查看X,将其转换成DataFrame
执行结果:
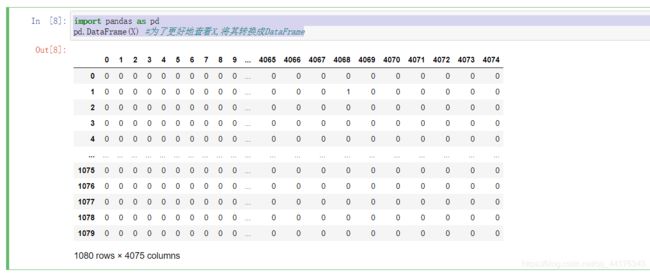
查看全部数据的代码:
import pandas as pd
pd.set_option('display.max_columns',None) #显示所有列
pd.set_option('display.max_rows',None) #显示所有的行
pd.DataFrame(X)
执行结果:
2.目标变量的提取
y = df['评价']
将目标数据输出查看:
至此,我们就完成模型搭建中最重要的一步就是数据读取和处理工作。
五.神经网络模型搭建和使用
1.划分数据集
为了训练模型和测试训练的效果,需要将数据分为训练集和测试集。
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.1,random_state = 1)
2.搭建神经网络模型
搭建简单的神经网络模型
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier()
mlp.fit(X_train,y_train)
3.模型使用
对测试集数据进行预测:
y_pred = mlp.predict(X_test)
我们打印出测试集预测数据y_pred,结果如下:

汇总预测值和实际值,方便进行对比和查看。
a = pd.DataFrame() #创建一个空的DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_pred)
a.head()#查看我们创建的DataFrame
执行结果如下:
查看一下测试集数据的预测准确度。代码如下:
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred,y_test)
我们通过打印查看预测准确度:
print(score)
执行结果如下:
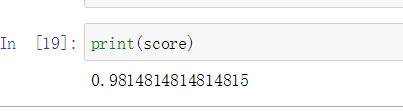
获得模型准确度评分为0.981,这就说明模型的预测准确度达到了98.1%。
还可以输入一些数据集以外的评价,看看模型能否准确地给出判断,代码如下:
comment = input("请输入你对商品的评价:")
comment = [' '.join(jieba.cut(comment))]
print(comment)
X_try = vect.transform(comment)
y_pred = mlp.predict(X_try.toarray())
print(y_pred)
执行结果:
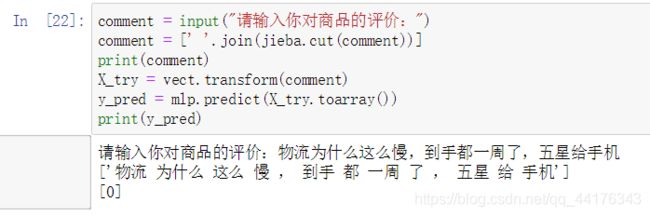
预测结果为0,代表差评,与我们期望的一致。
总结
神经网络是一种非常不错的机器学习模型,其学习速度快,预测效果好,不过对于其他传统模型相比,其可解释性不是很好,因此被称为“黑盒模型”。
参考文献:python大数据分析与机器学习商业分析案例实战