神经网络模型——用户评论情感分析
数据读取、中文分词、文本向量化
1.数据读取
import pandas as pd
df = pd.read_excel('产品评价.xlsx')
df.head()
2.中文分词
# 为了循序渐进,这里先演示第一条评论的分词效果
import jieba
word = jieba.cut(df.iloc[0]['评论'])
result = ' '.join(word)
print(result)
# 遍历整张表格,对所有评论进行分词
words = []
for i, row in df.iterrows():
word = jieba.cut(row['评论'])
result = ' '.join(word)
words.append(result)words[0:3] 
# 如果对上面过程如果熟悉后,也可以直接写成如下的合并代码形式
words = []
for i, row in df.iterrows():
words.append(' '.join(jieba.cut(row['评论'])))3.文本向量化
# 文本向量化CountVectorizer()函数的使用技巧:使用示例
from sklearn.feature_extraction.text import CountVectorizer
test = ['手机 外观 漂亮', '手机 图片 清晰']
vect = CountVectorizer()
X = vect.fit_transform(test)
X = X.toarray()words_bag = vect.vocabulary_
print(words_bag)![]()
# 实际应用
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
X = vect.fit_transform(words)
X = X.toarray()
print(X)
words_bag = vect.vocabulary_
print(words_bag) 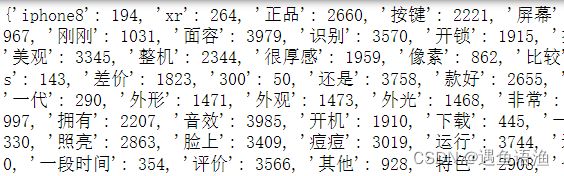
import pandas as pd
# pd.set_option('display.max_columns', None) # 添加这行代码可以显示所有列,如果讲None改成500,则表示可最多显示500列
# pd.set_option('display.max_rows', None) # 添加这行代码可以显示所有行,如果讲None改成500,则表示可最多显示500行
pd.DataFrame(X).head() 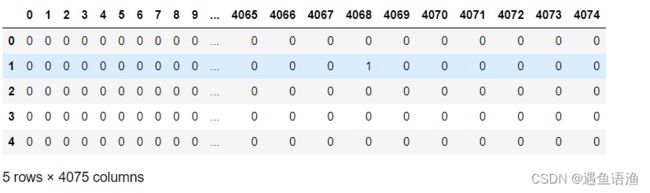
4.目标变量提取
y = df['评价']
y.head()
神经网络模型的搭建与使用
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=1)
from sklearn.neural_network import MLPClassifier
mlp =MLPClassifier() # 因为模型运行具有随机性,如果想让每次运行结果一致,可以设置random_state随机参数为任一数字,如MLPClassifier(random_state=123)
mlp.fit(X_train, y_train)y_pred = mlp.predict(X_test)
print(y_pred) # 因为模型运行具有随机性,所以这里得到的结果可能和书上的略有不同,如果想让每次运行结果一致,可以设置random_state随机参数为任一数字,如MLPClassifier(random_state=123)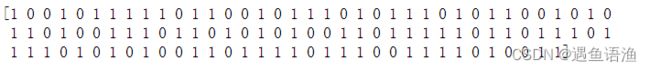
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head() 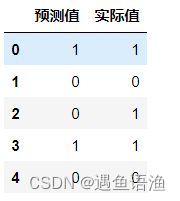
# 获取预测准确度
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
score![]()
# 自我体验
comment = input('请输入您对本商品的评价:')
comment = [' '.join(jieba.cut(comment))]
print(comment)
X_try = vect.transform(comment)
y_pred = mlp.predict(X_try.toarray())
print(y_pred)
# 朴素贝叶斯模型对比
from sklearn.naive_bayes import GaussianNB
nb_clf = GaussianNB()
nb_clf.fit(X_train,y_train)
y_pred = nb_clf.predict(X_test)
print(y_pred)
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)