redis学习+实践
Redis
redis官方的在线环境,练习常用命令很方便。
✨⭐✔ ┃ ☝
基础篇
Redis入门
键值对数据库
1.1.认识Nosql
与sql对比
-
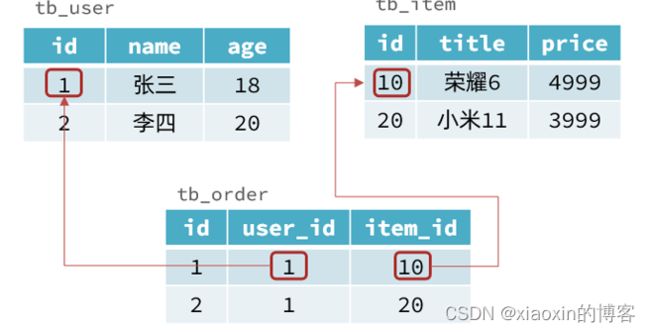
结构化:如图,数据之间有固定化格式要求;而nosql的取决于数据库类型,如键值对、文档、图类型。

-
关联的:外键/类外键,减少冗余信息存储,删除时有保护;而nosql是json字符串的嵌套形式,数据存储有重复。
-
sql查询:
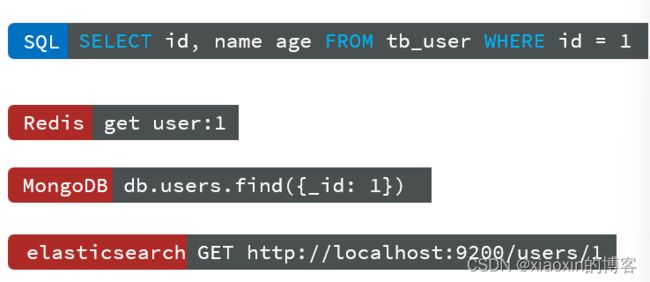
-
ACID:基本一致,BASE,基本满足
总结
所谓垂直,即数据库虽然可以主从,但并没有提升存储,只是提升读写;仅仅做了备份;
1.2.认识Redis
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存、IO多路复用、良好的编码)。
- 支持数据持久化(断电内存数据会消失)
- 支持主从集群(备份,读写分离)、分片集群(提高存储上限,水平扩展)
- 支持多语言客户端
跳跃表
1、什么是跳跃表
跳跃链表是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉排序树(对于大多数操作需要O(log n)平均时间),并且对并发算法友好。
基本上,跳跃列表是对有序的链表增加上附加的前进链接,增加是以随机化(抛硬币)的方式进行的,所以在列表中的查找可以快速的跳过部分列表(因此得名)。所有操作都以对数随机化的时间进行。
2、跳跃表原理
查询链表的时间复杂度
搜索链表中的元素时,无论链表中的元素是否有序,时间复杂度都为O(n),如下图,搜索103需要查询9次才能找到该节点

但是能够提高搜索的其他数据结构,如:二叉排序树、红黑树、B树、B+树等等的实现又过于复杂。有没有一种相对简单,同时又能提搜索效率的数据结构呢,跳跃表就是这样一种数据结构。
Redis中使用跳跃表好像就是因为一是B+树的实现过于复杂,二是Redis只涉及内存读写,所以最后选择了跳跃表。
跳跃表实现——搜索
为了能够更快的查找元素,我们可以在该链表之上,再添加一个新链表,新链表中保存了部分旧链表中的节点,以加快搜索的速度。如下图所示
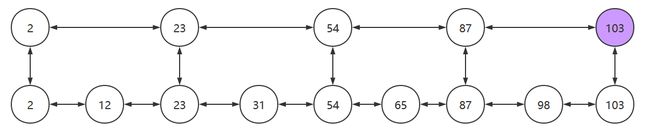
我们搜索元素时,从最上层的链表开始搜索。当找到某个节点大于目标值或其后继节点为空时,从该节点向下层链表搜寻,然后顺着该节点到下一层继续搜索。
比如我们要找103这个元素,则会经历:2->23->54->87->103
这样还是查找了5次,当我们再将链表的层数增高以后,查找的次数会明显降低,如下图所示。3次便找到了目标元素103

代码中实现的跳表结构如下图所示
一个节点拥有多个指针,指向不同的节点

跳跃表实现——插入
跳跃表的插入策略如下
-
先找到合适的位置以便插入元素
-
找到后,将该元素插入到最底层的链表中,并且
抛掷硬币(1/2的概率)
- 若硬币为正面,则将该元素晋升到上一层链表中,并再抛一次
- 若硬币为反面,则插入过程结束
-
为了避免以下情况,需要在每个链表的头部设置一个 负无穷 的元素

设置负无穷后,若要查找元素2,过程如下图所示
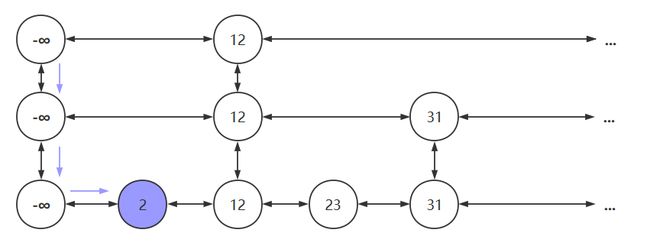
插入图解
- 若我们要将45插入到跳跃表中
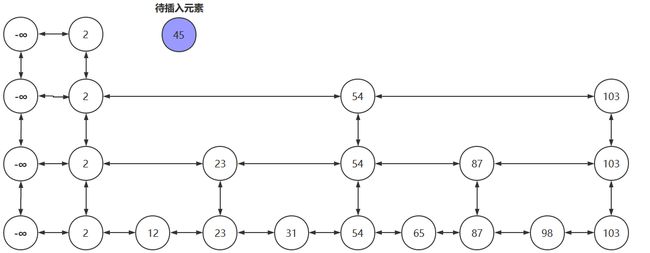
- 先找到插入位置,将45插入到合适的位置
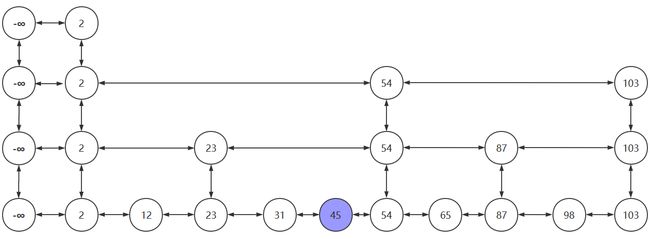
- 抛掷硬币:为正,晋升

- 假设硬币一直为正,插入元素一路晋升,当晋升的次数超过跳跃表的层数时,需要再创建新的链表以放入晋升的插入元素。新创建的链表的头结点为负无穷
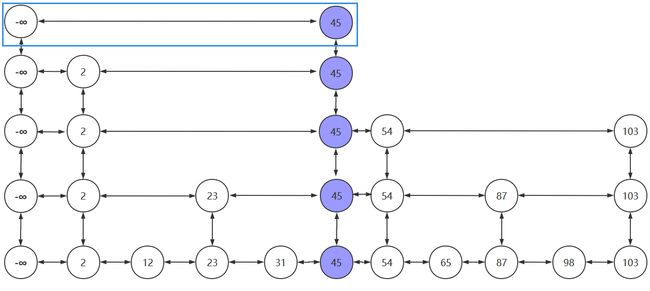
以上便是跳跃表的插入过程
3、Redis中的跳跃表
为什么Redis要使用跳跃表而不是用B+树
引用Redis作者 antirez 的原话
There are a few reasons:
1) They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
2) A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
3) They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
翻译一下
1) 它们不需要太多的内存。这基本上取决于你。改变一个节点具有给定级别数的概率的参数,会比btree占用更少的内存。
2) 排序集通常是许多ZRANGE或ZREVRANGE操作的目标,即作为链表遍历跳跃表。使用这种操作,跳跃表的缓存局部性至少与其他类型的平衡树一样好。
3)它们更容易实现、调试等等。例如,感谢跳跃表的简单性,我收到了一个补丁(已经在Redis master),增强跳跃表实现ZRANK在O(log(N))。它只需要对代码做一点小小的修改。Copy
MySQL使用B+树的是因为:叶子节点存储数据,非叶子节点存储索引,B+树的每个节点可以存储多个关键字,它将节点大小设置为磁盘页的大小,充分利用了磁盘预读的功能。每次读取磁盘页时就会读取一整个节点,每个叶子节点还有指向前后节点的指针,为的是最大限度的降低磁盘的IO;因为数据在内存中读取耗费的时间是从磁盘的IO读取的百万分之一
而Redis是内存中读取数据,不涉及IO,因此使用了跳跃表
既然提到了Redis是对内存操作的,那么再讨论一个问题:为什么Redis是单线程的还这么快呢
Redis使用单线程效率还很高的原因
假设有两个任务A和B,分别有两种方法来执行他们
- 两个线程并发执行:先执行A一段时间,然后切换到B再执行一段时间,然后又切换回A执行… 直到A和B都执行完毕
- 两个线程串行执行:先执行A,A执行完了在执行B
对于单核CPU来说,第二种方法的执行时间更短,效率更高。因为单核CPU下的并发操作,会导致上下文的切换,需要保存切换线程的信息,这段时间CPU无法去执行任何任务中的指令,时间白白浪费了
对于I/O操作,并发执行效率更高
因为I/O操作主要有以下两个过程
- 等待I/O准备就绪
- 真正操作I/O资源
等待I/O准备就绪这个阶段,CPU是空闲的,这时便可以去执行其他任务,这样也就提高了CPU的利用率
而Redis是基于内存的操作,没有I/O操作,所以单线程执行效率更高
4、Redis中跳表的实现
Redis中的sort_set主要由跳表实现,sort_set的添加语句如下
zadd key score1 member1 score2 member2 ...Copy
Redis中的跳表结构如下
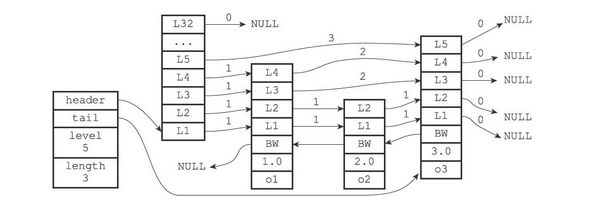
Redis中的跳表主要由节点zskiplistNode和跳表zskiplist来实现,他们的源码如下
zskiplistNode
typedef struct zskiplistNode {
// 存储的元素 就是语句中的member
sds ele;
// 分值,就是语句中的score
double score;
// 指向前驱节点
struct zskiplistNode *backward;
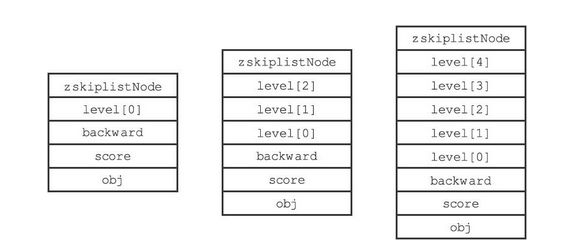
// 层,每个节点有1~32个层,除头结点外(32层),其他节点的层数是随机的
struct zskiplistLevel {
// 每个层都保存了该节点的后继节点
struct zskiplistNode *forward;
// 跨度,用于记录该节点与forward指向的节点之间,隔了多少各节点。主要用于计算Rank
unsigned long span;
} level[];
} zskiplistNode;Copy
各个属性的详细解释
- ele:sds变量,保存member。
- score:double变量,用于保存score
- 注意:score和ele共同来决定一个元素在跳表中的顺序。score不同则根据score进行排序,score相同则根据ele来进行排序
- 跳表中score是可以相同的,而ele是肯定不同的
- backward:前驱指针,用于保存节点的前驱节点,每个节点只有一个backward
- 例:如果要从第四层的节点访问第三层的节点,则可以通过backward直接访问
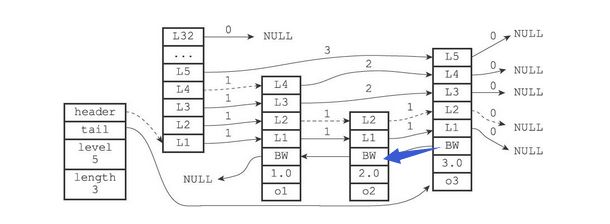
- 例:如果要从第四层的节点访问第三层的节点,则可以通过backward直接访问
- level[]:节点的层,每个节点拥有1~32个层,除头结点外(32层),其他节点的层数是随机的。注意:Redis中没有使用抛硬币的晋升策略,而是直接随机一个层数值。下图展示了层数不同的几个节点
- level:保存了该节点指向的下一个节点,但是不一定是紧挨着的节点。还保存了两个节点之间的跨度
- forward:后继节点,该节点指向的下一个节点,但是不一定是紧挨着的节点
- span:跨度,用于记录从该节点到forward指向的节点之间,要走多少步。主要用于计算Rank
- rank:排位,头节点开始到目标节点的跨度,由沿途的span相加获得
- level:保存了该节点指向的下一个节点,但是不一定是紧挨着的节点。还保存了两个节点之间的跨度
zskiplist
zskiplist的源码如下
typedef struct zskiplist {
// 头尾指针,用于保存头结点和尾节点
struct zskiplistNode *header, *tail;
// 跳跃表的长度,即除头结点以外的节点数
unsigned long length;
// 最大层数,保存了节点中拥有的最大层数(不包括头结点)
int level;
} zskiplist;Copy
遍历过程
遍历需要访问跳表中的每个节点,直接走底层的节点即可依次访问
搜索过程
如我们要访问该跳表中score = 2.0的节点

从高层依次向下层遍历
- 头结点的L6~L32的 forward 都为空,从L5开始访问
- 头结点L5的 forward 的指向的node3的score为3.0,小于2.0,返回头结点
- 从头结点L4 的 forward 指向的node1开始访问,节点的score = 1.0,继续向下执行
- 从node1的 L4 开始访问,为node3,返回node1
- 从node1的L3开始访问,为node3,返回node1
- 从node1的L2开始访问,为node2,score = 2.0,即为所要的节点
插入过程
插入节点时,需要找到节点的插入位置。并给节点的各个属性赋值。插入后判断是否需要拓展上层
实战篇
接口
BlogCommentsController.java
BlogController.java
FollowControllerjava
ShopController.java
ShopTypeContrller.java
UploadController.java
UserController.java
/**
* 发送手机验证码
*/
@PostMapping("code")
public Result sendCode(@RequestParam("phone") String phone, HttpSession session)
/**
* 登录功能
* @param loginForm 登录参数,包含手机号、验证码;或者手机号、密码
*/
@PostMapping("/login")
public Result login(@RequestBody LoginFormDTO loginForm, HttpSession session)
/**
* 登出功能
* @return 无
*/
@PostMapping("/logout")
public Result logout()
/**
获取当前登录的用户并返回
*/
@GetMapping("/me")
public Result me()
// 查询详情
@GetMapping("/info/{id}")
public Result info(@PathVariable("id") Long userId){
VoucherController.java
VoucherOrderController.java
短信验证码的登录注册功能
1.搭建黑马点评项目
数据模型
tb_user:用户表
tb_user_info:用户详情表
tb_shop:商户信息表
tb_shop_type:商户类型表
tb_blog:用户日记表(达人探店日记)
tb_follow:用户关注表
tb_voucher:优惠券表
tb_voucher_order:优惠券的订单表
在nginx所在目录下打开一个CMD窗口,输入命令
start nginx.exe
nginx -s stop 快速停止nginx
2.基于session的短信登录
流程
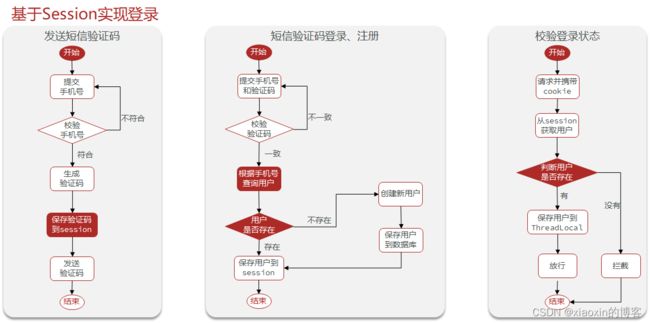
前端请求
请求验证码
| 说明 | |
|---|---|
| 请求方式 | POST |
| 请求路径 | /user/code |
| 请求参数 | phone,电话号码 |
| 返回值 | 无 |
验证码登录请求
| 说明 | |
|---|---|
| 请求方式 | POST |
| 请求路径 | /user/login |
| 请求参数 | phone:电话号码;code:验证码 |
| 返回值 | 无 |
后端代码
验证手机号
public static boolean isPhoneInvalid(String phone){
return mismatch(phone, RegexPatterns.PHONE_REGEX);
}
UserServiceImpl
发送验证码
@Override
public Result sendCode(String phone, HttpSession session) {
//验证手机号码格式
if (RegexUtils.isPhoneInvalid(phone)) {
//不对返回fail
return Result.fail("手机号格式错误");
}
//生成随机验证码
String code = RandomUtil.randomNumbers(6);
//存入session
session.setAttribute("code",code);
//发送验证码;模拟短信发送,在控制台可以看到; 这是lombok中自带的Slf4j
log.debug("成功发送验证码{}",code);
return Result.ok();
}
登录注册
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
//验证手机号
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)) {
//不对返回fail
return Result.fail("手机号格式错误");
}
//校验验证码
String loginFormCode = loginForm.getCode();
Object code = session.getAttribute("code");
if (code==null||!code.equals(loginFormCode)) {
return Result.fail("验证码错误");
}
//根据手机号查询
User user = query().eq("phone", phone).one();
if (StringUtils.isEmpty(user)){
//为空,则创建
user = createUser(phone);
}
//拷贝属性,其中UserDto为部分用户信息,脱敏之后的,同时也是为了不返回过多冗余信息;copyProperties是hutool工具包里的
session.setAttribute("user", BeanUtil.copyProperties(user, UserDTO.class));
return Result.ok();
}
private User createUser(String phone) {
User user = new User();
//链式调用
user.setPhone(phone).setNickName("user_"+RandomUtil.randomString(10));
save(user);
return user;
}
}
登录校验(拦截器)
每一个请求到达服务都是一个线程,用ThreadLocal保存(在线程内部创建一个map保存)比较合适(线程域对象),方便后面使用;如果是保存在本地变量,会有多线程并发修改的安全问题
public class UserHolder {
private static final ThreadLocal<UserDTO> tl = new ThreadLocal<>();
public static void saveUser(UserDTO user){
tl.set(user);
}
public static UserDTO getUser(){
return tl.get();
}
public static void removeUser(){
tl.remove();
}
}
拦截器
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1. 获取session
HttpSession session = request.getSession();
// 2.获取session中的用户
Object user = session.getAttribute("user");
// 3.判断用户是否存在
if (user == null) {
// 4.不存在,拦截
response.setStatus(401);
return false;
}
// 5.存在,保存用户信息到ThreadLocal
UserHolder.saveUser((UserDTO) user);
// 6.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 销毁user对象,防止内存泄露
UserHolder.removeUser();
}
}
前端钩子函数调用一个跳转函数,会请求/me这个接口,没查询到会跳转到login,所以记得写me接口
@GetMapping("/me")
public Result me(){
// 获取当前登录的用户并返回
UserDTO user = UserHolder.getUser();
return Result.ok(user);
}
此时点击+文章会跳转到login原因,后面会完善
checkLogin() {
// 获取token
let token = sessionStorage.getItem("token");
if (!token) {
location.href = "login.html"
}
// 查询用户信息
axios.get("/user/me")
.then()
.catch(err => {
this.$message.error(err);
setTimeout(() => location.href = "login.html", 200)
})
},
3.集群下的session共享问题
⭐session共享问题:多台Tomcat并不共享session存储空间,当请求切换到不同tomcat服务时导致数据丢失的问题。
session的替代方案应该满足:
- 数据共享
- 内存存储
- key、value结构

4.Redis实现共享session
修改前面的代码
发送验证码

@Autowired
private StringRedisTemplate redisTemplate;
@Override
public Result sendCode(String phone, HttpSession session) {
//验证手机号码格式
if (RegexUtils.isPhoneInvalid(phone)) {
//不对返回fail
return Result.fail("手机号格式错误");
}
//生成随机验证码
String code = RandomUtil.randomNumbers(6);
//存入session
// session.setAttribute("code",code);
redisTemplate.opsForValue().set(LOGIN_CODE_KEY+phone,code,LOGIN_CODE_TTL, TimeUnit.MINUTES);
//发送验证码;模拟短信发送,在控制台可以看到; 这是lombok中自带的Slf4j
log.debug("成功发送验证码{}",code);
return Result.ok();
}
验证登陆注册
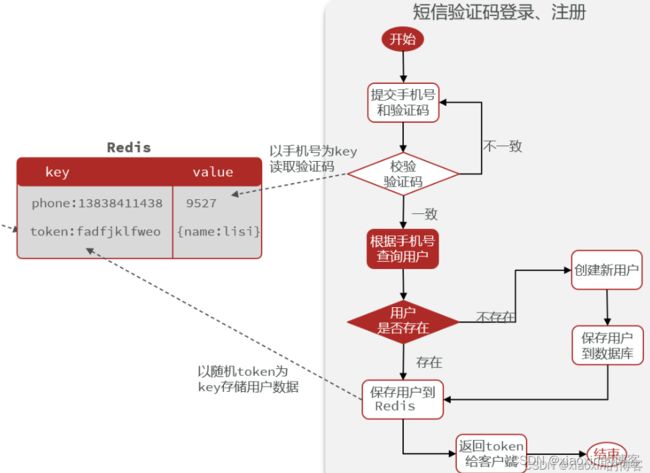
存储用户信息时,推荐使用putAll,这样只需要和数据库进行一次交互,否则多个字段会用多次put。
同时借鉴session,设置有效期30min,防止不停存储,内存被占满。

注意:StringRedisTemplate键值全是String(如下图),对象转换时要将非String类型转为String。
BeanUtil.beanToMap(userDTO, new HashMap<>(), CopyOptions.create()
.setIgnoreNullValue(true)
.setFieldValueEditor((fieldname, fieldvalue) -> fieldvalue.toString()));//提供一个函数式接口,编辑字段名和字段值;
![]()
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
//验证手机号
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)) {
//不对返回fail
return Result.fail("手机号格式错误");
}
//校验验证码
String loginFormCode = loginForm.getCode();
// Object code = session.getAttribute("code");
//从redis中查询
String code = redisTemplate.opsForValue().get(LOGIN_CODE_KEY + phone);
if (code==null||!code.equals(loginFormCode)) {
return Result.fail("验证码错误");
}
//根据手机号查询
User user = query().eq("phone", phone).one();
if (user==null){
//为空,则创建
user = createUser(phone);
}
//拷贝属性,其中UserDto为部分用户信息,脱敏之后的,同时也是为了不返回过多冗余信息
// session.setAttribute("user", BeanUtil.copyProperties(user, UserDTO.class));
//利用uuid,生成随机token令牌
String token = UUID.randomUUID().toString(false);
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
String tokenkey = LOGIN_USER_KEY + token;
//user对象转为hashmap存储
Map<String, Object> map = BeanUtil.beanToMap(userDTO, new HashMap<>(), CopyOptions.create()
.setIgnoreNullValue(true)
.setFieldValueEditor((fieldname, fieldvalue) -> fieldvalue.toString()));
redisTemplate.opsForHash().putAll(tokenkey,map);
redisTemplate.expire(tokenkey,LOGIN_USER_TTL,TimeUnit.MINUTES);
return Result.ok();
}
token返回给客户端后,会被存储在sessionlocalstorage中
登录校验(拦截)

因为拦截器不是与spring管理的bean,是我们自己new的,无法自动注入StringRedisTemplate,使用构造器方式注入。在webmvcConfig中,new时注入进去
public class LoginInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public LoginInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1. 获取请求头中的token,判断token是否存在
String token = request.getHeader("authorization");
if (StrUtil.isEmpty(token)) {
// token不存在,拦截,返回401状态码
response.setStatus(401);
return false;
}
// 2.基于token获取redis中的用户
String tokenKey = LOGIN_USER_KEY + token;
//取出所有,get方法是取出一个字段
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(tokenKey);
// 3.判断用户是否存在
if (userMap.isEmpty()) {
// 4.不存在,拦截,返回401状态码
response.setStatus(401);
return false;
}
// 5.将查询到的Hash数据转换为UserDTO对象
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap,new UserDTO(),false);//最后一个参数为是否忽略转换中的错误
// 6.存在,保存用户信息到ThreadLocal
UserHolder.saveUser(userDTO);
// 7.刷新redis中token有效期
stringRedisTemplate.expire(tokenKey,LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 销毁user对象,防止内存泄露
UserHolder.removeUser();
}
}
5.Redis实现session的刷新问题
拦截器优化

此时拦截的只是需要拦截的路径,而不是所有,如果用户一直操作的都是非拦截路径,那么token不会刷新,30min后便会过期,登录状态消失。
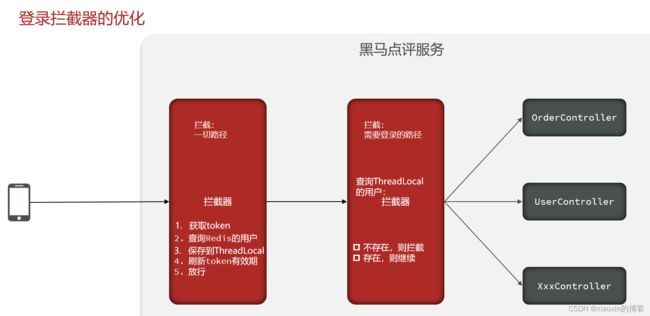
解决方案
在该拦截器前面再加一个拦截一切路径的拦截器,该拦截器只负责刷新token过期时间,不管token存不存在都放行。
若token存在且对应的用户存在才刷新token过期时间,并把对应的用户放入ThreadLocal中。然后再第二个拦截器里判断ThreadLocal中的用户是否存在,不存在则拦截,反之放行。
// 第一个拦截器
public class RefreshTokenInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1. 获取请求头中的token,判断token是否存在
String token = request.getHeader("authorization");
if (StrUtil.isEmpty(token)) {
//不用在拦截,直接放行
return true;
}
// 2.基于token获取redis中的用户
String tokenKey = LOGIN_USER_KEY + token;
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(tokenKey);
// 3.判断用户是否存在
if (userMap.isEmpty()) {
//不用在拦截,直接放行
return true;
}
// 5.将查询到的Hash数据转换为UserDTO对象
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap,new UserDTO(),false);
// 6.存在,保存用户信息到ThreadLocal
UserHolder.saveUser(userDTO);
// 7.刷新redis中token有效期
stringRedisTemplate.expire(tokenKey,LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 销毁user对象,防止内存泄露
UserHolder.removeUser();
}
}
// 第二个拦截器
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 判断是否需要拦截(通过ThreadLocal中是否有用户来判断)
if (UserHolder.getUser() == null) {
// 没有,需要拦截,设置状态码
response.setStatus(401);
// 拦截
return false;
}
// 有用户,放行
return true;
}
}
// 添加两个拦截器,并设置拦截器顺序
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 先后顺序由order属性值决定,默认都是0,可以修改order值,order越小优先级越高,order越大顺序越靠后
// 同时order值相同,就通过添加顺序来决定先后顺序。
// 登录拦截器
registry.addInterceptor(new LoginInterceptor())
.excludePathPatterns(
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
).order(1);
// 刷新token拦截器;默认拦截所有==.addPathPatterns("/**")
registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate)).order(0);
}
}
商家查询的缓存功能
1.✨认识缓存
-
什么是缓存?
- 缓存就是数据交换的缓冲区(称作Cache [ kæʃ ] ),是存贮数据的临时地方,一般读写性能较高
-
缓存的作用?
- 降低后端负载
- 提高服务读写响应速度
-
缓存的成本?
- 开发成本
- 运维成本
- 一致性问题
2.✨添加redis缓存
流程

店铺类型在首页和其它多个页面都会用到,如图:
后端代码
修改ShopTypeController中的queryTypeList方法,添加查询缓存
3.✨缓存更新策略
三种策略
-
内存淘汰
- Redis自带的内存淘汰机制
-
过期淘汰
- 利用expire命令给数据设置过期时间
-
主动更新
- 主动完成数据库与缓存的同时更新
策略选择
-
低一致性需求
- 内存淘汰或过期淘汰
-
高一致性需求
- 主动更新为主
- 过期淘汰兜底
主动更新的方案
Cache Aside⭐
-
缓存调用者在更新数据库的同时完成对完成的更新
- 一致性良好
- 实现难度一般
Read/Write Through⭐
-
缓存与数据库集成为一个服务,服务保证两者的一致性,对外暴露API接口。调用者调用API,无需知道自己操作的是数据库还是缓存,不关心一致性。
- 一致性优秀
- 实现复杂
- 性能一般
Write Back⭐
-
缓存调用者的CRUD都针对缓存完成。由独立线程异步的将缓存数据写到数据库,实现最终一致
- 一致性差
- 性能好
- 实现复杂
Cache Aside的模式选择
-
更新缓存还是删除缓存?
- 更新缓存会产生无效更新,并且存在较大的线程安全问题
- 删除缓存本质是延迟更新,没有无效更新,线程安全问题相对较低
-
先操作数据库还是缓存?
-
先更新数据,再删除缓存
- 在满足原子性的情况下,安全问题概率较低
-
先删除缓存,再更新数据库
- 安全问题概率较高
-
-
如何确保数据库与缓存操作原子性?
-
单体系统
- 利用事务机制
-
分布式系统
- 利用分布式事务机制
-
最佳实践
-
查询数据时
- 1.先查询缓存
- 2.如果缓存命中,直接返回
- 3.如果缓存未命中,则查询数据库
- 4.将数据库数据写入缓存
- 5.返回结果
-
修改数据库时
- 1.先修改数据库
- 2.然后删除缓存
- 确保两者的原子性
修改代码
①根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
②根据id修改店铺时,先修改数据库,再删除缓存
4.✨缓存穿透
产生原因
- 客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
解决方案
缓存空对象⭐
-
思路
- 对于不存在的数据也在Redis建立缓存,值为空,并设置一个较短的TTL时间
-
优点
- 实现简单,维护方便
-
缺点
- 额外的内存消耗
- 短期的数据不一致问题
布隆过滤⭐
-
思路
- 利用布隆过滤算法,在请求进入Redis之前先判断是否存在,如果不存在则直接拒绝请求
-
优点
- 内存占用少
-
缺点
- 实现复杂
- 存在误判的可能性
其它⭐
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
5.✨缓存雪崩
产生原因
- 在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
6.✨缓存击穿(热点Key)
产生原因
-
热点Key
- 在某一时段被高并发访问
- 缓存重建耗时较长
-
热点key突然过期,因为重建耗时长,在这段时间内大量请求落到数据库,带来巨大冲击
解决方案
互斥锁
-
思路
- 给缓存重建过程加锁,确保重建过程只有一个线程执行,其它线程等待
-
优点
- 实现简单
- 没有额外内存消耗
- 一致性好
-
缺点
- 等待导致性能下降
- 有死锁风险
逻辑过期
-
思路
- 热点key缓存永不过期,而是设置一个逻辑过期时间,查询到数据时通过对逻辑过期时间判断,来决定是否需要重建缓存
- 重建缓存也通过互斥锁保证单线程执行
- 重建缓存利用独立线程异步执行
- 其它线程无需等待,直接查询到的旧数据即可
-
优点
- 线程无需等待,性能较好
-
缺点
- 不保证一致性
- 有额外内存消耗
- 实现复杂
7.✨缓存工具封装
秒杀优惠券功能
1.✨秒杀优惠券的基本实现
2.✨超卖问题
3.✨基于乐观锁解决超卖问题
- 乐观锁和悲观锁
秒杀的一人一单限制功能
1.✨实现秒杀的一人一单限制
2.✨单机模式下的线程安全问题
3.✨集群模式下的线程安全问题
4.✨分布式锁
-
分布式锁原理
-
Redis的String结构实现分布式锁
-
锁误删问题
-
锁的原子性操作问题
-
Lua脚本解决原子性问题
- Lua语法
- redis的Lua脚本
- RedisTemplate调用Lua脚本
-
Redisson分布式锁
-
Hash结构解决锁的可重入问题
-
发布订阅结合信号量解决锁重试问题
-
watchDog解决锁超时释放问题