pandas 数学和统计方法&数据排序&分箱操作(7)
文章目录
- 前言
- 一、 简单统计指标
-
- 1.count方法
- 2.median() #中位数
- 3.分位数
- 4.其他
- 二、索引标签、位置获取(最大值、最小值)
- 三、 更多统计指标
- 四、高级统计指标
-
- 数据排序部分
- 五、数据排序
-
- 1.索引列名排序
- 2.属性值排序
- 3.返回属性n大或者n小的值
- 分箱操作
- 六、分箱操作
-
- 1、等宽分箱
- 2.指定宽度分箱
- 3、等频分箱
- 总结
前言
python学习笔记—pandas day8(仅供学习使用)
pandas对象拥有一组常用的数学和统计方法。它们属于汇总统计,对Series汇总计算获取mean、max值或者对DataFrame行、列汇总计算返回一个Series。
一、 简单统计指标
1.count方法
map、apply、transform都可以对某一列进行操作。
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,100,size = (20,3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns=['Python','Tensorflow','Keras'])
def convert(x):
if x > 80:
return np.NaN
else:
return x
df['Python'] = df['Python'].map(convert)
df['Tensorflow'] = df['Tensorflow'].apply(convert)
df['Keras'] = df['Keras'].transform(convert)
df
count方法:
df.count() # 统计非空数据的个数

2.median() #中位数
df.median() # 中位数

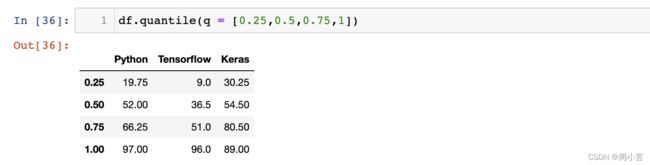
3.分位数
df.quantile(q = [0.25,0.5,0.75,1])
4.其他

二、索引标签、位置获取(最大值、最小值)
# 2、索引位置——返回值都是索引。
df['Tensorflow'].argmin() # 计算最小值位置,自然数0、1、2……
df['Keras'].argmax() # 最大值位置
df.idxmax() # 最大值索引标签=index强标记
# df.idxmin() # 最小值索引标签
三、 更多统计指标
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,5,size = (20,3)),
index = list('ABCDEFHIJKLMNOPQRSTU'),
columns=['Python','Tensorflow','Keras'])
df
df['Python'].value_counts() # 统计元素出现次数
df['Python'].unique() # 去重
df.cumsum() # 累加
df.cumprod() # 累乘
df.std() # 标准差
df.var() # 方差
df.cummin() # 累计最小值
df.cummax() # 累计最大值
df.diff() # 计算差分,和上一行,相减
df.pct_change() # 计算百分比变化
四、高级统计指标
# 4、高级统计指标
df.cov() # 属性的协方差
df['Python'].cov(df['Keras']) # Python和Keras的协方差
df.corr() # 所有属性相关性系数
df.corrwith(df['Tensorflow']) # 单一属性相关性系数

数据排序部分
五、数据排序
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,30,size = (30,3)),
index = list('qwertyuioijhgfcasdcvbnerfghjcf'),
columns = ['Python','Keras','Pytorch'])
1.索引列名排序
df.sort_index(axis = 0,ascending=True) # 按索引排序,降序
df.sort_index(axis = 1,ascending=False) #按列名排序,升序
2.属性值排序
df.sort_values(by = ['Python']) #按Python属性值排序
df.sort_values(by = ['Python','Keras'])#先按Python,再按Keras排序
3.返回属性n大或者n小的值
df.nlargest(10,columns='Keras') # 根据属性Keras排序,返回最大10个数据
df.nsmallest(5,columns='Python') # 根据属性Python排序,返回最小5个数据
分箱操作
六、分箱操作
分箱操作就是将连续数据转换为分类对应物的过程。比如将连续的身高数据划分为:矮中高。
分箱操作分为等距分箱和等频分箱。
分箱操作也叫面元划分或者离散化。
数据创建:
import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0,150,size = (100,3)),
columns=['Python','Tensorflow','Keras'])
df
1、等宽分箱
pd.cut(df.Python,bins = 3)

2.指定宽度分箱
# 指定宽度分箱
t = pd.cut(df.Keras,#分箱数据
bins = [0,60,90,120,150],#分箱断点
right = False,# 左闭右开
labels=['不及格','中等','良好','优秀'])# 分箱后分类
# t.value_counts()#统计各区域人数
t

相当于:
def convert(x):
if x < 60:
return '不及格'
elif x < 90:
return '中等'
elif x < 120:
return '良好'
else:
return '优秀'
df.Keras.map(convert)
以上两串代码 实现结果相同。
3、等频分箱
# 2、等频分箱
pd.qcut(df.Python,q = 4,# 4等分
labels=['差','中','良','优']).value_counts() # 分箱后分类

差良中优将近平均分配。