Nachos文件系统目录树实现
扩展Nachos的文件系统
实验任务
尝试多级目录(目录树)的设计与实现方法。
拓展(选做):目前Nachos文件系统仅仅实现了单级目录结构,只有一个根目录。可以尝试采用目录树对文件进行管理。
设计思路
整体思路
在数据结构课设中,实现过带父结点指针的兄弟链表所实现的目录树,但是阅读Nachos代码,发现目录节点是DirectoryEntry并且在一开始初始化目录的时候,是以数组的形式初始化的,这样就不好进行像链表那样的动态新建目录或者文件的操作,也没法像链表一样索引关联节点。但是可以使用模拟指针的思想,以下标作为索引值,来找到某个文件/目录的父目录、左孩子、以及兄弟结点,从而能够遍历整颗树。
按照上面的思路进行编程发现,不需要那么强的拓展功能,所以不采用兄弟链表作为数据结构了,而是采用带模拟指针的多叉树数据结构来实现目录树和多级目录,并且使用graphviz+dot 可视化目录树。
修改DirectoryEntry
首先修改DirectoryEntry,加入两个模拟指针以及孩子数的记录如下
class DirectoryEntry {
public:
bool inUse; // Is this directory entry in use?
int sector; // Location on disk to find the
// FileHeader for this file
char name[FileNameMaxLen + 1]; // Text name for file, with +1 for
// the trailing '\0'
int parent; // father dir 's index
int Child_Num; // dir's child num
int children[MaxDirChildNUm]; // dir's children
// bool filetype; // 0文件 1目录
};
Directory 的构造函数
在Directory 的构造函数中,设置0目录项是根目录Root,初始化的相关信息。他的父节点为-1,即没有,且children全为-1,即未分配。
Directory::Directory(int size)
{
table = new DirectoryEntry[size];
tableSize = size;
for (int i = 0; i < tableSize; i++){
table[i].inUse = FALSE;
// update
table[i].Child_Num = 0;
table[i].parent = 0;
for(int j = 0; j < MaxDirChildNUm; j ++){
table[i].children[j] = -1;
}
}
// set table[0] as root
table[0].parent = -1;
table[0].inUse = TRUE;
}
Directory::Add
阅读代码发现,在目录中,真正在cp命令时发挥作用的是FindIndex 以及 Add函数,首先修改Add函数
思路:
-
看文件是否存在
-
分割路径(因为可能是多级目录路径)
-
找到要添加的节点的父节点
-
加入新节点并且更新新节点信息
-
更新父节点信息
代码
bool
Directory::Add(char *name, int newSector)
{
// My Code
// 1. Judge whether file is alread exists
if (FindIndex(name) != -1)
return FALSE;
// 2. Split the path
string copy_name = name;
// Split it from the last file
// For example: dir1/dir2/dir3/file cut into:
int cutpos = -1;
// Seek Cut Position
for(int i=0;i 0){
// Limit 100 level
char cstrParentName[1000];
strcpy(cstrParentName , ParentDir.c_str());
ParentDirId = FindIndex(cstrParentName);
}
// 4. Add new node in DirTable, and add info into Table Tree
for(int i=1;i 修改FindIndex
修改FindIndex函数使其能够正确根据多级路径查找目录表项
思路
-
检查是否DISK初始化(即存在根目录)
-
分割路径
-
找到根目录下第一级目录
-
从上到下进行扫描,匹配路径名称直到找到最后一个文件/目录
代码
int
Directory::FindIndex(char *name)
{
// origin code
/*
for (int i = 0; i < tableSize; i++)
if (table[i].inUse && !strncmp(table[i].name, name, FileNameMaxLen))
return i;
return -1; // name not in directory
*/
// My updated code
// List();
// 1. Check whether there is dir or file from root
if(table[0].Child_Num <= 0){
printf("No dir or file from root\n");
return -1;
}
// 2. Split the multi path
vector PathTable = SplitPath(name);
// 3. Find the first root dir ForExample : dir1/dir2/dir3/txt
// We need to find dir1 firstly
// to scan
string scandir = PathTable[0];
// index of the first dir
int firstDirIndex = -1;
for(int i = 0; i < table[0].Child_Num; i ++){
int index = table[0].children[i];
// judge inuse
if(!table[index].inUse)
continue;
// judge Name Equal
bool issame = JudgeNameEqual(scandir,index,table);
if(issame){
firstDirIndex = index;
break;
}
}
// check valid
if(firstDirIndex == -1)
return -1;
// 4. From up to bottom scan the Tree and match
// To find final parent dir
// maybe just one dir
if(PathTable.size() == 1)
return firstDirIndex;
// multi dir
// and parent Id is the parent of target file (which means target dir)
int parentId = firstDirIndex;
// scan multi dir to match name
for(int i = 1; i < PathTable.size(); i ++){
// find flag
bool isfind = FALSE;
// scan this level's child to match
for(int j = 0; j < table[parentId].Child_Num; j++){
// In this level, current scan ID
int currentId = table[parentId].children[j];
// check inuse
if(!table[currentId].inUse)
continue;
// check name
bool issame = JudgeNameEqual(PathTable[i],currentId,table);
if(issame){
// we find the next dir
isfind = true;
// record the last dir in parentId
parentId = currentId;
break;
}
}
// Find Failed
if(!isfind)
return -1;
}
printf("Successfully Find: %s",parentId);
// return the parent Dir
return parentId;
}
List
为了展示目录树,修改List代码
思路
从table[0] 即根目录开始向下遍历,迭代输出所有文件和目录的名称
代码
void
Directory::List()
{
// My codes:
// List all the file names in dir
printf("Directory Contents:\n");
printf("/root\n");
// from the root
for(int i=1;i PathTable;
int index = i;
// find the parents
while(table[index].parent != -1){
string tmp = table[index].name;
PathTable.push_back(tmp);
index = table[index].parent;
}
// cout the path
printf("/root");
for(int j = PathTable.size() - 1; j >= 0; j --){
printf( "/");
cout << PathTable[j];
}
printf("\n");
}
}
}
修改Print函数 使-D 指令能够正常执行
思路
- 从上到下进行层次遍历,名字记录在vector里,然后输出
代码
void
Directory::Print()
{
// My Codes
FileHeader *hdr = new FileHeader;
printf("Directory contents:\n");
for (int i = 0; i < tableSize; i++){
if (table[i].inUse) {
vector PathTable;
int index = i;
// not to root
while(table[index].parent != -1){
string temp = table[index].name;
PathTable.push_back(temp);
index = table[index].parent;
}
printf("Name: /root");
// the next path
for(int j=PathTable.size()-1;j>=0;j--){
printf("/");
cout<FetchFrom(table[i].sector);
hdr->Print();
}
}
printf("\n");
delete hdr;
}
Remove
重写Remove函数,使其能够正常删除多级目录,并且能够递归删除含有文件或者目录的目录
思路
- 根据多级目录 找到该文件
- 修改目录表项的InUse信息
- 更新有关父节点的信息
- 如果删除的是目录,递归删除该目录所有内容
代码
bool
Directory::Remove(char *name)
{
// MY codes:
int i = FindIndex(name);
// name not in directory
if (i == -1)
return FALSE;
// clean dir table set false
table[i].inUse = FALSE;
// Update parent
int parentId = table[i].parent;
// Until Roor
if(parentId != -1){
// record other child except I
vector tempChild;
for(int j=0;j 递归删除子目录或者子文件DeteleChildren
//---------------------------------------------------------------------
// Directory::DeteleChildren
//
// "name" -- the file name to be removed
//----------------------------------------------------------------------
void
Directory::DeteleChildren(int i){
for(int j = 0; j < table[i].Child_Num; j ++){
int index = table[i].children[j];
if(table[index].inUse){
table[index].inUse = FALSE;
table[index].Child_Num = 0;
DeteleChildren(index);
}
}
}
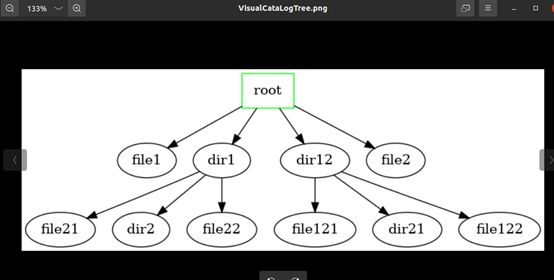
可视化
(1) 增加 -V 参数 代表visualize Catalog Tree
(2) 在filesys 添加相应成员函数
![]()
以及
//---------------------------------------------------------------------
// FileSystem::VisualTree
// Visual CataLog TRee
//---------------------------------------------------------------------
void
FileSystem::VisualTree()
{
Directory *directory = new Directory(NumDirEntries);
directory->FetchFrom(directoryFile);
directory->VisualCataLogTree();
delete directory;
}
(3) 在目录类中加入可视化函数:
思路
- 使用graphviz + dot 作图
- ofstream写出到文件dot代码
- 通过层次遍历添加dot代码
- 系统执行进行作图
代码
//--------------------------------------------------------------------
// Directory::VisualCataLogTree
// VisualCataLogTree
//--------------------------------------------------------------------
void Directory::VisualCataLogTree(){
ofstream fout;
fout.open("VisualCataLogTree.dot");
fout<<"strict digraph s{\n";
fout<<"root[shape=record,color=green];\n";
for(int i=0;i PathTable;
while(table[index].parent != -1){
string s = table[index].name;
PathTable.push_back(s);
index = table[index].parent;
}
PathTable.push_back("root");
for(int j=PathTable.size()-1;j>=1;j--)
fout< "< 完成!
测试CataLogTree
修改宏定义
在directory.h
#define MaxDirChildNUm 20 // the number of child that a dir can have
使得最多有20个孩子
在filesys.cc中
#define NumDirEntries 20
使得目录表可以有20项,最多20个文件+目录
测试cp命令
执行如下代码
rm DISK
./nachos -f
./nachos -cp test/small /file1
./nachos -cp test/empty /dir1
./nachos -cp test/empty /dir12
./nachos -cp test/medium /file2
./nachos -cp test/medium /dir1/file21
./nachos -cp test/empty /dir1/dir2
./nachos -cp test/small /dir1/file22
./nachos -cp test/small /dir12/file121
./nachos -cp test/empty /dir12/dir21
./nachos -cp test/small /dir12/file122
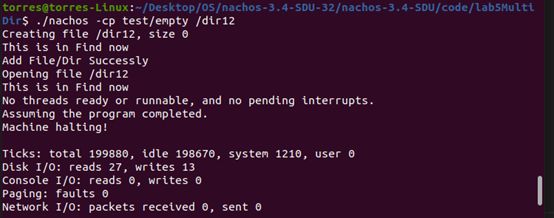
测试-l命令
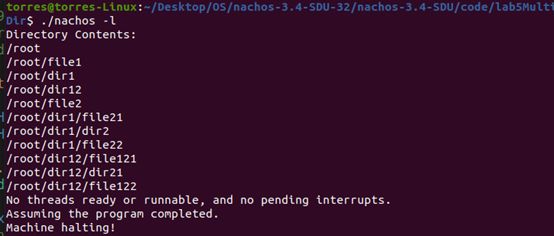
测试-V命令
输出图片
测试-r命令
./nachos -r /dir12
./nachos -r /file2
./nachos -V

结论体会
-
在目录树的设计中,使用了m叉树,首先肯定是把这个数据结构应用到目录表上的,但是同时不仅仅需要修改目录表类的函数,很多其他函数也会修改,体现了操作系统紧密连接的
-
实现目录表时,用了一些STL等工具,会方便很多,但是也出现了gcc版本不一致导致的错误,即在untils.h 和 sysdep.cc 里面定义了一些c++的工具时基于C++98和C++11差距较大,会报错,其中一种解决方案是把他们注释掉使用stdlib.h 库
-
使用多叉树复杂度大致为 O ( l o g m ( n ) ) O(log_m(n)) O(logm(n)),比单单一个线性表的目录表的查找更加高效,真实的操作系统应该需要这种高效。