Pytorch的一个强化的学习教程( Train a Mario-playing RL Agent)使用超级玛丽游戏来学习双Q网络(强化学习的一种类型),官网的文章只有代码, 所以本文将配合官网网站的教程详细介绍它是如何工作的,以及如何将它们应用到这个例子中。
强化学习是如何起作用的
机器学习可以分为三类:监督学习、非监督学习和强化学习。
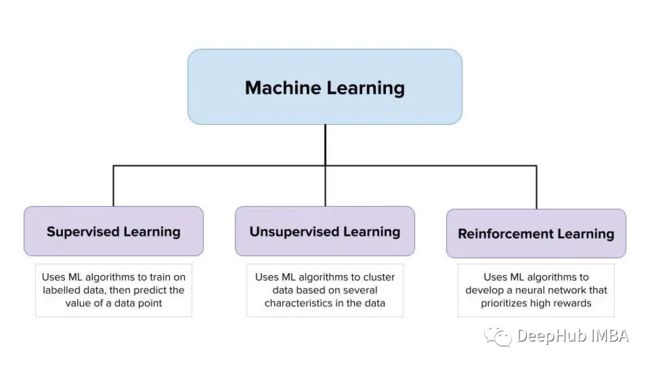
在监督学习中,模型被赋予一个训练数据集,该数据集包含输入和输出(标签)。它从这些数据中学习,了解如何从输入中获得输出。训练完成后使用测试数据集(包含模型从未见过的输入),模型必须尝试预测每个数据点应该被赋予的标签。
在无监督学习中,模型被赋予一个数据集,但数据点都没有标签。它被提供数据点和一些簇来将它们分组。随着簇数量的变化,算法的输出也随之变化。这种类型的学习用于发现给定数据中的模式。
强化学习与其他两种训练方法不同:
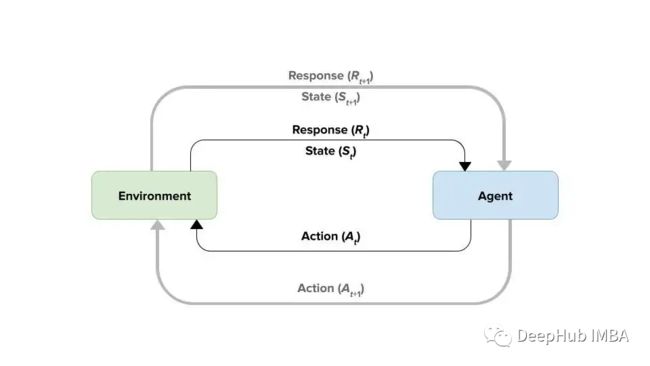
上图t表示被处理的步骤(或时间)。在一个步骤中,环境为代理的行为以及当前状态提供响应(奖励或惩罚)。有了这些信息,代理就可以确定要采取的行动。
它的训练是不受监督的,但它不是试图将数据点分组,而是试图通过在环境中执行有利的行为来获得奖励,同时试图避免犯惩罚它的错误(R_t)。
当涉及到强化学习时,理解以下术语很重要:
Agent: Agent是一种神经网络,它通过与环境的相互作用进行学习,并了解哪些行为会导致好的结果和坏的结果,我们将它称为代理,也有叫他为智能体的,但是我觉得代理更加合适,因为它相当于是我们玩游戏的代理人。
Environment:环境是代理在其中进行交互和学习的世界
Action:动作是指行为主体在特定的环境(状态)下决定要做的事情
State:状态是对给定时刻环境中的内容的捕获
Response:响应是当一个代理做了对其下一个状态有益或有害的事情时给予它的东西
深度Q学习与双深度Q网络(DDQNs)
深度Q学习是一种使用深度神经网络的强化学习。它使用Q值(状态的质量),确定其行为对环境状态是有益的还是有害的,来进行学习
深度Q网络(DQN)是一种多层神经网络,对于给定的状态,它根据网络的权重和偏差输出一个动作值向量。对于n维状态空间和包含m个动作的动作空间,神经网络是一个从R^n到R^m的函数。
Q学习(Q-learning)算法在某些条件下会高估动作值,这可能会影响它们的性能。而双深度Q学习是对DQN算法的一种特殊改变,它不仅减少了算法的过高估计,还提高了算法的性能。双Q学习的思想是通过将目标中的最大操作分解为行动的选择和行动的评估来减少过高估计。
深入理解深度Q学习和双深度Q网络(DDQNs)涉及复杂的数学。我们这里不详细介绍,如果有兴趣想详细了解请看这篇论文(https://arxiv.org/pdf/1509.06...)
MarioNet
下面我们进入正题“Train A Mario-Playing RL Agent”的教程详解,非常感谢Yuanson Feng, Suraj Subramanian, Howard Wang和Steven Guo制作了这个教程。
背景知识
在训练玩马里奥的背景下:
- 我们的代理是马里奥。
- 游戏环境就是马里奥的世界——它包含敌人、障碍和道具,如管子、蘑菇等。
- 行动就是马里奥执行的动作
- 动作空间是马里奥可以执行的所有可能的动作:向右跑,向右跳,向左跑,向左跳。在这种情况下,我将马里奥限制在右侧移动,以便进行更快的训练。
- 状态包括以下几项内容:马里奥的位置、障碍、升级道具和敌人的位置、马里奥的当前分数(不重要)以及所有物体的前进方向。
- 状态空间是环境中所有可能状态的集合。
- 奖励是环境对代理的反馈,这将推动马里奥学习并改变自己未来的行动。
- 回报是经过多次游戏或章节的累积奖励。
- 状态中行为的质量是给定状态和行为的预期回报。
环境预处理
在我们开始训练神经网络之前,我们可以优化环境,这样训练的计算量就不会那么大。
灰度化:环境的大小是一个3x240x256的窗口,其中3表示RGB通道,240x256表示窗口的尺寸。状态中每个对象的颜色并不会真正影响代理的最终行动,例如马里奥穿红色衣服或砖块是棕色并不会改变代理的行动。所以我们可以将整个图像转换为灰度图,而不是处理一个计算量很大的3x240x256窗口,这样我们可以使用1x240x256的灰度图。
调整大小:对于计算机来说,以每秒15帧的速度处理一个240 × 256像素的窗口可能不是最简单的(稍后会详细介绍)。所以我们可以调整代理接收的图像的大小,比如缩小到到84像素乘84像素。
跳帧:我们的代理处理每一帧并不会增加多少价值,因为通过查看连续的帧,代理不会获得太多信息,因为连续的帧包含非常相似的状态。所以我们可以跳过给定数量的中间帧而不会丢失太多信息。
叠加帧:帧叠加用于将连续的帧合并为一个统一的学习模型输入。使用这种方法,可以通过查看给定的帧,更容易地识别之前发生的动作。
所以我们堆叠四个连续的,灰度化的,调整大小的帧,这样得到了一个4x84x84的大小的输入。
定义代理
马里奥(我们的代理)需要能够行动、记忆和学习。
动作:代理的行为基于环境的当前状态和最优的行为策略。在每个状态下,马里奥要么执行一个动作(探索),要么使用他的神经网络(MarioNet)为他提供的一个最佳执行动作(利用)。马里奥根据自己的探索速度决定是否进行探索或利用。
在训练开始时,探索率被设置为1,这意味着马里奥肯定会做一个随机的动作。然后,随着每个堆叠帧的流逝,探索速率会随着一个叫做探索速率衰减的数字而减少,这将引导马里奥使用神经网络而不是随机行动进行探索。
记忆(缓存和回忆):马里奥根据当前状态、奖励和下一个状态来记住自己以前的动作。对于每个动作,马里奥都会缓存他的经验(将它们存储在内存中)。然后,他从记忆缓存中回忆(随机抽取一批体验),并使用它来学习如何更好地玩游戏。
学习:随着时间的推移,马里奥需要能够使用自己的经验去完善自己的行动(或行动策略)。为了完成这项任务,我们使用DDQN算法。在这种情况下,DDQN使用两个近似最优动作值函数的卷积神经网络。采用时间差分法(TD)计算TD_estimate和 TD_target,并计算损失来优化神经网络参数。
运行MarioNet
我查看官方教程的代码,了解它是如何工作的。代码注释得非常好。它可以让我们了解双Q学习中的所有数学概念是如何转化为代码的。
运行网络并观察网络是如何工作的非常有趣。我们这里不对这个模型进行完整的训练步骤,因为这需要4万轮次。我花了大约9分钟在笔记本电脑上看完100轮。按照这个速度,需要60-70个小时才能够训练万4万的轮次。
下面列出了一些在整个训练过程中生成的输出图表和日志。通过观察这张图,我可以观察到神经网络是如何逐步学习的。注意在前几轮中,马里奥的行动是完全随机的。直到第40轮(图表中的第8轮)左右,马里奥才开始利用他的神经网络。
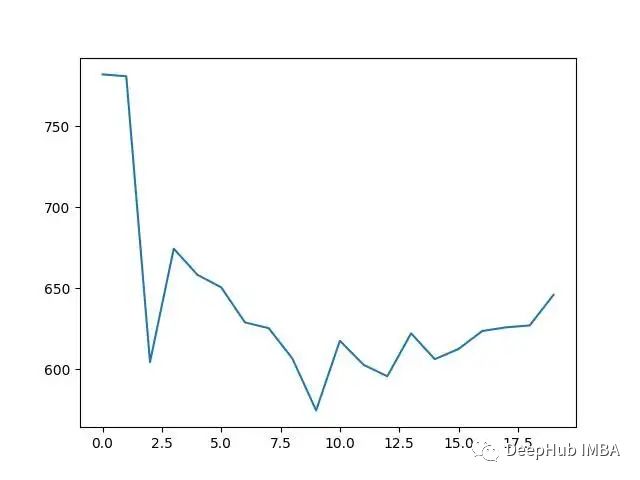
x轴上的值乘以5是论次数。y轴是这5轮的平均奖励。

每五轮训练的平均时常。y轴表示每一轮的时间。
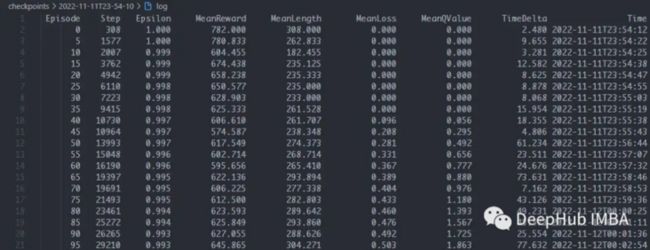
上图是5轮的操作数,探索率,平均奖励,长度,损失和Q值,花在这5轮上的时间,以及完成这5轮的时间。
看看训练一轮是什么样子的:
注意事项
加载和保存模型
在对该程序进行试验时,每次运行该应用程序时都是从头开始的,并没有保存神经网络的最后一个训练状态。因此需要找到一种通过多次运行来训练网络的方法,这样我就不必让计算机的CPU超负荷60个小时。在PyTorch中有多种方法可以保存和加载模型。虽然在代码中正确地实现了保存,但我发现在程序开始时并没有真正加载之前保存的神经网络状态。
这导致我们每次训练都是从头开始的。所以我们需要修改代码:
在程序结束时,保存神经网络的状态、epsilon(探索率)值和轮次。在程序开始时,加载先前保存的神经网络状态、epsilon值和轮次,这样训练就可以从以前的点恢复训练。
cpu和gpu
使用CPU的训练很慢,但我尝试使用GPU训练时,它就会耗尽内存(因为笔记本显卡的显存不大)。GPU内存耗尽的原因是,它一直在填充缓存,直到缓存满了,但在训练过程中从未清空任何数据。这是一个需要研究的问题。
总结
非常感谢Yuanson Feng, Suraj Subramanian, Howard Wang和Steven Guo,他们制作了这个简单的教程,通过这个教程可以学习很多多关于强化学习的知识,包括使用PyTorch和OpenAI Gym(提供了这些很棒的环境来训练我的神经网络)这是一个学习并创建自己的强化学习应用程序非常好的开始。
官网教程在这里,有兴趣的可以自行查看:
https://avoid.overfit.cn/post/a625743c337e48a6839ffe2121f90369
作者:Sohum Padhye