用 Keras 创建自己的图像标题生成器
总览
了解图像字幕生成器如何使用编码器-解码器工作
知道如何使用Keras创建自己的图像标题生成器
介绍
图像标题生成器是人工智能的热门研究领域,涉及图像理解和该图像的语言描述。生成格式正确的句子需要对语言的句法和语义理解。能够使用准确形成的句子描述图像的内容是一项非常具有挑战性的任务,但是通过帮助视障人士更好地理解图像的内容,它也会产生巨大的影响。
与已进行充分研究的图像分类或对象识别任务相比,此任务要困难得多。
最大的挑战是绝对能够创建一个描述,该描述不仅必须捕获图像中包含的对象,而且还必须表达这些对象之间的相互关系。
考虑以下来自Flickr8k数据集的图像:

您在上图中看到了什么?
您可以轻松地说出“雪中的黑狗和棕狗”或“雪中的小狗玩耍”或“雪中的两只波美拉尼亚狗”。作为人类,对于我们来说看这样的图像并适当地描述它似乎很容易。
让我们看看如何从头开始创建图片说明生成器,该生成器可以为上述图片以及更多图片提供有意义的描述!
开始之前的先决条件:
1、Python编程
2、Keras及其模块
3、卷积神经网络及其实现
4、RNN和LSTM
5、转移学习
问题陈述的处理
我们将使用编码器-解码器模型解决此问题。在这里,我们的编码器模型将图像的编码形式和文本标题的编码形式结合在一起,并馈送到解码器。我们的模型会将CNN视为“图像模型”,将RNN / LSTM视为“语言模型”,以对不同长度的文本序列进行编码。然后,将两种编码所产生的向量合并并由密集层进行处理,以进行最终预测。我们将创建一个合并体系结构,以使图像不属于RNN / LSTM,从而能够使用来自单独训练集中的图像和语句来训练处理图像的神经网络部分和分别处理语言的部分。
在我们的合并模型中,可以在每次预测之前将图像的不同表示形式与最终RNN状态进行组合。
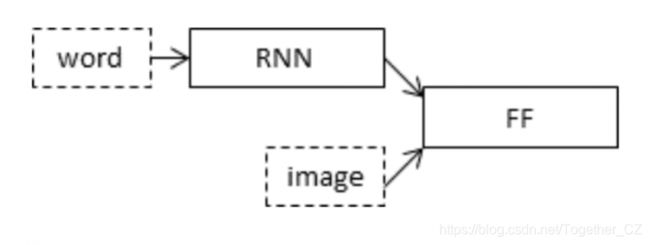
将图像特征与文本编码合并到体系结构中的下一个阶段是有利的,并且与传统注入体系结构(CNN作为编码器和RNN作为解码器)相比,可以用较小的层生成更好的字幕。
为了对图像特征进行编码,我们将使用转移学习。我们可以使用很多模型,例如VGG-16,InceptionV3,ResNet等。我们将使用inceptionV3模型,该模型具有比其他参数最少的训练参数,并且性能也比其他参数好。为了对文本序列进行编码,我们将每个单词映射到200维向量。为此,将使用预训练的手套模型。此映射将在称为嵌入层的输入层之后的单独层中完成。为了生成字幕,我们将使用两种流行的方法,即“贪婪搜索”和“波束搜索”。这些方法将帮助我们选择最佳单词来准确定义图像。我希望这使您对我们如何处理此问题陈述有所了解。
让我们深入研究图像标题生成器的实现和创建!
了解数据集
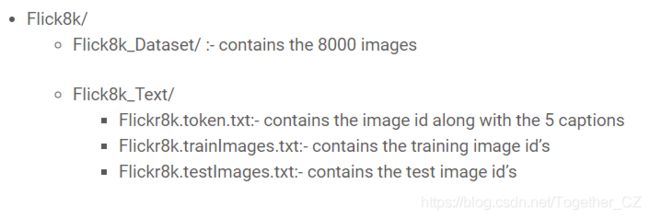
许多数据集用于图像字幕方法的训练,测试和评估。数据集在各种角度上都不同,例如图像数量,每个图像的字幕数量,字幕格式和图像大小。三个数据集:Flickr8k,Flickr30k和MS COCO数据集被广泛使用。在Flickr8k数据集中,每个图像都与五个不同的标题相关联,这些标题描述了图像中所描述的实体和事件。通过将每个图像与多个独立产生的句子相关联,数据集捕获了一些可用于描述同一图像的语言多样性。
Flickr8k体积小巧,可以使用CPU在低端笔记本电脑/台式机上轻松进行培训,因此是一个很好的入门数据集。我们的数据集结构如下:
让我们来构建图片说明生成器!
步骤1:导入所需的库
在这里,我们将利用Keras库创建模型并进行训练。如果您想要GPU进行训练,则可以使用Google Colab或Kaggle笔记本。
import numpy as np
from numpy import array
import matplotlib.pyplot as plt
%matplotlib inline
import string
import os
import glob
from PIL import Image
from time import time
from keras import Input, layers
from keras import optimizers
from keras.optimizers import Adam
from keras.preprocessing import sequence
from keras.preprocessing import image
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.layers import LSTM, Embedding, Dense, Activation, Flatten, Reshape, Dropout
from keras.layers.wrappers import Bidirectional
from keras.layers.merge import add
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.models import Model
from keras.utils import to_categorical
步骤2:数据加载和预处理
我们将定义所需文件的所有路径,并保存图像id及其标题。
token_path = "../input/flickr8k/Data/Flickr8k_text/Flickr8k.token.txt"
train_images_path = '../input/flickr8k/Data/Flickr8k_text/Flickr_8k.trainImages.txt'
test_images_path = '../input/flickr8k/Data/Flickr8k_text/Flickr_8k.testImages.txt'
images_path = '../input/flickr8k/Data/Flicker8k_Dataset/'
glove_path = '../input/glove6b'
doc = open(token_path,'r').read()
print(doc[:410])
输出如下:

因此,我们可以看到存储图片ID及其标题的格式。接下来,我们创建一个名为“descriptions”的字典,其中包含图像的名称作为键,并包含对应图像的5个标题的列表作为值。
descriptions = dict()
for line in doc.split('\n'):
tokens = line.split()
if len(line) > 2:
image_id = tokens[0].split('.')[0]
image_desc = ' '.join(tokens[1:])
if image_id not in descriptions:
descriptions[image_id] = list()
descriptions[image_id].append(image_desc)
现在,让我们执行一些基本的文本清除操作以消除标点符号,并将我们的描述转换为小写。
table = str.maketrans('', '', string.punctuation)
for key, desc_list in descriptions.items():
for i in range(len(desc_list)):
desc = desc_list[i]
desc = desc.split()
desc = [word.lower() for word in desc]
desc = [w.translate(table) for w in desc]
desc_list[i] = ' '.join(desc)
让我们可视化示例图片及其标题:
pic = '1000268201_693b08cb0e.jpg'
x=plt.imread(images_path+pic)
plt.imshow(x)
plt.show()
descriptions['1000268201_693b08cb0e']
输出如下:

接下来,我们创建数据集中所有8000 * 5(即40000)图像标题中存在的所有唯一单词的词汇表。我们在所有40000个图像标题中都有8828个唯一的单词。
vocabulary = set()
for key in descriptions.keys():
[vocabulary.update(d.split()) for d in descriptions[key]]
print('Original Vocabulary Size: %d' % len(vocabulary))
输出如下:
![]()
现在,以与token.txt文件相同的格式保存图像ID及其新清除的标题:
lines = list()
for key, desc_list in descriptions.items():
for desc in desc_list:
lines.append(key + ' ' + desc)
new_descriptions = '\n'.join(lines)
接下来,我们从“Flickr_8k.trainImages.txt”文件的可变火车中加载所有6000个训练图像ID:
doc = open(train_images_path,'r').read()
dataset = list()
for line in doc.split('\n'):
if len(line) > 1:
identifier = line.split('.')[0]
dataset.append(identifier)
train = set(dataset)
现在,我们将所有训练和测试图像分别保存在train_img和test_img列表中:
img = glob.glob(images_path + '*.jpg')
train_images = set(open(train_images_path, 'r').read().strip().split('\n'))
train_img = []
for i in img:
if i[len(images_path):] in train_images:
train_img.append(i)
test_images = set(open(test_images_path, 'r').read().strip().split('\n'))
test_img = []
for i in img:
if i[len(images_path):] in test_images:
test_img.append(i)
现在,我们将训练图像的描述加载到字典中。但是,我们将在每个标题中添加两个标记,分别是“ startseq”和“ endseq”:
train_descriptions = dict()
for line in new_descriptions.split('\n'):
tokens = line.split()
image_id, image_desc = tokens[0], tokens[1:]
if image_id in train:
if image_id not in train_descriptions:
train_descriptions[image_id] = list()
desc = 'startseq ' + ' '.join(image_desc) + ' endseq'
train_descriptions[image_id].append(desc)
创建所有训练标题的列表:
all_train_captions = []
for key, val in train_descriptions.items():
for cap in val:
all_train_captions.append(cap)
为了使我们的模型更加健壮,我们将词汇量减少到仅在整个语料库中出现至少10次的单词。
word_count_threshold = 10
word_counts = {}
nsents = 0
for sent in all_train_captions:
nsents += 1
for w in sent.split(' '):
word_counts[w] = word_counts.get(w, 0) + 1
vocab = [w for w in word_counts if word_counts[w] >= word_count_threshold]
print('Vocabulary = %d' % (len(vocab)))
输出如下:

现在,我们创建两个字典以将单词映射到索引,反之亦然。另外,我们在词汇表后面加上1,因为我们在后面加上0以使所有字幕的长度相等。
ixtoword = {}
wordtoix = {}
ix = 1
for w in vocab:
wordtoix[w] = ix
ixtoword[ix] = w
ix += 1
vocab_size = len(ixtoword) + 1
因此,现在我们的总词汇量为1660。我们还需要找出字幕的最大长度,因为我们不能有任意长度的字幕。
all_desc = list()
for key in train_descriptions.keys():
[all_desc.append(d) for d in train_descriptions[key]]
lines = all_desc
max_length = max(len(d.split()) for d in lines)
print('Description Length: %d' % max_length)
输出如下:
![]()
步骤3:Glove嵌入
词向量将词映射到向量空间,在这里类似的词被聚在一起,而不同的词则被分离。与Word2Vec相比,使用Glove的优势在于GloVe不仅依赖于单词的局部上下文,还合并了全局单词共现以获得单词向量。
Glove背后的基本前提是我们可以从同现矩阵中得出单词之间的语义关系。对于我们的模型,我们将使用Glove将38字长标题中的所有字映射到200维向量。
embeddings_index = {}
f = open(os.path.join(glove_path, 'glove.6B.200d.txt'), encoding="utf-8")
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
接下来,我们制作形状矩阵(1660,200),该矩阵由我们的词汇表和200维向量组成。
embedding_dim = 200
embedding_matrix = np.zeros((vocab_size, embedding_dim))
for word, i in wordtoix.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
步骤4:模型建立与培训
正如您从我们的方法中看到的那样,我们选择了使用InceptionV3网络进行转移学习,该网络在ImageNet数据集上进行了预训练。
model = InceptionV3(weights='imagenet')
我们必须记住,这里不需要分类图像,只需要为图像提取图像矢量即可。因此,我们从inceptionV3模型中删除了softmax层。
model_new = Model(model.input, model.layers[-2].output)
由于我们使用的是InceptionV3,因此我们需要对输入进行预处理,然后再将其输入模型。因此,我们定义了一个预处理函数以将图像重塑为(299 x 299)并馈入Keras的preprocess_input()函数。
def preprocess(image_path):
img = image.load_img(image_path, target_size=(299, 299))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return x
现在我们可以继续对训练和测试图像进行编码,即提取形状为(2048,)的图像矢量。
def encode(image):
image = preprocess(image)
fea_vec = model_new.predict(image)
fea_vec = np.reshape(fea_vec, fea_vec.shape[1])
return fea_vec
encoding_train = {}
for img in train_img:
encoding_train[img[len(images_path):]] = encode(img)
train_features = encoding_train
encoding_test = {}
for img in test_img:
encoding_test[img[len(images_path):]] = encode(img)
现在定义模型,我们正在创建一个合并模型,其中我们将图像矢量和部分标题结合在一起。因此,我们的模型将包含3个主要步骤:
1、处理文本中的序列
2、从图像中提取特征向量
3、通过连接以上两层,使用softmax解码输出
inputs1 = Input(shape=(2048,))
fe1 = Dropout(0.5)(inputs1)
fe2 = Dense(256, activation='relu')(fe1)
inputs2 = Input(shape=(max_length,))
se1 = Embedding(vocab_size, embedding_dim, mask_zero=True)(inputs2)
se2 = Dropout(0.5)(se1)
se3 = LSTM(256)(se2)
decoder1 = add([fe2, se3])
decoder2 = Dense(256, activation='relu')(decoder1)
outputs = Dense(vocab_size, activation='softmax')(decoder2)
model = Model(inputs=[inputs1, inputs2], outputs=outputs)
model.summary()
输出如下:

Input_3是输入到嵌入层的最大长度为34的部分标题。这是单词映射到200-d手套嵌入的地方。紧随其后的是0.5的落差,以避免过度拟合。然后将其输入LSTM中以处理序列。
Input_2是我们的InceptionV3网络提取的图像矢量。紧随其后的是0.5的落差,以避免过度拟合,然后将其馈入“全连接”层。
然后,通过添加图像模型和语言模型将其连接起来,并馈入另一个“完全连接”层。该层是softmax层,可为我们的1660个单词词汇提供概率。
步骤5:模型训练
在训练模型之前,我们需要记住,我们不想在嵌入层(预训练的Glove向量)中重新训练权重。
model.layers[2].set_weights([embedding_matrix])
model.layers[2].trainable = False
接下来,使用Categorical_Crossentropy作为Loss函数并使用Adam作为优化器来编译模型。
model.compile(loss='categorical_crossentropy', optimizer='adam')
由于我们的数据集有6000张图像和40000个标题,我们将创建一个可以批量训练数据的函数。
def data_generator(descriptions, photos, wordtoix, max_length, num_photos_per_batch):
X1, X2, y = list(), list(), list()
n=0
# loop for ever over images
while 1:
for key, desc_list in descriptions.items():
n+=1
# retrieve the photo feature
photo = photos[key+'.jpg']
for desc in desc_list:
# encode the sequence
seq = [wordtoix[word] for word in desc.split(' ') if word in wordtoix]
# split one sequence into multiple X, y pairs
for i in range(1, len(seq)):
# split into input and output pair
in_seq, out_seq = seq[:i], seq[i]
# pad input sequence
in_seq = pad_sequences([in_seq], maxlen=max_length)[0]
# encode output sequence
out_seq = to_categorical([out_seq], num_classes=vocab_size)[0]
# store
X1.append(photo)
X2.append(in_seq)
y.append(out_seq)
if n==num_photos_per_batch:
yield ([array(X1), array(X2)], array(y))
X1, X2, y = list(), list(), list()
n=0
接下来,让我们训练30个时期的模型,批处理大小为3,每个时期2000步。在Kaggle GPU上,模型的完整训练耗时1小时40分钟。
epochs = 30
batch_size = 3
steps = len(train_descriptions)//batch_size
generator = data_generator(train_descriptions, train_features, wordtoix, max_length, batch_size)
model.fit(generator, epochs=epochs, steps_per_epoch=steps, verbose=1)
步骤6:贪心搜索
当模型生成一个1660长的矢量时,该矢量在词汇表中所有单词的概率分布上,我们会贪婪地选择具有最高概率的单词以进行下一个单词预测。此方法称为贪心搜索。
def greedySearch(photo):
in_text = 'startseq'
for i in range(max_length):
sequence = [wordtoix[w] for w in in_text.split() if w in wordtoix]
sequence = pad_sequences([sequence], maxlen=max_length)
yhat = model.predict([photo,sequence], verbose=0)
yhat = np.argmax(yhat)
word = ixtoword[yhat]
in_text += ' ' + word
if word == 'endseq':
break
final = in_text.split()
final = final[1:-1]
final = ' '.join(final)
return final
Beam Search是我们获取前k个预测的地方,将其再次输入模型中,然后使用模型返回的概率对其进行排序。因此,列表将始终包含前k个预测,并且我们选择概率最高的预测,直到遇到“ endseq”或达到最大字幕长度为止。
def beam_search_predictions(image, beam_index = 3):
start = [wordtoix["startseq"]]
start_word = [[start, 0.0]]
while len(start_word[0][0]) < max_length:
temp = []
for s in start_word:
par_caps = sequence.pad_sequences([s[0]], maxlen=max_length, padding='post')
preds = model.predict([image,par_caps], verbose=0)
word_preds = np.argsort(preds[0])[-beam_index:]
# Getting the top (n) predictions and creating a
# new list so as to put them via the model again
for w in word_preds:
next_cap, prob = s[0][:], s[1]
next_cap.append(w)
prob += preds[0][w]
temp.append([next_cap, prob])
start_word = temp
# Sorting according to the probabilities
start_word = sorted(start_word, reverse=False, key=lambda l: l[1])
# Getting the top words
start_word = start_word[-beam_index:]
start_word = start_word[-1][0]
intermediate_caption = [ixtoword[i] for i in start_word]
final_caption = []
for i in intermediate_caption:
if i != 'endseq':
final_caption.append(i)
else:
break
final_caption = ' '.join(final_caption[1:])
return final_caption
步骤7:评估
现在,我们在不同的图像上测试模型,并查看其生成的字幕。我们还将研究由贪婪搜索和Beam搜索生成的具有不同k值的不同字幕。
首先,我们将看一下本文开头看到的示例图像。我们看到图片的标题是“雪中的黑狗和棕狗”。让我们看看我们的模型如何比较。
pic = '2398605966_1d0c9e6a20.jpg'
image = encoding_test[pic].reshape((1,2048))
x=plt.imread(images_path+pic)
plt.imshow(x)
plt.show()
print("Greedy Search:",greedySearch(image))
print("Beam Search, K = 3:",beam_search_predictions(image, beam_index = 3))
print("Beam Search, K = 5:",beam_search_predictions(image, beam_index = 5))
print("Beam Search, K = 7:",beam_search_predictions(image, beam_index = 7))
print("Beam Search, K = 10:",beam_search_predictions(image, beam_index = 10))
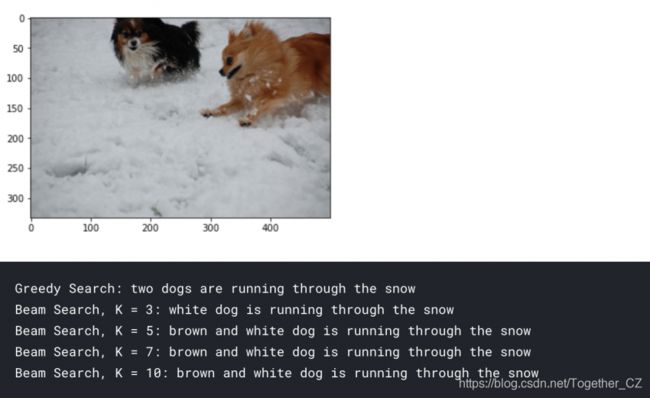
您可以看到我们的模型能够识别出雪中的两只狗。但与此同时,它把黑狗误分类为白狗。然而,它能够构成一个恰当的句子来像人类一样描述图像。
我们再来看一些示例:
pic = list(encoding_test.keys())[1]
image = encoding_test[pic].reshape((1,2048))
x=plt.imread(images_path+pic)
plt.imshow(x)
plt.show()
print("Greedy:",greedySearch(image))
print("Beam Search, K = 3:",beam_search_predictions(image, beam_index = 3))
print("Beam Search, K = 5:",beam_search_predictions(image, beam_index = 5))
print("Beam Search, K = 7:",beam_search_predictions(image, beam_index = 7))

在这里我们可以看到我们准确地描述了图像中发生的事情。您还将注意到使用Beam Search生成的字幕要比Greedy Search更好。
我们还来看看由我们的模型生成的错误标题:

我们可以看到,该模型在光束搜索中显然对图像中的人数进行了错误分类,但是我们的贪婪搜索能够识别出该人。
瞧!我们已经成功创建了自己的图像标题生成器!
下一步是什么?
我们今天开发的仅仅是开始。关于此主题的研究很多,您可以制作出更好的图像标题生成器。
您可以实施以改善模型的事情:
1、利用较大的数据集,尤其是MS COCO数据集或比MS COCO大26倍的Stock3M数据集。
2、利用评估指标来衡量机器生成的文本的质量,例如BLEU(双语评估研究)。
3、实现基于注意力的模型:基于注意力的机制在深度学习中正变得越来越流行,因为它们可以在生成输出序列时动态地专注于输入图像的各个部分。
4、基于图像的事实描述不足以生成高质量的字幕。我们可以添加外部知识以生成有吸引力的图像标题。因此,处理开放域数据集可能是一个有趣的前景。
尾注
恭喜你!您已经学习了如何从头开始制作图像字幕生成器。在这样做的同时,您还学习了如何将计算机视觉和自然语言处理领域整合在一起,并实现了一种类似于Beam Search的方法,该方法能够生成比标准更好的描述。
从使用的数据集到实施的方法论,还有很多地方可以改进。确保尝试一些建议,以改善发电机的性能,并与我分享您的结果!
作者:沂水寒城,CSDN博客专家,个人研究方向:机器学习、深度学习、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
赞 赏 作 者

更多阅读
2020 年最佳流行 Python 库 Top 10
2020 Python中文社区热门文章 Top 10
5分钟快速掌握 Python 定时任务框架
特别推荐


点击下方阅读原文加入社区会员