读 RocketMQ 源码,学习并发编程三大神器
这个系列会针对NLP比赛,经典问题的解决方案进行梳理并给出代码复现~也算是找个理由把代码从TF搬运到torch。Chapter1是CCF BDC2019的赛题:金融信息负面及主体判定,属于实体关联的情感分类任务,相关代码实现以及Top方案梳理详见ClassisSolution/fin_new_entity。数据lookalike如下

赛题分析
赛题本身已经对金融网络文本进行了实体抽取,跳过了金融实体抽取的步骤,只需要对已抽取出的实体判断文本是否描述了该金融实体的负面信息。只看问题本身和属性级情感分类问题有些类似,例如电商领域需要从评论中抽取产品多个属性各自的正负面评价,像价格[低]但是质量[差],可以得到价格和质量两个属性分别的正面和负面情绪。不过难点上有所不同,属性情感识别上,不同属性的评价词会有比较显著的差异,在金融实体中,因为实体本身多是并列关系,需要学习更复杂的上下文差异。
比赛的效果评估采用综合F1,分别计算句子级别的情感分类F1和实体级别的F1。整体任务F1=0.4句子F1+0.6实体F1。不过官网已经不能提交测试集评估,因此下面方案尝试我从训练集切了20%的样本来做效果评估
方案梳理
梳理了下Top方案的差异,主要在以下几个方面:预处理,实体处理方式,多任务,继续预训练
预处理
- 文本清洗
文本是爬取的新闻,html标签比较多。不过不是抽取类任务所以我只过滤了一些高频的标签和pattern,没有做的非常细致,在分类任务上基本不会有太大的影响。
def text_preprocess(s):
if not s:
return s
s = full2half(s)
s = re.sub('\{IMG:.?.?.?\}', ' ', s) # 图片
s = re.sub(re.compile(r'https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+'), ' ', s) # 网址
s = re.sub(re.compile('<.*?>'), '', s) # 网页标签
s = re.sub(r'&[a-zA-Z0-9]{1,4}', ' ', s) # > &type &rdqu ....
s = re.sub('^\?+', '', s) # 问号开头直接删除
s = re.sub('\?{2,}', ' ', s) # 中间出现多余1个问号用空格替代
s = re.sub('^#', '', s) # 井号开头直接删除
s = re.sub('#+', ' ', s) # 井号在中间用空格分隔
s = re.sub('\[超话\]', ' ', s) # 超话删除
return s
- 长文本处理
长文本处理一般是截断,段落或者句子过Encoder再在上游融合。因为要预测实体是否负面,主需要保留实体周围的上下文即可。并且赛题文本中有部分是前半段讲实体1,后半段讲实体2,且情绪不同,如果使用全文本预测反而会增加混淆度。因此选择根据实体位置进行文本截断,定位实体首次出现的位置,如果位置>max_seq_len,则截取实体周围的上下文作为样本。这里我直接简单粗暴地截取了前后250个字,更优的方案还是按句子切分,定位到实体出现的句子,截取前后的完整句子,保证语义的通顺,在实体发现的案例中我做了这种处理。
- 过滤冗余信息
相比直接拼接标题和正文,可以针对标题和正文的重合度(编辑距离),判断标题是否有信息补充,如果没有可以选择只保留正文。我尝试后对效果影响不大,不过会适当降低文本长度,以及优化文本的语义通顺度。在医疗文本分类中,处理患者主诉,和医生病例文本时尝试过这个方案,会有一定的效果提升
建模
虽然问题本身看起来很像一个pipeline问题,先判断句子是否负面,再定位负面句子中哪些实体为负面。但其实可以被简化成一个属性(实体)情感分类问题,只需要对样本进行下重构,把一条文本中每个实体是否负面的判别问题,拆分成多条样本,每个样本只预测一个实体是否负面。当预测一个实体时,文本中其他实体属于伴随实体。方案的主要差异在于如何处理待预测实体和伴随实体
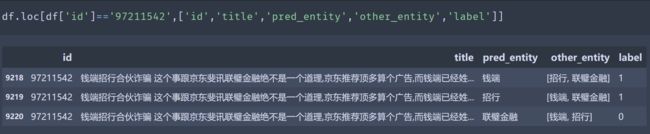
- 处理待预测实体
- 把待预测实体作为一路输入

- 借鉴关系抽取使用标识符标记实体

- 处理伴随实体
- 直接用特殊token替换,降低伴随实体对待预测实体的影响,提高模型泛化

- 把伴随实体拼接作为一路输入

都是实体,为什么需要区别对待呢?
个人认为待预测实体比伴随实体更需要学到'负面实体出现的上下文'这个信息,而伴随实体的作用更多是提示模型这些span本身是实体,也就是金融领域知识的引入。两种待预测实体的标识方案,效果上差不多,我更倾向于特殊标识的方案,因为这个方案能引入更多的位置信息。两种伴随实体的处理方案中,把伴随实体作为一路输入的效果更好,所以我感觉伴随实体的span信息更重要,降低对预测实体的影响这一点可能没有那么重要。
 |
|||
|---|---|---|---|
多任务优化
虽然把pipeline任务简化成了属性分类,但是句子级别的情感信息依旧是建模中可以尝试引入的优化点。如果能识别句子非负则实体全部非负,如果句子为负则实体为负的概率更高。因此可以尝试引入更简单的句子级别的情感分类作为一路辅助任务。句子和实体共享文本Encoder,同时各自的头分别学习各自的label,效果上句子级别的F1提升比较明显。
| 方案 | F1_entity | F1_sentence | F1 |
|---|---|---|---|
| Format3:双输入,1为伴随实体拼接,2title+text,带预测实体用[E]标记 | 94.5% | 95% | 94.7% |
| Format4: Format3基础上加入多任务同时学习实体+句子负面 | 94.8% | 95.5% | 95.1% |
TAPT优化
在Bert手册中Bert不完全手册8. 预训练不要停!Continue Pretraining我们聊过继续预训练范式。考虑赛题本身是金融领域,因此可以尝试用任务样本继续预训练(TAPT)来进行效果优化。
不过这里和原始论文不同的是,我调整了继续预训练的任务目标。把样本中抽取出来的实体词加入了分词器,在Whole Word MASK的基础上补充了金融实体粒度的词信息,进行实体和全词掩码的继续预训练,训练了10个epoch。然后再进行以上的多任务学习,整体还会有微小0.1个点的F1提升,这个提升我怀疑是波动哈哈哈....毕竟样本这么小,你想要啥自行车~
| 方案 | F1_entity | F1_sentence | F1 |
|---|---|---|---|
| Format4: Format3基础上加入多任务同时学习实体+句子负面 | 94.8% | 95.5% | 95.1% |
| Format5:Format4基础上加入TAPT | 95.0% | 95.6% | 95.2% |
除此之外top方案中还有MRC之类的方案,我们在其他的多分类任务中再做尝试。这里的方案梳理更多是对模型结构,建模范式,数据处理方案的讨论,像Ensemble,不同预训练模型选择一类的细节,大家感兴趣可以去看Repo中梳理的Top方案~