elt和etl_ETL和ELT架构概述
elt和etl
This article explains what the basic features and differences between ETL and ELT are. I’m also going to explain in detail what an ELT pipeline is and a relevant architecture for the same in Azure. So far, we have come a long way dealing with ETL tools which basically are Extract, Transformation and Load technique used in populating a data warehouse. ELT, on the other hand, is another way to load data into a warehouse that implements the process of Extract, Load and Transform.
本文介绍了ETL和ELT之间的基本特征和区别。 我还将详细解释什么是ELT管道以及Azure中相同的相关体系结构。 到目前为止,我们在处理ETL工具方面已经走了很长一段路,这些工具基本上是用于填充数据仓库的Extract,Transformation和Load技术。 另一方面,ELT是将数据加载到实现提取,加载和转换过程的仓库中的另一种方法。
When we try to understand ETL, it is the technique that we use to connect to source data, extract the data from those sources, transform the data in-memory to support the reporting requirements and then finally load the transformed data into a data warehouse. In a typical ETL workload, the tool can connect to the source databases periodically and extract the data from those sources. Further, these extraction methods are either full or incremental loads, which means either the complete data from the source is loaded or only a changed portion of the data.
当我们尝试理解ETL时,它是一种用于连接到源数据,从这些源中提取数据,对内存中的数据进行转换以支持报告要求,然后最终将转换后的数据加载到数据仓库中的技术。 在典型的ETL工作负载中,该工具可以定期连接到源数据库,并从这些源中提取数据。 此外,这些提取方法是完全加载或增量加载,这意味着将加载源中的完整数据或仅更改数据的一部分。
The figure below provides a graphical illustration of an ETL workload. Notice that the data is extracted from the sources and then transformed by the ETL tool in memory before being loaded into the warehouse.
下图提供了ETL工作负载的图形说明。 请注意,数据是从源中提取的,然后由ETL工具在内存中进行转换,然后再加载到仓库中。

Figure 1 – Overview of ETL
图1 – ETL概述
ELT is another technique, where the data is extracted and loaded into the warehouse directly without any transformations. Once the extract and load process has been completed, the transformation logic is applied to the warehouse where the data is stored. This transformed data is then again loaded back into the warehouse from where reporting and other business decisions can be supported. In the later part of this article, I’ll sight why we would need to use this technique over the traditional ETL method that we have been using for so long and differentiate the features between ETL and ELT workloads.
ELT是另一种技术,无需任何转换即可直接将数据提取并加载到仓库中。 提取和加载过程完成后,转换逻辑将应用于存储数据的仓库。 然后,将这些转换后的数据再次加载回仓库,从那里可以支持报告和其他业务决策。 在本文的后半部分,我将了解为什么我们需要在已经使用了很长时间的传统ETL方法上使用此技术,并区分ETL和ELT工作负载之间的功能。
In the figure below, the difference between ETL and ELT is clearly visible, as in this case, the data is extracted and loaded into the warehouse first and then transformed.
在下图中,ETL和ELT之间的区别清晰可见,因为在这种情况下,首先提取数据并将其加载到仓库中,然后进行转换。

Figure 2 – Overview of ELT
图2 – ELT概述
我们为什么需要ELT? (Why do we need ELT?)
The traditional method of using the ETL architecture is monolithic in nature, often used to connect only to schema-based data sources and they have very little or no room to process data flowing at very high speed. With the businesses dealing with high velocity and veracity of data, it becomes almost impossible for the ETL tools to fetch the entire or a part of the source data into the memory and apply the transformations and then load it to the warehouse.
使用ETL体系结构的传统方法本质上是整体的,通常用于仅连接到基于模式的数据源,并且它们几乎没有空间或没有空间来处理高速数据流。 随着业务处理高速和准确的数据,ETL工具几乎不可能将全部或部分源数据提取到内存中并应用转换,然后将其加载到仓库中。
In modern applications, we tend to have a variety of different data sources ranging from structured schema-based SQL sources to an unstructured NoSQL database. These different data sources rarely have any identical schema and each time a new source is added it becomes difficult or more time consuming to implement the logic in a traditional ETL tool.
在现代应用程序中,我们倾向于拥有各种不同的数据源,从基于结构化架构SQL源到非结构化NoSQL数据库。 这些不同的数据源很少具有相同的架构,并且每次添加新的源时,在传统ETL工具中实现逻辑变得困难或耗费更多时间。
An important factor that leads to the implementation of ELT systems is the adoption of the cloud data warehouses or data lakes by the organizations. An example of a cloud data warehouse is Azure Synapse Analytics (formerly known as Azure SQL Data Warehouse) or maybe Amazon RedShift. These cloud data warehouses have an MPP architecture (Massively Parallel Processing) and can be provisioned in very little time. Snowflake is also an example of a cloud data warehouse where all the infrastructure is managed, and customers need not worry about anything other than designing the business logic.
导致实施ELT系统的重要因素是组织采用云数据仓库或数据湖。 云数据仓库的一个示例是Azure Synapse Analytics(以前称为Azure SQL数据仓库)或Amazon RedShift。 这些云数据仓库具有MPP架构(大规模并行处理),可以在很短的时间内配置。 Snowflake也是云数据仓库的一个示例,其中所有基础结构都受到管理,客户除了设计业务逻辑外,无需担心其他任何事情。
Also, these cloud data warehouses support the columnar store which is very helpful while analyzing large datasets with petabytes of data. In a columnar store, the data is stored by columns as opposed to the traditional method of row-wise data stores. In addition to this, cloud data warehouses are provisioned to run in multiple nodes with a combination of various RAMs and SSDs to support the high-speed processing of data. These are a few reasons which make a cloud data warehouse suitable for transforming and analyzing data on the fly without affecting the query performance.
而且,这些云数据仓库支持列式存储,这在分析具有PB级数据的大型数据集时非常有帮助。 在列式存储中,与按行数据存储的传统方法相反,数据按列存储。 除此之外,云数据仓库被配置为在具有各种RAM和SSD的组合的多个节点中运行,以支持数据的高速处理。 这些是使云数据仓库适合在不影响查询性能的情况下即时转换和分析数据的一些原因。
比较ETL和ELT (Comparing ETL and ELT)
| ETL |
ELT |
|
| Technology Adoption |
ETL has been in the market for over two decades now and is relatively easier to find developers who have vast experience in designing ETL systems. |
On the other hand, ELT is a new technology that is more focused on cloud-based warehouses. Searching suitable engineers to develop ELT pipelines are as easy as for ETL. |
| Data Availability |
In an ETL workload, the data which is required only for analytics or reporting is being loaded into the warehouse, leaving other unnecessary data in the source systems as is. |
Whereas in an ELT system, we tend to load anything and everything into a warehouse or a data lake from where it can be analyzed at a later point of time. |
| Calculated Fields and Transformations |
Yes, in ETL, we can add or remove specific columns while transforming the data in the ETL tool. We can also add calculated columns and load them to the warehouse. |
In ELT, additional columns are directly added to the existing dataset in the warehouse. Usually, there is no modification of the source columns. |
| Transformation Complexities |
In an ETL workload, we can implement much complex data transformations as and when required. All these transformations occur in-memory. |
In an ELT workload, the more focus is given towards analyzing highly variable structured and unstructured data that is arriving at a high pace rather than complexities. |
| Infrastructure |
Most of the traditional ETL tools need to be installed on-premises which incur a lot of cost to the analytics workloads. |
ELT, on the other hand, is mostly cloud-based and doesn’t require to be installed on the premises. |
| Postproduction Maintenance |
In an ETL pipeline, that is installed on-premises, maintenance is frequently required. |
ELT, since it is cloud-based or serverless, no or very little maintenance is required. |
| Transformation Area |
In an ETL pipeline, the transformations are applied in memory in a staging layer before the data is being loaded into the data warehouse. |
In ELT, the transformations are applied once the data has been loaded into the warehouse or a data lake. In this case, usually, there is no requirement for a staging layer unlike in the ETL. |
| Support for semi-structured and unstructured data |
Although an ETL tool can read data from semi-structured or unstructured data sources, it is usually transformed in the staging layer and only stored as a proper structure in the warehouse. |
ELT is designed to handle all types of data structures from semi-structured to unstructured data in the data lakes which can be further analyzed. |
ETL |
电报 |
|
技术采用 |
ETL进入市场已有二十多年了,相对容易找到在ETL系统设计方面具有丰富经验的开发人员。 |
另一方面,ELT是一项新技术,更侧重于基于云的仓库。 寻找合适的工程师来开发ELT管道与使用ETL一样容易。 |
资料可用性 |
在ETL工作负载中,仅将分析或报告所需的数据加载到仓库中,而其他不必要的数据则保留在源系统中。 |
而在ELT系统中,我们倾向于将任何东西都装载到仓库或数据湖中,以便以后可以对其进行分析。 |
计算场和变换 |
是的,在ETL中,我们可以在ETL工具中转换数据时添加或删除特定的列。 我们还可以添加计算出的列并将其加载到仓库中。 |
在ELT中,其他列直接添加到仓库中的现有数据集中。 通常,没有对源列的修改。 |
转型的复杂性 |
在ETL工作负载中,我们可以在需要时实现非常复杂的数据转换。 所有这些转换都发生在内存中。 |
在ELT工作负载中,将更多的精力放在分析高速变化的结构化和非结构化数据上,而不是复杂性。 |
基础设施 |
大多数传统ETL工具都需要在本地安装,这会导致分析工作负载的大量成本。 |
另一方面,ELT主要是基于云的,不需要在内部安装。 |
后期制作维护 |
在本地安装的ETL管道中,经常需要维护。 |
ELT,因为它是基于云的或无服务器的,所以不需要或只需很少的维护。 |
改造区 |
在ETL管道中,在将数据加载到数据仓库之前,将转换应用到过渡层的内存中。 |
在ELT中,一旦将数据加载到仓库或数据湖中,便会应用转换。 在这种情况下,通常,与ETL不同,不需要过渡层。 |
支持半结构化和非结构化数据 |
尽管ETL工具可以从半结构化或非结构化数据源中读取数据,但通常会在登台层中进行转换,并且仅以适当的结构存储在仓库中。 |
ELT旨在处理数据湖中从半结构化数据到非结构化数据的所有类型的数据结构,可以对其进行进一步分析。 |
Azure中的ETL和ELT工作负载示例 (Example of ETL and ELT Workloads in Azure)
Now that we have some idea about the comparisons between ETL and ELT, let us go ahead and see how a typical ELT workload can be implemented in Azure.
现在我们对ETL和ELT之间的比较有了一些了解,让我们继续看看如何在Azure中实现典型的ELT工作负载。

Figure 3 – ELT Workload in Azure (Source)
图3 – Azure中的ELT工作负载( 源 )
As you can see in the figure above, the on-premises data is first ingested into the blob storage which is a file system in the cloud and from there it is computed and stored in the SQL Data Warehouse for further analysis. To read more about this architecture, please follow the official documentation from Microsoft.
如您在上图中所看到的,首先将本地数据提取到Blob存储中,该Blob存储是云中的文件系统,然后从那里计算出该数据并将其存储在SQL数据仓库中以进行进一步分析。 要阅读有关此体系结构的更多信息,请遵循Microsoft的官方文档 。
In the next figure, you can see how data is being imported from the various data sources and then ingested into the SQL Data Warehouse using Data Factory. Further, a semantic model is created using Azure Analysis Services and the data is visualized using Power BI.
在下图中,您可以看到如何从各种数据源导入数据,然后使用数据工厂将其提取到SQL数据仓库中。 此外,使用Azure Analysis Services创建语义模型,并使用Power BI可视化数据。
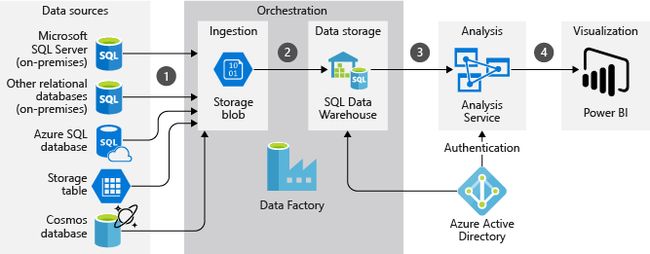
Figure 4 – ELT Tools in Azure (Source)
图4 – Azure中的ELT工具( 源 )
结论 (Conclusion)
In this article, we talked about the main differences between ETL and ELT architecture. Data processing is an important operation for an organization, and it should be chosen carefully. Although there are a few differences between ETL and ELT, for most of the modern analytics workload, ELT is the most preferred option as it reduces the data ingestion time to a great extent as compared to the traditional ETL process. This helps organizations to make faster decisions and improvise analytical capabilities.
在本文中,我们讨论了ETL和ELT体系结构之间的主要区别。 数据处理对于组织来说是一项重要的操作,应谨慎选择。 尽管ETL和ELT之间有一些区别,但是对于大多数现代分析工作负载而言,ELT是最可取的选择,因为与传统的ETL过程相比,它极大地减少了数据提取时间。 这可以帮助组织做出更快的决策并提高分析能力。
翻译自: https://www.sqlshack.com/an-overview-of-etl-and-elt-architecture/
elt和etl