hive中连续N天登录问题、topN问题、拉链表实现
一、连续N天登录问题
一般采用开窗函数来实现
首先需要用到窗口函数的向下取值
窗口函数lead
功能:用于从当前数据中基于当前行的数据向后偏移取值
语法:lead(colName,N,defautValue)
colName:取哪一列的值
N:向后偏移N行
defaultValue:如果取不到返回的默认值
分析:将所有的登录时间也就是那一天登录的,分组排序,然后向后取值,再通过date_add()函数也将登录时间(具体哪一天)向后取值,最后比较两者的时间是否相等。最后去重即可得到登录连续N天登录问题。
with t1 as (
select
userid,
logintime,
--本次登陆日期的第三天
date_add(logintime,2) as nextday,
--按照用户id分区,按照登陆日期排序,取下下一次登陆时间,取不到就为0
lead(logintime,2,0) over (partition by userid order by logintime) as nextlogin
from tb_login )
select distinct userid from t1 where nextday = nextlogin;
最终连续N天登录的通用解题公式为
with t2 as (
select
userid,
logintime,
--本次登陆日期的第N天
date_add(logintime,N-1) as nextday,
--按照用户id分区,按照登陆日期排序,取下下一次登陆时间,取不到就为0
lead(logintime,N-1,0) over (partition by userid order by logintime) as nextlogin
from tb_login)
select distinct userid from t2 where nextday = nextlogin;
二、hive中常见的TopN问题
工作中经常需要实现TopN的需求,例如热门商品Top10、热门话题Top20、热门搜索Top10、地区用户Top10等等,TopN是大数据业务分析中最常见的需求。
普通的TopN只要基于数据进行排序,然后基于排序后的结果取前N个即可,相对简单,但是在TopN中有一种特殊的TopN计算,叫做分组TopN。
分组TopN指的是基于数据进行分组,从每个组内取TopN,不再基于全局取TopN。如果要实现分组取TopN就相对麻烦。
分析:需要用到开窗函数的排序函数row_number、rank、dense_rank等,分组排序得到序号构建新的排序列名,该序号是按照1,2,3,…进行排序,需要需要前多少个,再在where中进行限定即可
with是将前面的开窗函数的查询结构存储为临时表,需要topN就在临时表的where中进行限定
with t1 as (
select
empno,
ename,
salary,
deptno,
row_number() over (partition by deptno order by salary desc) as rn
from tb_emp )
select * from t1 where rn < N;
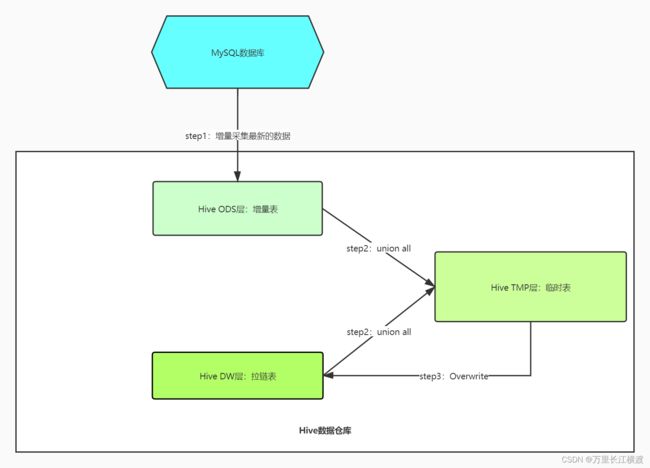
三、hive中拉链表实现
解决数据状态变化,将连续变化的状态都存储在一张表中,记录状态的历史变化过程
实现原理
hive中的if函数
语法
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
说明: 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull
合并拉链表与增量表
insert overwrite table tmp_zipper
select
userid,
phone,
nick,
gender,
addr,
starttime,
endtime
from ods_zipper_update
union all
--查询原来拉链表的所有数据,并将这次需要更新的数据的endTime更改为更新值的startTime
select
a.userid,
a.phone,
a.nick,
a.gender,
a.addr,
a.starttime,
--如果这条数据没有更新或者这条数据不是要更改的数据,就保留原来的值,否则就改为新数据的开始时间-1
if(b.userid is null or a.endtime < '9999-12-31', a.endtime , date_sub(b.starttime,1)) as endtime
from dw_zipper a left join ods_zipper_update b
on a.userid = b.userid ;
if(b.userid is null or a.endtime < ‘9999-12-31’, a.endtime , date_sub(b.starttime,1))
意思为如果b.userid is null or a.endtime < '9999-12-31’成立,则返回 a.endtime,如果前面的b.userid is null or a.endtime < '9999-12-31’不成立,则返回date_sub(b.starttime,1)
总结:对原始拉链表和增量表构建笛卡尔集,将原始表中的endtime进行判断,根据判断结果进行重新赋值,再从笛卡尔集中select与原始拉链表需要的字段,这样就原始拉链表中的endtime时间进行了修改,最后通过union all不去重的方式,将增量表的数据行记录增加在后面。这样在对原始的拉链表数据进行覆盖重写就得到了新的拉链表。
insert overwrite table dw_zipper
select * from tmp_zipper;