CONSISTENCY REGULARIZATION FOR GENERATIVE ADVERSARIAL NETWORKS
CONSISTENCY REGULARIZATION FOR GENERATIVE ADVERSARIAL NETWORKS
众所周知,生成对抗网络(gan)很难训练,尽管有相当多的研究努力。已经提出了几种用于稳定训练的正则化技术,但是它们引入了大量的计算开销,并且与现有的技术(如光谱归一化)相互作用很差。在这项工作中,我们提出了一种简单有效的训练稳定器,基于一致性正则化的概念——半监督学习文献中流行的技术。
特别是,我们增强了传入GAN判别器的数据,并惩罚了判别器对这些增强的敏感性。我们进行了一系列的实验,证明一致性正则化在光谱归一化和各种GAN架构、损失函数和优化器设置下有效地工作。与CIFAR-10和CelebA上的其他正则化方法相比,我们的方法实现了无条件图像生成的最佳FID得分。
此外,我们的一致性正则化GAN (CR-GAN)在CIFAR-10上将条件生成的FID评分从14.73提高到11.67,在ImageNet-2012上从8.73提高到6.66。
1 INTRODUCTION
gan的一个主要问题是训练过程的不稳定性和结果对各种超参数的普遍敏感性(Salimans et al., 2016)。由于GAN训练隐式地要求在连续的高维参数空间中找到非凸博弈的纳什均衡,因此它比标准的神经网络训练要复杂得多。
事实上,形式上描述GAN训练过程的收敛性基本上是一个开放问题(Odena, 2019)。之前的工作(Miyato et al., 2018a;Odena等人,2017年)的研究表明,侧重于鉴别器的干预措施可以缓解稳定性问题。最成功的干预可分为两类, normalization and regularization。谱归一化是最有效的归一化方法,它将鉴别器中的权重矩阵除以其最大奇异值的近似。
对于正则化,Gulrajani等人(2017)惩罚了真实数据和生成数据之间的gradient norm of straight lines。Roth等人(2017)提出直接对训练数据和生成数据的平方梯度范数进行正则化。DRAGAN (Kodali et al., 2017)引入了另一种形式的梯度惩罚,其中训练数据的高斯扰动梯度将受到惩罚。可以预见同时进行正规化和正规化可以提高样品质量。
Roth等人(2017)提出directly regularize the squared gradient norm for both the training data and the generated data。DRAGAN(Kodali等人,2017)引入了另一种形式的梯度惩罚,对训练数据的高斯扰动的梯度进行惩罚。
人们可能预计同时进行正则化和归一化可以提高样本质量。然而,大多数这些基于梯度的正则化方法要么提供边际收益,要么在使用归一化时未能引入任何改进(Kurach等人,2019),这在我们的实验中也观察到了。这些正则化方法和光谱归一化的动机是控制判别器的Lipschitz常数。我们怀疑这可能是应用这两种方法不能导致叠加增益的原因。
在本文中,我们研究了一种称为一致性正则化的技术(Sajjadi等人,2016;Laine & Aila,2016;Zhai等人,2019;Xie等人,2019),与基于梯度的正则化器形成对比。一致性正则化被广泛用于半监督学习中,以确保分类器的输出对未标记的例子不受影响,即使它以保留语义的方式被增强了。
根据这种直觉,我们假设一个训练有素的鉴别器也应该被正则化,以具有一致性的性质,这使得鉴别器在任意语义保持扰动下保持不变,并更多地关注真实数据和虚假数据之间的语义和结构变化。因此,我们提出了一种简单的正则化GAN鉴别器:在将图像输入GAN鉴别器之前,我们对图像进行语义保持增强,并惩罚鉴别器对这些增强的敏感性。
这种方法使用简单,效果惊人。与以前的技术相比,它的计算成本也更低。更重要的是,在我们的实验中,当使用光谱归一化时,一致性正则化总是能够进一步提高模型性能,而在这种情况下,以往正则化方法的性能增益会减小。在广泛的消融研究中,我们发现它可以在大量的GAN变体和数据集上起作用。我们还表明,简单地将该技术应用于现有的GAN模型之上,将导致新的最先进的结果
综上所述,我们的贡献总结如下。
- 我们为GAN判别器提出了一致性正则化,以产生一个简单、有效的正则化器,其计算成本比基于梯度的正则化方法低。
- 我们对不同的GAN变体进行了广泛的实验,以证明我们的技术与频谱规范化的有效互动。我们的一致性正则化GAN(CR-GAN)在CIFAR-10和CelebA的无条件图像生成中取得了最好的FID分数。
- 我们表明,仅仅应用所提出的技术就可以进一步提高最先进的GAN模型的性能。我们在CIFAR-10上将条件图像生成的FID分数从14.73提高到11.67,在ImageNet-2012上从8.73提高到6.66。
2 METHOD
2.2 CONSISTENCY REGULARIZATION
一致性正则化已经成为图像数据半监督学习的黄金标准技术(Sajjadi等人,2016;Laine和Aila,2016;Zhai等人,2019;Xie等人,2019;Oliver等人,2018;Berthelot等人,2019)。其基本思想很简单:输入图像以某些保留语义的方式被扰动,分类器对该扰动的敏感性被惩罚。扰动可以有多种形式:可以是图像翻转、裁剪或对抗性攻击。正则化形式是模型对扰动和非扰动输入的输出之间的均方误差(Sajjadi等人,2016;Laine和Aila,2016),或者是输出logit所隐含的类别分布之间的KL散度(Xie等人,2019;Miyato等人,2018b)。
2.3 CONSISTENCY REGULARIZATION FOR GANS
gan中鉴别器的目的是区分真实数据和生成器产生的虚假数据。该决策对任何有效的特定于领域的数据扩充都是不变的。例如,在图像域中,如果我们水平翻转图像或平移图像几个像素,图像是否真实不应该改变。然而,GANs中的鉴别器并不明确保证这个属性。
为了解决这个问题,我们提出了在训练过程中对GAN鉴别器进行一致性正则化的方法。在实践中,当训练图像被传递到鉴别器时,我们随机增强训练图像,并惩罚鉴别器对这些增强的敏感性。
我们用 D j ( x ) D_j (x) Dj(x)表示给定输入x的鉴别器第j层激活前的输出向量。T(x)表示一个随机数据增广函数。这个函数可以是线性的,也可以是非线性的,但目的是保持输入的语义。我们提出的正则化是由
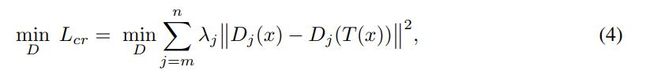
λj是第j层的权重系数,k-k表示一个给定向量的L2准则。这种一致性正则化鼓励判别器在各种数据增量下对数据点产生相同的输出。
其中,j为层索引,m为开始层,n为强制一致性的结束层。 λ j λ_j λj是第j层的权重系数, ∣ ∣ ⋅ ∣ ∣ ||\cdot|| ∣∣⋅∣∣表示给定向量的L2范数。这种一致性正则化鼓励鉴别器在各种数据增强下为数据点产生相同的输出。
在我们的实验中,我们发现在激活函数之前,在鉴别器的最后一层上的一致性正则化是足够的。Lcr可以重写为

从现在开始,为了简洁起见,我们将删除层索引。当更新鉴别器参数时,这个代价被添加到鉴别器损失中(由超参数λ加权)。生成器更新保持不变。因此,总体一致性正则化GAN (CR-GAN)目标为
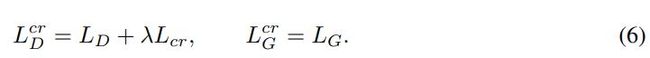
我们设计的Lcr是通用的,因此可以与GAN的任何有效的对抗性损失LG和LD一起工作(例子见2.1节)。算法1以Wassertein损失为例说明了CR-GAN的细节。与以前的正则器相比,我们的方法并没有增加多少开销。唯一的额外计算成本来自于更新判别器参数时,通过判别器向前和向后输入额外的(第三张)图像。
