XGBoost原理(1)集成学习与XGBoost基础知识
相关专题:XGBoost实践篇、XGBoost原理篇
- 前言
- 一.集成学习及主要方法
-
- 1.1Boosting 串行方法
- 1.2Bagging 并行方法
- 1.3Stacking 融合方法
- 二.XGBoost算法基础知识
-
- 2.1模型:加法模型
- 2.2目标函数:损失函数
- 2.3算法:前向分布算法
- 2.4基模型:Booster
前言
XGBoost模型调参、训练、评估、保存和预测及4篇相关文章(模型评估和可解释性)已经详细介绍了XGBoost的实战应用。但对于XGBoost的加法模型、前向分布算法以及目标函数、优化方法、切分点查找、分布式计算等原理并未涉及。从本篇文章开始将逐步学习XGBoost算法原理。
机器学习的特点:入门门槛低、学习曲线陡。写给自己:这个过程就像邓宁-克鲁格心理效应曲线一样,从实战出发的我至此已经到达了“愚昧山峰”,接下来的学习目标就是“梯度下降”至“绝望之谷”,绝望之时愿能开启“开悟之路”。“大师”的地方是XGBoost的创造者陈天齐博士这样的大佬才能到达的“高原之巅”,我等凡夫俗子敬仰膜拜即可。
一.集成学习及主要方法
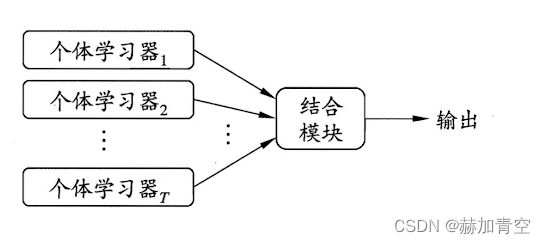
集成学习(ensemble learning)通过将多个学习器进行组合来完成学习任务。下图显示集成学习的一般结构(取自周志华老师的西瓜书),个体学习器通常由一种现有的学习算法从训练数据产生,例如决策树(C4.5、CART)、BP神经网络等。集成中只包含同种类型的个体学习器时,集成是同质的,同质集成中的个体学习器也称为“基学习器”,相应学习算法称为“基学习器算法”;集成中包含不同类型的个体学习器时,例如既有决策树又有神经网络,这样的集成是异质的,异质集成中个体学习器由不同学习算法生成,这时不再有基学习器算法,相应的个体学习器一般不称为基学习器,直接称为“个体学习器”或“组件学习器”。
1.1Boosting 串行方法
Boosting是将弱学习算法提升为强学习算法的机器学习方法,采用加法模型(即基函数的线性组合)与前向分步算法。通俗解释:Boosting会训练一系列弱分类器,并将所有学习器的预测结果组合起来作为最终预测结果,在学习过程中,后期的学习器更关注先前学习器学习中的错误。
-
典型算法
Adaboost、GBDT、XGBoost、LightGBM等,其中AdaBoost继承了Boosting的思想,为每个弱学习器赋予不同权值,将所有弱分类器权重和作为预测的结果,达到强学习器的效果;Gradient Boosting是Boosting思想的另一种实现方法,它将损失函数梯度下降的方向作为优化的目标,新的学习器建立在之前学习器损失函数梯度下降的方向,在梯度下降的方向不断优化,使损失函数持续下降,从而提高模型的拟合程度,代表算法GBDT、XGBoost、LightGBM;GBDT(Gradient Tree Boosting,别名 GBM、GBRT、MART)是Gradient Boosting的一种实现,GBDT相较BDT(提升树)基学习器都是采用CART回归树,但BDT是不断拟合残差来优化目标函数,GBDT是通过负梯度近似残差来优化目标函数(即损失函数);XGBoost和LightGBM都是GBDT的改进模型,最终这两个模型成为了集大成者,适合于分类、回归、排序等问题(多种基学习器);支持分布式并行计算(Rabit),具有高可移植性(XGBoost4J-Spark、XGBoost4J-Flink);支持GPU算法加速;结果也更加精准(目标函数用二阶泰勒张开近似);泛化能力更强(加入了结构误差项——正则化降低模型复杂度)。 -
算法特点
Boosting可以有效提高模型准确性,但各个学习器直接只能串行生成,时间开销较大(XGBoost和LightGBM在这方面已经做了极大的改进)
1.2Bagging 并行方法
Bagging对数据集进行有放回采样,得到每个基模型所需要的子训练集,然后对所有基模型预测结果进行综合,产生最终的预测结果。对于分类问题,采用投票法(软投票、硬投票)计算结果;对于回归问题,采用平均法计算结果。
- 典型算法
Random Forests随机森林(简称RF)是Bagging最具代表性的算法,基学习器采用决策树,并且在Bagging样本扰动(行采样)的基础上增加了属性扰动(列采样),进一步丰富了样本的多样性。 - 算法特点
Bagging模型的精度要比Boosting低,但各个学习器直接可以并行生成,时间开销较小(RF模型仅采用决策树作为基模型,进一步优化可训练效率)
1.3Stacking 融合方法
Stacking是通过训练集训练好所有的基模型,然后用基模型的预测结果生成一个新的数据,作为组合器模型的输入,用以训练组合器模型,最终得到预测结果。组合器模型通常采用逻辑回归。
- 算法特点
Stacking一般采用异质集成,即使用多种学习算法训练不同种类的个体学习器。而Boosing和Bagging采用同质集成,即基学习器为同一种基学习算法。
二.XGBoost算法基础知识
XGBoost属于Boosting模型,由华盛顿大学陈天齐博士提出,因在机器学习挑战赛中大放异彩而被业界所熟知。相比越来越流行的深度神经网络,XGBoost能更好的处理表格数据,并具有更强的可解释性,还具有易于调参、输入数据不变性等优势。这些在XGBoost实践篇:XGBoost模型调参、训练、评估、保存和预测 及相关文章中已做详细说明,不再赘述。
2.1模型:加法模型
XGBoost同其他的Boosting模型一样,都是加法模型。通俗理解:假设基模型为CART回归树模型(即'booster'='gbtree'),XGBoost训练了一系列二叉树分类器,每个分类器都有至少2个叶子节点,叶子节点权值即为回归树的预测结果,样本在多个分类器落入的叶子节点权值相加,即为模型最终的预测结果得分。依据任务不同得分的后续处理也不同,例如二分类任务最终得分会使用Sigmoid函数映射到[0,1]的值进而完成预测任务(具体的过程以及多分类、回归的转换方式会在后续章节详细解释)。

上图为陈天齐博士XGBoost论文内容(下文皆简称“论文”),展示了加法模型的原理,两棵树tree1和tree2分别有自己的叶子节点权值,权值相加便是模型对样本的预测结果得分,例如15岁以下男性使用电脑,预测值y=tree1(节点编号2)+tree2(节点编号1)=2+0.9=2.9。(节点/结点采用从上至下从左至右的方法从0开始编号)。
论文中加法模型公式表达如下公式(1),K个 f ( x i ) f(x_i) f(xi)模型结果相加即为预测值y。
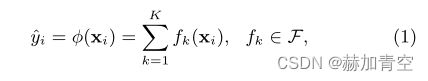
2.2目标函数:损失函数
目标函数为模型训练提供了优化方向,机器学习中通常使用损失函数做为目标函数,拟合目标为“残差”最小化(残差=预测值-真实值),使得模型预测结果逐步逼近真实值(残差越小,损失越小,模型越好)。
论文中(2)是 L ( ϕ L(\phi L(ϕ) 是XGBoost目标函数的表达,第一项是 l l l(预测值y,真实值y)和的损失函数,用于评估模型预测值与真实值之间的误差或损失;第二项是正则化项,用来控制模型复杂度,正则化倾向于选择简单的模型,避免过拟合。也有文章中称第一项为为经验损失,第二项为结构损失。
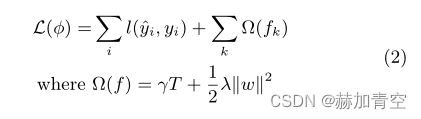
XGBoost引入二阶泰勒展开近似和简化目标函数,并通过一阶梯度统计和二阶梯度统计来表示,所以XGBoost的损失函数(公式(2)的第一项)必须是可微分的凸函数,而且需满足二次可微条件(这里仅做简单说明,后续文章会详细讲解二阶泰勒展开近似的目标函数,以及公式的推到过程)。
2.3算法:前向分布算法
论文中下图公式可见,由公式(2)演变预测值 y i Λ y_i ^\Lambda yiΛ的 y i ( t ) = y i ( t − 1 ) + f ( x i ) y_i^{(t)}=y_i^{(t-1)}+f(x_i) yi(t)=yi(t−1)+f(xi) ,其中 y i ( t − 1 ) y_i^{(t-1)} yi(t−1)是上一个模型的预测结果,已经是一个常数固定值。
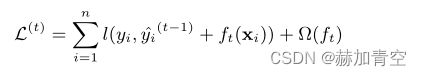
2.4基模型:Booster
XGBoost提供3种基模型(即参数booster)可选gbtree、dart、gblinear,其中gbtree是CART回归树(注释1),且最为常用;dart也是树模型,借鉴了深度神经网络的dropout技术防止过拟合;gblinear为线性模型,采用Elastic Net回归和并行坐标下降法实现。
内容注释:
1.CART为二叉树,有分类树也有回归树,XGBoost只使用回归树
未完待续…