数据挖掘-理论与算法(公开课笔记二)

目录
-
- 6.1 Clustering 聚类
-
- 6.1.1 Unsupervised Learning 无监督学习
- 6.2.1 Clustering Algorithm 聚类算法
- 6.3.1 EM Method 期望最大法
- 6.4.1 Density/Hierarchical Based Methods 密度与层次
- 7 Assocation Role 关联规则
-
- 7.1.1 Assocation Role 关联规则
- 7.2.1 Support&Confidence of Association Role 支持度 置信度
- 7.3.1 About Assocation Role 关联规则的误区
- 7.4.1 Apriori Method Apriori算法
- 7.6.1 Sequential Pattern 序列模式
- 8 Recommendation Algorithms
-
- 8.1.1 Recommend Algorithm 推荐算法
- 8.2.1 Text Analysis 文本分析
- 8.3.1 PageRank 网页评分
- 8.4.1 Collaborative Filtering 协同过滤
- 9 Ensemble Learning 集成学习
-
- 9.1.1 Ensemble 民主协商
- 9.2.1 Bagging 群策群议
- 9.3.1 Boosting 环环相扣
- 10 Evolutionary Algorithms 进化算法
-
- 10.1.1 Evolutionary 进化
- 10.2.1 Objective Function 目标函数
- 10.4.1 Genetic Algorithm(1) 遗传算法-初探(1)
- 10.5.1 Genetic Algorithm(3) 遗传算法-可能性(3)
- 10.6.1 Genetic Algorithm(4) 遗传算法-遗传程序(4)
- 10.7.1 Genetic Algorithm(5) 遗传算法-遗传硬件(5)
6.1 Clustering 聚类
6.1.1 Unsupervised Learning 无监督学习
相似性导致聚集,聚类有两种:分割型聚类(将数据进行分块),层次型聚类(根据不同层次分块)。聚类与分类相似,不同的是聚类要规定相似度(Similarity)。
聚类是无监督学习,无标签,没有绝对标准答案。
目的:使不同簇(clusters)之间距离最远,相同簇最近。
数据预处理对聚类影响很大,要谨慎对待。如坐标压缩、数据标准化等,如下图。
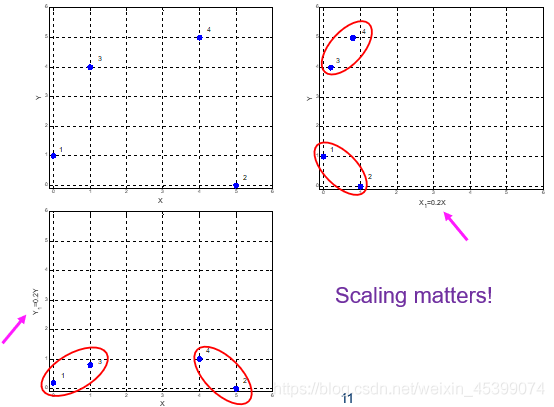
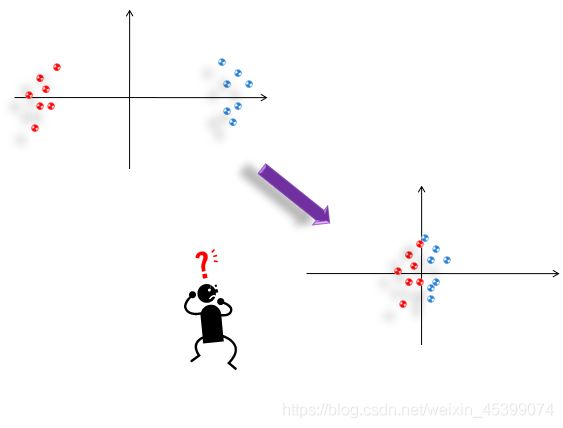
6.2.1 Clustering Algorithm 聚类算法
**Silhouette:**衡量聚类效果的参数,一般在[0,1)间,也存在少数负数
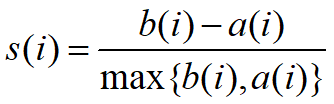
其中,a代表与聚类在同一个簇之间的平均距离,b代表与聚类在不同簇之间的最小平均距离。
K-Means算法:
- 要分n块,则随机选n个种子点(模型参数)
- 根据n个点将数据域划分
- 计算数据域的中心点,更新为种子点,循环到1步
优点:对“球形”数据效果好,收敛快(一般5,6步能出结果)
缺点:K值难以不确定,初始点不好可能导致陷入局部最优点,噪点影响大,对“异型数据”适应性不好
最终目的:求出把数据域分成n块的n个中心点(参数)
Sequential Leader Clustering算法:
可以应对数据流进行聚类,且不需要迭代,一遍过,且不需要确定K。
进来的数据,根据设定距离极限,直接与现有中心点距离进行比较,大于则自成中心,小于则加入簇中。
对于距离限设定比较敏感,太小则会产生很多簇,太大簇又会过少。
6.3.1 EM Method 期望最大法
混合高斯模型-(Gaussian Mixture):用不同高斯分布进行叠加,每个分布都有相应权重(αi),权重和为1。
- 高斯分布


期望最大化算法-EM:类似于K均值聚类,先随机生成各参数,再通过不断迭代进行训练,调整参数。
6.4.1 Density/Hierarchical Based Methods 密度与层次
为了解决“非规则分布”数据和“大噪声”数据的问题,从密度方向解决问题
优点:不需要设定K值或距离极限(虽然还要定义一个距离参数)
DBSCAN算法:通过点与点之间的距离进行聚类,不断递归膨胀,其中距离参数即为分类的层面,越小的话分类层析越低,越大分类层次越高。

核心点(Core Point):在一定距离(需要用户设定)内有足够的点
边缘点(Border Point):在核心点距离范围内且不是核心点的点
噪点(Noise Point):既不是核心点也不是边缘点(需要排除)
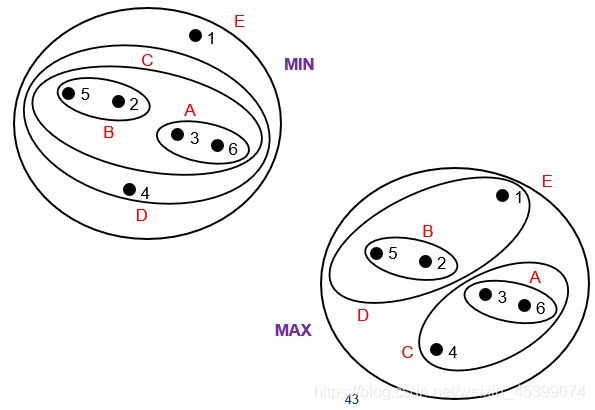
Hierarchical Based Methods:算模型中每个点与其他点的距离矩阵,选模型中最近的两个点合并进一个簇,迭代至只有一个簇结束。

-
最小距离法:合并后新簇与其他簇的距离,为两簇中距离最小的点之间的距离
-
最大距离法:合并后新簇与其他簇的距离,为两簇中距离最大的点之间的距离
7 Assocation Role 关联规则
7.1.1 Assocation Role 关联规则
目的:在庞大的元素库中找出元素之间的关联关系
这个规则主要应用在商品的推销上(啤酒与尿布)
还可以延伸用于文字分析,把单个单词看做元素,对每篇文章分析即可得出单词之间的关联关系
7.2.1 Support&Confidence of Association Role 支持度 置信度
支持度在关联规则分析中就是频率(关联发生的次数总次数 / 总次数)
置信度为在某元素出现的情况下关联发生的概率(关联发生的次数 / 包含某一元素的次数 )即条件概率


注意规则顺序,顺序相反Support不变,Confidence会变化。
在大元素集中,组合的数量会快速增加,同时记录也是海量的,一条一条验证显然不可行。·宏观处理:
- 设置一个支持度、置信度的一个限值
- 把所有频繁的组合找出来
- 生成频繁组合的所有非空子集,并写出所有可能的子集关联规则
- 计算所有子集关联规则的支持度与置信度
- 比较子集的支持度、置信度与设定的限值,若超过则认为关联性强
7.3.1 About Assocation Role 关联规则的误区
规则的关联性很强并不一定代表该规则有意义(当两个元素频率差别特别大时尤为明显,如一个商品几乎每个人都会买,而另一个商品买的人很少)
关联规则就是一个条件概率,两件事物相关,并不一定他们之间有代表因果关系,不应做过多解释。
7.4.1 Apriori Method Apriori算法
元素因为排列组合,所有可能的非空关联的数量非常庞大(2d−1),不能用传统方法解决。
原理:
- 任何一个频繁项的非空子集必须频繁
- 如果某个子项不频繁,那么他的超集必然不频繁
相当于一个剪枝算法。
具体步骤:
- 生成某个特定大小的频繁集(一般为1)
- 对频繁集进行组合,并删除频繁集
- 迭代运行1,2
核心思想:尽量避免生成不频繁集
缺点:本算法需要频繁扫描数据库,而这种操作在大型数据库中成本较高
7.6.1 Sequential Pattern 序列模式
在一般的记录中,不包含记录产生的时间或者购买人,那么对于序列先后或间隔的分析就无法进行。
目的:分析某事发生后,另一件事就有可能发生
我们将序列按先后时间排序,若某 元素顺序 持续在序列集中出现,那么该 元素顺序 就是一个序列(不一定要直接连续,允许有间隔)
方法:先找短序列,不断连接变为长序列,并检验是否频繁即可。
8 Recommendation Algorithms
8.1.1 Recommend Algorithm 推荐算法
应用:精准广告营销、协同推荐、音乐推荐。
8.2.1 Text Analysis 文本分析
Tf-idf:输入关键词,量化该词与数据库词中的关联情况
关键词频率-TF(Term Frequency):关键词的频率

(某词在全文中出现的频数 / 全文词总频数)
逆文档频率-(Inverse Document Frequency):该单词在其他文档中的频率(作用:过滤诸如“the”“a”之类的词)
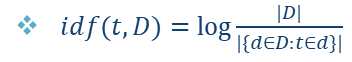
(log(所有文档个数 / 包含特定词文档个数))
单词-文本矩阵-(Term-Document matrix):在文本处理时,将单词和多个文本的tf-idf值组成矩阵并进行计算
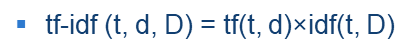
在计算机处理文档时,一般将文章处理为向量并进行计算夹角。

在文档处理时,近义词(Synonymy)、多义词(Polysemy)的存在会干扰文档处理。
隐含语义分析-LSA(Later Semantic Analysis):将矩阵放进新的空间而不是原空间进行分析。

- 将XX分解为TSD-1
- 选择几个信息量最大的维度并进行降维
- 将降维后矩阵乘回去并画图
- 对新得的图进行聚类
8.3.1 PageRank 网页评分
页面评分-(PageRank):网页可以被看为互相有链接的文档,其PageRank值越高代表网页越好。
指向某网页的链接越多、指向来源的PR值越高、指向来源的指向链接越少,某网页质量越高。

即:(来源网站PR值 / 来源网站的链接数)之和
即:t+1秒时网站的PR值,是一个迭代值,最终收敛为定值
- d-阻尼参数(damping factor):固定参数,一般取0.85
- (1 - d) / N 是让所有时间所有网页PR值和为1
8.4.1 Collaborative Filtering 协同过滤
核心思想:收集兴趣相似的用户的打分信息,并制作打分矩阵,表示并推测每个人对每个商品的喜爱程度。
既可以在用户间计算关联,也可以在商品之间计算关联,也可以建立模型进行计算,在不同情况下采用的算法也不一样。
可能影响算法的因素:
- 灰羊效应:即介于黑白之间的情况
- 冷启动:用户新来平台,没有数据,如何推荐
- 网络水军的故意攻击
- 用户的打分习惯(有人习惯打高分,有人习惯打低分,因此要与平均分进行计算)
9 Ensemble Learning 集成学习
9.1.1 Ensemble 民主协商
核心思想:有策略的集中不同类型的分类器,根据综合结果得出结论。
也可以对模型进行拆分,将复杂的问题拆成简单的问题来解决。本质上是分类器的实用策略。
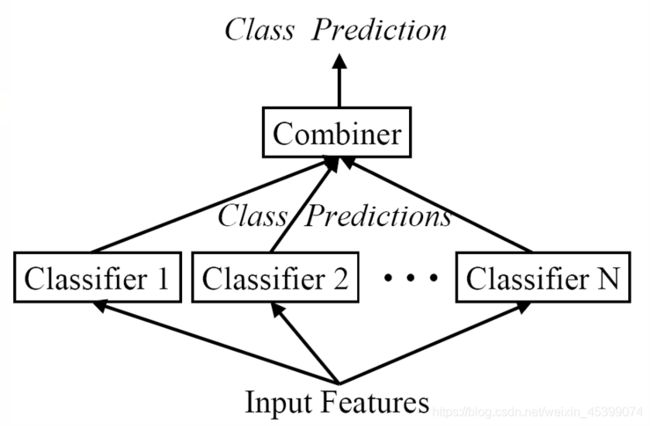
集成学习不是一个算法,而是一大类算法。
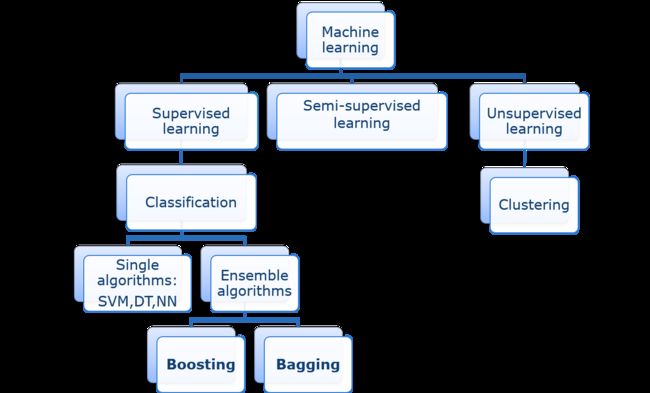
9.2.1 Bagging 群策群议
在集成学习中,集中策略可以使用“少数服从多数”或“权重”来决定最终决策走向,且不用担心过学习问题。
为了保证各个分类器结论相似而不同,可以使用不同部分的数据集来训练每个分类器。
引导聚集算法-Bagging(Bootstrap Aggregating):
- 将数据集用bootstrap法采样为若干子数据集
- 在子数据集上训练分类器
- 用这些分类器处理数据,根据结果“少数服从多数”得出答案
此类算法可以有效降低bias,并能够降低variance。
未选入子数据集的数据(OOB-Out Of Bag,大约⅓)可以用来检验。
随机森林(Random Forests):是一种集成算法(Ensemble Learning),它属于Bagging类型,通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能。其可以取得不错成绩,主要归功于“随机”和“森林”,一个使它具有抗过拟合能力,一个使它更加精准。
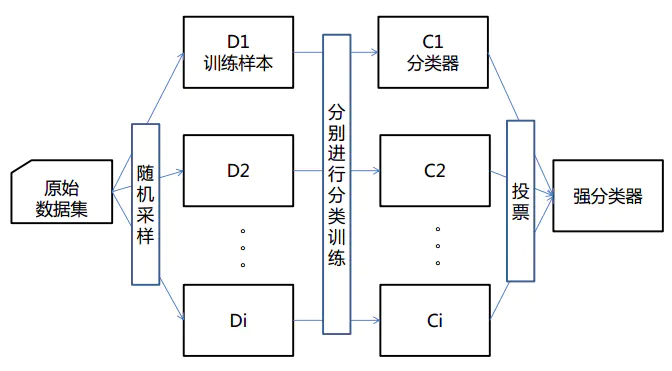
9.3.1 Boosting 环环相扣
每个分类器分类效果不同,每个数据集容易被分对的可能性也不同,他们所占的权重也不应该相同,这里的权重也可以学习。
Stacking算法(并行):在原始的分类器(学习输出结果)输出基础上,再过一层分类器(学习各个分类器的权重),从而得出最终结果。可以视为Bagging的升级版。
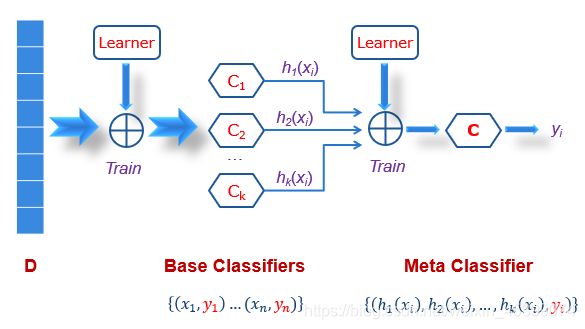
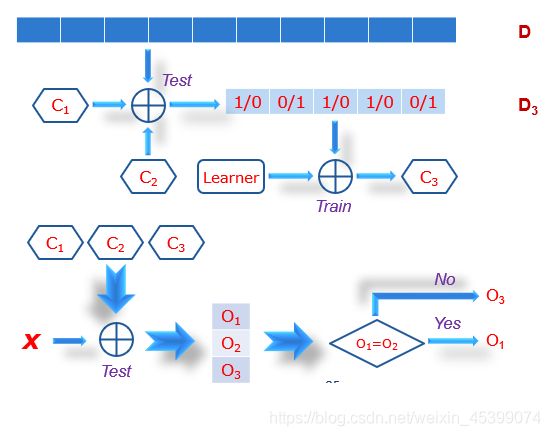
Boosting算法(串行):先训练一个分类器,对于分对的和分错的分开划分数据集,针对正误数据集进行继续训练(相当于对训练集加权重,越多分类器分错,该数据集权重越大)
C1先训练,C2训练C1分类错误的。

找出C1与C2的不一致,训练新的分类器C3。(注意:C1、C2、C3是顺序生成的)
10 Evolutionary Algorithms 进化算法
10.1.1 Evolutionary 进化
进化算法的目的:
- 优化(广义的)
- 进行模拟,帮助人类理解自然的进化
特点:
- 基于数量的
- 有随机性
- 并行(不易局部最优)
- 适者生存
- 不局限于某种特定问题,可能是普适的
- ……
10.2.1 Objective Function 目标函数
机器学习算法本质还是优化问题,只不过有难有易。
现实中的大部分问题都是复杂的,很难直接暴力解决,必须要进行优化。
10.4.1 Genetic Algorithm(1) 遗传算法-初探(1)
遗传算法是松散的基于达尔文进化论,并不是完全相同的。
遗传算法的几部分:表示(二进制还是格雷码等)、遗传、选择、变异、表达(向量)
格雷码与二进制的区别:系统在每一次变化时,码值只会变化一位,更加稳定。
在设置权重的时候,可以用原始值比例确定,也可以用序号确定(防止过于优秀的个体占据了过大概率)。
在选择时,可以两两PK选择,可以精英选择(防止突变导致的结果不稳定),可以用百分率选择。
10.5.1 Genetic Algorithm(3) 遗传算法-可能性(3)
遗传算法在维度过大时复杂度会比较高,要进行适当的选择。
遗传算法在分类和聚类中均可以应用。
Pareto Front:在多目标优化的情况下,基于不同的评判角度无法选择最优点,此时交给用户选择。
10.6.1 Genetic Algorithm(4) 遗传算法-遗传程序(4)
遗传算法-(Genetic Algorithm)与遗传程序-(Genetic Program) 的区别:遗传算法输出的是模型参数,遗传程序输出的则是一段计算机程序。
遗传程序将计算式表示为树,针对树进行杂交进行优化,一模一样的树在杂交后也能产生新树。
评判方式:用积分计算目标值与当前值之间差异部分的面积,面积大则拟合性不好。
10.7.1 Genetic Algorithm(5) 遗传算法-遗传硬件(5)
可计划电路-(Evolvable Circuits):硬件的线路可以变化并改变结构,实现原先没有的功能。
用途:
- 芯片在遇到设计时未想到的情况时,能自行修整并应对环境。
- 设计天线形状达到最优性能
- 汽车的外形设计
- ”人工生命“
- 程序绘画、谱曲
困难的地方:对于运行结果的评价是难以量化并打分的,可能需要人类的评判。