股票分析,利用线性回归实时预测股价,只需要提供股票代码即可爬取相应股票数据并建模
这里参考了别人的代码,并引用了tushare模块中定义的接口自动获取了依据 股票代码来获取数据
此篇文章提供了
1.一个简单通过接口爬取csv数据的方法
2.一个处理csv数据的简单方法
3.依据数据进行特征提取建立简单的股价预测模型
如下:
使用的话只需要修改对应的股票代码即可
我这里使用的是 300015 爱尔眼科的股票代码
import numpy as np
import pandas as pd # 数据处理, 读取 CSV 文件
import matplotlib.pyplot as plt
import tushare as ts
from plotly.offline import init_notebook_mode, iplot, iplot_mpl
import plotly.graph_objs as go
from sklearn.linear_model import LinearRegression
from sklearn import preprocessing
import sklearn
# 000001 为平安银行
# 获取股票的数据
# 如果你还没有安装, 可以使用 pip install tushare 安装tushare python包
Stock_Code = 300015 #爱尔眼科
df = ts.get_hist_data(f'{Stock_Code}')
df.to_csv(f'{Stock_Code}.csv')
df = pd.read_csv(f'./{Stock_Code}.csv')
print(np.shape(df))
print(df[0:10])
df.head()
'''股票数据的特征
*date:日期
*open:开盘价
*high:最高价
*close:收盘价
*low:最低价
*volume:成交量
*price_change:价格变动
*p_change:涨跌幅
*ma5:5
日均价
*ma10:10
日均价
*ma20: 20
日均价
*v_ma5: 5
日均量
*v_ma10: 10
日均量
*v_ma20: 20
日均量
'''
本接口即将停止更新,请尽快使用Pro版接口:https://tushare.pro/document/2
(600, 15)
date open high close low volume price_change p_change \
0 2022-03-25 30.51 31.22 29.66 29.50 556807.50 -0.85 -2.79
1 2022-03-24 29.37 31.00 30.51 29.17 734351.69 0.78 2.62
2 2022-03-23 28.28 29.95 29.73 28.04 712581.62 1.70 6.07
3 2022-03-22 28.20 28.64 28.03 27.95 327752.81 -0.46 -1.61
4 2022-03-21 28.83 28.90 28.49 28.11 400047.69 -0.12 -0.42
5 2022-03-18 29.01 29.19 28.61 27.91 782520.00 -0.84 -2.85
6 2022-03-17 28.00 30.44 29.45 28.00 1401702.38 2.18 7.99
7 2022-03-16 26.84 27.38 27.27 25.28 1626294.12 0.33 1.23
8 2022-03-15 30.00 30.70 26.94 25.02 1815843.62 -3.47 -11.41
9 2022-03-14 31.87 32.20 30.41 30.10 518120.59 -2.09 -6.43
ma5 ma10 ma20 v_ma5 v_ma10 v_ma20 turnover
0 29.284 28.910 31.459 546308.26 887602.20 633485.26 1.25
1 29.074 29.194 31.745 591450.76 863570.32 639080.99 1.65
2 28.862 29.347 31.892 724920.90 827310.41 621764.07 1.60
3 28.370 29.530 32.132 907663.40 806734.83 599018.34 0.74
4 28.152 30.028 32.434 1205281.56 814264.94 595898.22 0.90
5 28.536 30.444 32.735 1228896.14 827720.85 589260.22 1.76
6 29.314 31.081 33.057 1135689.89 774035.25 559168.78 3.14
7 29.832 31.657 33.334 929699.92 656945.54 501548.91 3.65
8 30.690 32.486 33.718 705806.27 518786.47 437122.81 4.07
9 31.904 33.423 34.131 423248.32 367355.32 385054.37 1.16
'股票数据的特征\n*date:日期\n*open:开盘价\n*high:最高价\n*close:收盘价\n*low:最低价\n*volume:成交量\n*price_change:价格变动\n*p_change:涨跌幅\n*ma5:5\n日均价\n*ma10:10\n日均价\n*ma20: 20\n日均价\n*v_ma5: 5\n日均量\n*v_ma10: 10\n日均量\n*v_ma20: 20\n日均量\n'
将日期的键值的类型从字符串转为日期
df['date'] = pd.to_datetime(df['date'])
categories = {'volume','v_ma5','v_ma10','v_ma20'}
'''数值大小尽量统一化'''
for cate in categories:
df[cate] = df[cate]/10000
df = df.set_index('date')
# 按照时间升序排列
df.sort_values(by=['date'], inplace=True, ascending=True )
df.tail()
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | turnover | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | ||||||||||||||
| 2022-03-21 | 28.83 | 28.90 | 28.49 | 28.11 | 40.004769 | -0.12 | -0.42 | 28.152 | 30.028 | 32.434 | 120.528156 | 81.426494 | 59.589822 | 0.90 |
| 2022-03-22 | 28.20 | 28.64 | 28.03 | 27.95 | 32.775281 | -0.46 | -1.61 | 28.370 | 29.530 | 32.132 | 90.766340 | 80.673483 | 59.901834 | 0.74 |
| 2022-03-23 | 28.28 | 29.95 | 29.73 | 28.04 | 71.258162 | 1.70 | 6.07 | 28.862 | 29.347 | 31.892 | 72.492090 | 82.731041 | 62.176407 | 1.60 |
| 2022-03-24 | 29.37 | 31.00 | 30.51 | 29.17 | 73.435169 | 0.78 | 2.62 | 29.074 | 29.194 | 31.745 | 59.145076 | 86.357032 | 63.908099 | 1.65 |
| 2022-03-25 | 30.51 | 31.22 | 29.66 | 29.50 | 55.680750 | -0.85 | -2.79 | 29.284 | 28.910 | 31.459 | 54.630826 | 88.760220 | 63.348526 | 1.25 |
检测是否有缺失数据 NaNs
df.dropna(axis=0, inplace=True)#
df.isna().sum(),df.shape
(open 0
high 0
close 0
low 0
volume 0
price_change 0
p_change 0
ma5 0
ma10 0
ma20 0
v_ma5 0
v_ma10 0
v_ma20 0
turnover 0
dtype: int64,
(600, 14))
K线图
Min_date = df.index.min()
Max_date = df.index.max()
print("First date is", Min_date)
print("Last date is", Max_date)
print(Max_date - Min_date)
# %%
init_notebook_mode()
trace = go.Ohlc(x=df.index, open=df['open'], high=df['high'], low=df['low'], close=df['close'])
data = [trace]
iplot(data, filename='simple_ohlc')
运行出来的这个其实是个demo 并不是图片,可以点击查看具体数据
这里为了显示正常只是截图使用
线性回归
# 创建新的列, 包含预测值, 根据当前的数据预测5天以后的收盘价
date = "2022-03-15'"
num = 30 # 预测date num天后的情况
df['label'] = df['close']# 预测值 每天的最终股票价格
丢弃 ‘label’, ‘price_change’, ‘p_change’, 不需要它们做预测
Data = df.drop(['label', 'price_change', 'p_change'], axis=1)
print(Data.tail() )
X = Data.values
X = preprocessing.scale(X)
df.dropna(inplace=True)
Target = df.label
y = Target.values
print(np.shape(X), np.shape(y))
'''x 特征,y 股价'''
open high close low volume ma5 ma10 ma20 \
date
2022-03-21 28.83 28.90 28.49 28.11 40.004769 28.152 30.028 32.434
2022-03-22 28.20 28.64 28.03 27.95 32.775281 28.370 29.530 32.132
2022-03-23 28.28 29.95 29.73 28.04 71.258162 28.862 29.347 31.892
2022-03-24 29.37 31.00 30.51 29.17 73.435169 29.074 29.194 31.745
2022-03-25 30.51 31.22 29.66 29.50 55.680750 29.284 28.910 31.459
v_ma5 v_ma10 v_ma20 turnover
date
2022-03-21 120.528156 81.426494 59.589822 0.90
2022-03-22 90.766340 80.673483 59.901834 0.74
2022-03-23 72.492090 82.731041 62.176407 1.60
2022-03-24 59.145076 86.357032 63.908099 1.65
2022-03-25 54.630826 88.760220 63.348526 1.25
(600, 12) (600,)
'x 特征,y 股价'
# 将数据分为训练数据和测试数据
X_train, X_test, y_train ,y_test= sklearn.model_selection.train_test_split(X,y,test_size=0.1,random_state=42)
# %%
lr = LinearRegression()
lr.fit(X_train, y_train)
lr.score(X_train,y_train),lr.score(X_test, y_test) # 使用绝对系数 R^2 评估模型
(1.0, 1.0)
做预测
此处使用的特征是最近num天的特征,而目前使用的数据是之前的特征量,由于归一化,
实际上若真要预测,首先要预测这些特征的值随时间变化的概率
X_Predict = X[-num:]
Forecast = lr.predict(X_Predict)
print(Forecast.shape)
print(y[-num:].shape)
print(X_Predict.shape)
(30,)
(30,)
(30, 12)
### 画预测结果
# 预测
trange = pd.date_range(f'{date}', periods=num, freq='d')
print(trange)
# 产生预测值dataframe
Predict_df = pd.DataFrame(Forecast, index=trange)
Predict_df.columns = ['forecast']
Predict_df
# 将预测值添加到原始dataframe
df = pd.read_csv(f'./{Stock_Code}.csv')
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
# 按照时间升序排列
df.sort_values(by=['date'], inplace=True, ascending=True)
df_concat = pd.concat([df, Predict_df], axis=1)
df_concat = df_concat[df_concat.index.isin(Predict_df.index)]
df_concat.shape
DatetimeIndex(['2022-03-15', '2022-03-16', '2022-03-17', '2022-03-18',
'2022-03-19', '2022-03-20', '2022-03-21', '2022-03-22',
'2022-03-23', '2022-03-24', '2022-03-25', '2022-03-26',
'2022-03-27', '2022-03-28', '2022-03-29', '2022-03-30',
'2022-03-31', '2022-04-01', '2022-04-02', '2022-04-03',
'2022-04-04', '2022-04-05', '2022-04-06', '2022-04-07',
'2022-04-08', '2022-04-09', '2022-04-10', '2022-04-11',
'2022-04-12', '2022-04-13'],
dtype='datetime64[ns]', freq='D')
(30, 15)
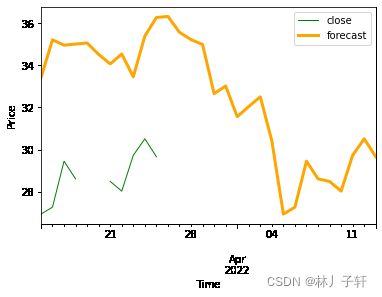
画预测值和实际值
df_concat['close'].plot(color='green', linewidth=1)
df_concat['forecast'].plot(color='orange', linewidth=3)
plt.xlabel('Time')
plt.ylabel('Price')
plt.legend()
plt.show()
这个图片之所以不连续,,因为周六,周日,股市不开业
问题:
预测的特征是按照最近几天的特征来写的
未深入分析会影响到股价的特征
可能的改进措施:
建立13个特征随时间变化的回归模型
再依据由13个模型预测的数值统筹为特征量再预测。
引入股票分析,金融分析的其他方法到机器学习特征中来。
未深入研究了,点到为止。。。
其他文章
Glcm 灰度共生矩阵,保姆级别教程,带源码
SVM支持向量机自动调优,带源码
HOG特征+SVM 进行行人检测,带源码,异常处理
Sober算子边缘检测与Harris角点检测1
参考文献
线性回归-股票预测