MySQL存储引擎InnoDB和MyISAM的区别
什么是存储引擎
从逻辑架构层面分析,MySQL 可以分为 Server 层和存储引擎层两部分。其中,存储引擎是 MySQL 区别于其它数据库的一个重要特性。
这里的存储引擎是什么意思呢?
数据库的诉求是对数据进行存储与管理。具体的数据是要保存在文件中还是内存中,索引采用哪些数据结构以及怎么保存,锁的粒度以及实现方式…等等,而选择具体方式来实现这些功能的组件在 MySQL 中被称作存储引擎。如 InnoDB 存储引擎将数据保存在文件中,支持事务,锁粒度可以支持行锁;Memory 存储引擎将数据保存在内存中,不支持事务,锁粒度只支持表锁。
MySQL 的存储引擎是基于表级别的。存储引擎的好处是,每个存储引擎都有各自的特点,我们可以根据具体的使用场景,来建立不同存储引擎的表。
MySQL 中有很多的存储引擎,其中 InnoDB 和 MyISAM 存储引擎是其中比较常用的,接下来我们来分析一下这两种存储引擎的区别。
InnoDB 和 MyISAM 存储引擎的区别
| InnoDB | MyISAM | |
|---|---|---|
| 存储结构 | .frm - 表结构文件, .ibd - 存储数据和索引的文件 (或所有数据和索引保存在共享表空间文件中) |
.frm - 表结构文件 .MYD(MYData) - 存储数据的文件 .MYI(MYIndex) - 存储索引的文件 |
| 事务 | 支持 | 不支持 |
| 外键 | 支持 | 不支持 |
| 索引实现方式 | B+树索引,InnoDB 是索引组织表 | B+树索引,MyISAM 是堆组织表 |
| 锁支持粒度 | 行级锁(默认)、表级锁 | 表级锁 |
| 记录存储顺序 | 按主键大小有序插入 | 按记录插入顺序保存 |
| select | MyISAM 性能更优 | |
| insert、update、delete | InnoDB 性能更优 | |
| select count(*) | MyISAM 更快 | |
| 哈希索引 | 支持(自适应 HASH) | 不支持 |
| 全文索引 | 不支持 | 支持 |
| 适用场景 | 主要面向联机事务处理(OLTP)的应用 (Online Transaction Processing) |
主要面向联机分析处理(OLAP)的应用 (Online Analytical Processing) |
| 默认存储引擎 | MySQL5.5之后 InnoDB 是默认存储引擎 | MySQL5.1.X之前 MyISAM 是默认存储引擎 |
InnoDB 存储引擎的索引实现
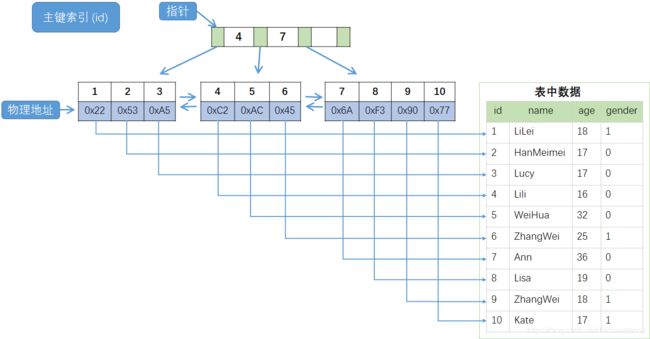
InnoDB 存储引擎把数据放在聚簇索引上,辅助索引保存的是聚簇索引的键值(如主键 id )。这种方式,我们称之为索引组织表(IOT:Index Organizied Table)。
InnoDB选取聚簇索引的规则如下:
- 如果表中定义了主键,则主键为聚簇索引;
- 如果没有主键,选择第一个非空的唯一索引为聚簇索引;
- 如果以上都没有,InnoDB 会隐式定义一个6字节的 rowid 主键来作为聚簇索引。
假如我们有这样一个表,建表语句如下:
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(32) NOT NULL COMMENT '姓名',
`age` tinyint(3) unsigned NOT NULL COMMENT '年龄',
`gender` tinyint(3) unsigned NOT NULL COMMENT '性别:1男,0女',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
InnoDB 中 聚簇索引 和 辅助索引 的结构如下图所示:


名词 “聚簇” 表示数据行和相邻的键值紧凑的存储在一起。因为不能同时把数据行存储在多个不同的地方,所以一个表只能有一个聚簇索引。但辅助索引可以有很多个。
MyISAM 存储引擎的索引实现
MyISAM 存储引擎采用的是把数据单独存放,索引上保存数据位置的数据组织形式。这种方式,我们称之为堆组织表(HOT:Heap Organizied Table)。
还是上边的表和数据,MyISAM 中的索引结构如下图所示:
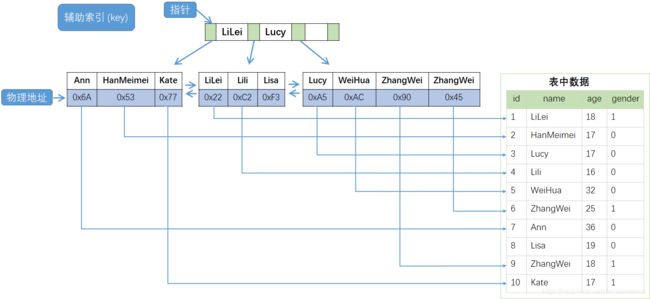
从上图可以看出,MyISAM 存储引擎中主键索引和辅助索引的结构是相同的,索引中保存的都是数据所在的物理地址。它们的不同点在于,主键不允许重复,而辅助索引字段可以允许重复。
InnoDB 引擎中行级锁的优缺点
顾名思义,行级锁就是针对数据表中行记录的锁。比如事务 A 中对一行数据做了更新操作,而这时候事务 B 也要更新同一行数据,则必须等事务 A 操作完成并提交事务后才能进行更新。
MySQL 的行级锁是在引擎层由各个引擎自己实现的,InnoDB 是支持行级锁的,这也是 MyISAM 被 InnoDB 替代的重要原因之一。
InnoDB的行级锁是实现在索引上的,而不是锁在物理行记录上。如果访问没有命中索引,也就无法使用行级锁,将会退化为表级锁。
行级锁的优点有:
- 在很多线程请求不同记录时减少锁冲突,锁定的数量越少,并发度越高。
- 事务回滚时减少改变数据。
- 使长时间对单独的一行记录加锁成为可能。
行级锁的缺点有:
- 行级锁比页级锁和表级锁占用更多的内存。
- 表级锁是不会出现死锁的,行级锁和页级锁使用不当会出现死锁问题。
- 当对表的操作绝大多数都是读取时,表级锁比页级锁和行级锁性能更高。
InnoDB 对死锁的处理:
InnoDB 引擎采用主动死锁检测策略,当发现死锁后,InnoDB 会主动回滚死锁链条中代价更低的那个事务(一般是持有锁较少的事务),让其他事务得以继续执行。
MyISAM 和 InnoDB 引擎中 count(*) 的实现方式
以 select count(*) from t 这条语句为例(注意这里不带任何的 where 条件)。
在 MyISAM 引擎 中,每个表的总行数都会在内存和磁盘文件中进行保存,内存中的 count 变量值通过读取文件中的 count 值来进行初始化。当执行 count(*) 语句的时候,会直接将内存中保存的数值返回,所以执行非常快。
而在 InnoDB 引擎中,当执行 count(*) 的时候,它需要一行一行的进行统计和计数,并将最终的统计结果返回。所以,随着表中数据越来越多,使用 InnoDB 引擎的表,count(*) 执行得也会越来越慢。
那为什么 InnoDB 引擎就不能像 MyISAM 引擎一样,也把总行数保存到内存和磁盘文件中呢?
这是因为 InnoDB 引擎实现了多版本并发控制(MVCC)的原因:对同一个表,不同事物在同一时刻,看到的数据可能是不一样的。
但如果加了 where 条件的话,MyISAM 引擎和 InnoDB 引擎一样,也是不能返回的这么快的。
MyISAM 和 InnoDB 引擎适合场景
适合 MyISAM 引擎的场景:
- 不要求事务。
- 对数据增删改频率不高,查询非常频繁。
- 频繁执行全表count语句。
适合 InnoDB 引擎的场景:
- 要求事务。
- 数据增删改相当频繁。
- MySQL5.5 版本之后 InnoDB 已经成为 Mysql 的默认存储引擎,如果不确定选择哪种,建议用 InnoDB 。