Pytorch实现Seq2Seq(Attention)字符级机器翻译
前言
前些天学了seq2seq和transformer,然后用机器翻译练习了一下,今天这篇博客就讲讲带注意力机制的seq2seq模型怎么做机器翻译。
数据集
准备数据集
我使用的数据集是从B站某个视频拿到的,但是忘了是哪个视频了,是已经排好序的中英平行语料,数据不多,两万多条正适合用来做练习。
数据集链接发在csdn了,大家可以去下载。
下载完成后解压到项目目录即可,可以看到这里有3个文件

ch.vec和en.vec分别是中文和英文字典,translate.csv是中英对照的平行语料。注意啊,ch.vec和en.vec是字典不是词典,所以本文是基于字符的翻译,不会使用word2vec。当然你可以试着改成基于word2vec的。
构建字典类
在上面的词典ch.vec和en.vec虽然已经包含了核心的word2index和index2word,但是我们还是稍微封装一下。
注意,当前的字典里是没有和,这些字符的,所以需要我们自己添加。
除此之外,在我们这个字典类也应该把句子和编码的相互转换实现方便调用。Tokenizer类如下
class Tokenizer:
def __init__(self, vocab_path, is_en=True):
with open(vocab_path, "rb") as f:
_, word2index, index2word = pickle.load(f)
f.close()
if is_en:
word2index = {word: index + 1 for word, index in word2index.items()}
word2index.update({"" : 0})
index2word = ["" ] + index2word
else:
word2index = {word: index + 3 for word, index in word2index.items()}
word2index.update({"" : 0, "" : 1, "" : 2})
index2word = ["" , "" , "" ] + index2word
self.word2index = word2index
self.index2word = index2word
self.PAD = 0
self.BOS = 1
self.EOS = 2
def encode(self, sentence):
return [self.word2index[w] for w in sentence]
def decode(self, indexes):
return [self.index2word[index] for index in indexes]
def length(self):
return len(self.index2word)
我们来测试一下


加载数据集
为了在训练时使用该数据集,我们需要重写Dataset类构建自己的dataset迭代器。
class MyDataset(Dataset):
@staticmethod
def get_data(dataset_path, nums=None):
all_datas = pd.read_csv(dataset_path)
en_data = list(all_datas["english"])
ch_data = list(all_datas["chinese"])
if nums is None:
return en_data, ch_data
else:
return en_data[:nums], ch_data[:nums]
# nums参数用于控制加载数据的条数,方便调试,为None加载全部
def __init__(self, dataset_path, en_tokenizer, ch_tokenizer, nums=None):
en_data, ch_data = self.get_data(dataset_path, nums=nums)
self.en_data = en_data
self.ch_data = ch_data
self.en_tokenizer = en_tokenizer
self.ch_tokenizer = ch_tokenizer
def __getitem__(self, index):
en = self.en_data[index]
en = en.lower()
ch = self.ch_data[index]
en_index = self.en_tokenizer.encode(en)
ch_index = self.ch_tokenizer.encode(ch)
return en_index, ch_index
def __len__(self):
assert len(self.en_data) == len(self.ch_data)
return len(self.ch_data)
正常来说我们在构造函数里加载完所有的数据,然后在getitem里面根据index获取单条数据并做一些处理。在这儿的处理就是将英文转换成小写,并且将句子转换成字典中的整数编码。
但是对于文本相关的任务我们需要对一个批次的数据进行填充对齐以方便进行矩阵计算。并且在解码的时候输入需要字符,标签又需要字符,所以我们还需要将中文句子的前后分别加上和字符。
因此,我们需要定义一个collate_fn的函数(我直接定义在了MyDataset类里边)
def collate_fn(self, batch_list):
en_index, ch_index = [], []
enPAD = self.en_tokenizer.PAD
chPAD = self.ch_tokenizer.PAD
BOS = self.ch_tokenizer.BOS
EOS = self.ch_tokenizer.EOS
for en, ch in batch_list:
en_index.append(torch.tensor(en))
ch_index.append(torch.tensor([BOS] + ch + [EOS]))
# from torch.nn.utils.rnn import pad_sequence
en_index = pad_sequence(en_index, batch_first=True, padding_value=enPAD)
ch_index = pad_sequence(ch_index, batch_first=True, padding_value=chPAD)
if not self.batch_first:
en_index = en_index.transpose(0, 1)
ch_index = ch_index.transpose(0, 1)
return en_index, ch_index
然后在定义dataloader的时候,指定collate_fn参数为该函数。
dataset = MyDataset("datas/translate.csv", en_tokenizer, ch_tokenizer, nums=None)
dataloader = DataLoader(dataset, batch_size=10, num_workers=0,collate_fn=dataset.collate_fn)
for en_index, ch_index in dataloader:
print(en_index)
print(ch_index)
break

到这我们的数据集的工作就准备好了,接下来搭建模型
搭建模型
结构概览
seq2seq是Encoder-Decoder的结构,我们先画个图,然后再根据图搭建模型。seq2seq的Decoder有几种结构(不管带不带Attention),我们这选择使用的是最简单的一种,即将encoder编码得到的上下文向量c作为decoder中的RNN的初始隐状态向量h0

我们将实现上图的结构并且在该基础上增加注意力机制。
增加注意力机制的Seq2seq如图
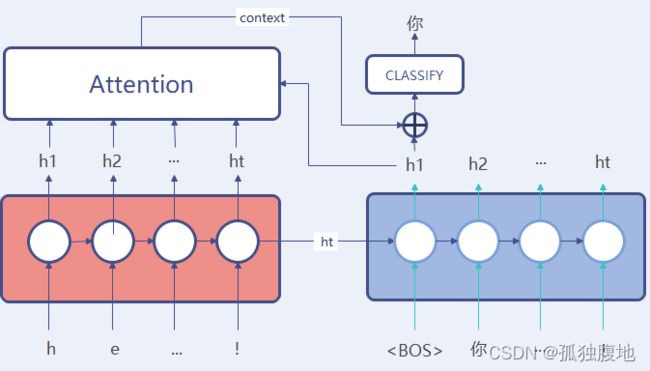
这个图还是需要稍微解释下,在decoder解码过程中,并不再直接根据隐状态解码,而是计算当前隐状态跟encoder输出的所有隐状态计算attention获得真正的上下文context,并将该上下文与当前隐状态拼接之后再进行分类。
Encoder
class Encoder(nn.Module):
def __init__(self, encoder_embedding_num, encoder_hidden_num, en_vocab_size):
super().__init__()
self.embedding = nn.Embedding(en_vocab_size, encoder_embedding_num)
self.rnn = nn.GRU(encoder_embedding_num, encoder_hidden_num,batch_first=True)
def forward(self, en_index):
en_embedding = self.embedding(en_index)
encoder_output, encoder_hidden = self.rnn(en_embedding)
return encoder_output, encoder_hidden
encoder的输入需要先经过一个embedding层把整数编码映射为高维向量,然后再传入RNN。我们这里使用的是GRU。如果想换成LSTM的话,大家就自己改改咯。
Decoder Without Attention
class Decoder(nn.Module):
def __init__(self, decoder_embedding_num, decoder_hidden_num, ch_corpus_len):
super().__init__()
self.embedding = nn.Embedding(ch_corpus_len, decoder_embedding_num)
self.rnn = nn.GRU(decoder_embedding_num, decoder_hidden_num, batch_first=True)
def forward(self, decoder_input, hidden):
embedding = self.embedding(decoder_input)
decoder_output, decoder_hidden = self.rnn(embedding, hidden)
return decoder_output, decoder_hidden
显然,如果不使用attention的话,encoder和decoder基本差不多。
Decoder With Attention
我们先把Attention搭建出来,这里的Attention计算采用的是点乘方式。如果对注意力机制还不了解可以去百度一下,在这儿就不多介绍了
class Attention(nn.Module):
def __init__(self):
super().__init__()
# decoder_state_t:decoder的当前隐状态
# encoder_outputs:encoder的所有输出
def forward(self, decoder_state_t, encoder_outputs):
b, s, h = encoder_outputs.shape
attention_scores = torch.sum(
torch.tile(decoder_state_t.unsqueeze(dim=1), dims=(s,1)) * encoder_outputs,dim=-1)
attention_scores = torch.softmax(attention_scores, dim=-1)
context = torch.sum(attention_scores.unsqueeze(dim=-1) * encoder_outputs, dim=1)
return context, attention_scores
有了Attention之后我们正式开始搭建Decoder。
值得注意的是,在AttentionDecoder中使用的是GRUCell而不是GRU,这样由我们自己实现遍历时间序列的过程从而方便实现引入Attention的逻辑
class AttentionDecoder(nn.Module):
def __init__(self,
decoder_embedding_num, decoder_hidden_num, ch_vocab_size,
ch_tokenizer,
dropout=0.3):
super().__init__()
self.embedding = nn.Embedding(ch_vocab_size, decoder_embedding_num)
self.gru = nn.GRUCell(decoder_embedding_num, decoder_hidden_num)
self.attention = Attention()
self.dropout = nn.Dropout(dropout)
def forward(self, decoder_input, encoder_hidden, encoder_output, epoch):
embed = self.embedding(decoder_input)
b, s, h = embed.shape
ht = encoder_hidden[0]
decoder_output = []
for t in range(s):
decoder_input = embed[:, t, :]
ht = self.gru(decoder_input, ht)
context, attention_probs = self.attention(ht, encoder_output)
ht = self.dropout(ht)
yt = torch.cat((ht, context), dim=-1)
decoder_output.append(yt)
decoder_output = torch.stack(decoder_output, dim=0)
decoder_output = decoder_output.transpose(0, 1)
return decoder_output
Seq2Seq
Encoder和Decoder搭建完,seq2seq搭建就很容易了,如下
class Seq2Seq(nn.Module):
def __init__(self,
encoder_embedding_num, encoder_hidden_num, en_vocab_size,
decoder_embedding_num, decoder_hidden_num, ch_vocab_size,
device='cpu',
dropout=0.3):
super().__init__()
self.encoder = Encoder(encoder_embedding_num, encoder_hidden_num, en_vocab_size)
self.decoder = AttentionDecoder(decoder_embedding_num, decoder_hidden_num, ch_vocab_size, dropout)
self.projection = nn.Linear(2 * decoder_hidden_num, ch_corpus_len)
self.device = device
def forward(self, en_index, ch_index, epoch):
en_index = en_index.to(self.device)
ch_index = ch_index.to(self.device)
encoder_outputs, encoder_hidden = self.encoder(en_index)
decoder_output = self.decoder(ch_index, encoder_hidden, encoder_outputs, epoch)
return self.projection(decoder_output)
然后,由于decoder使用了teacher-forcing,因此训练和推理时decoder的工作机制是不同的。训练时传入的是真实标签,推理时只能传入上一时刻的预测值。因此,我们需要重写推理的代码
如下,给定输入为一个真实的句子,设定可翻译的最大长度为50,防止翻译无法结束
def inference(self, sentence, en_tokenizer, ch_tokenizer, max_length=50):
sentence = sentence.lower()
with torch.no_grad():
en_index = torch.tensor([en_tokenizer.encode(sentence)], device=self.device)
encoder_output, encoder_hidden = self.encoder(en_index)
decoder_input = torch.tensor([[self.ch_tokenizer.BOS]], device=self.device)
ht = encoder_hidden[0]
predictions = []
for t in range(max_length):
embed = self.decoder.embedding(decoder_input)[:, 0, :]
ht = self.decoder.gru(embed, ht)
context, _ = self.decoder.attention(ht, encoder_output)
yt = torch.cat((ht, context), dim=-1)
pred = self.projection(yt)
w_index = int(torch.argmax(pred, dim=-1))
word = self.ch_tokenizer.decode(w_index)
if word == "" :
break
predictions.append(word)
decoder_input = torch.tensor([[w_index]], device=self.device)
return "".join(predictions)
到此为止,有关模型的部分就都结束了,接下来我们准备编写训练的代码。
训练
训练配置
parser = argparse.ArgumentParser()
parser.add_argument('--device', default="cuda:0" if torch.cuda.is_available() else "cpu")
# network structure
parser.add_argument('--encoder_embedding_size', default=128, type=int)
parser.add_argument('--decoder_embedding_size', default=128, type=int)
parser.add_argument('--hidden_size', default=256, type=int, help="rnn hidden size")
# hyper-parameters
parser.add_argument('--batch-size', default=32, type=int)
parser.add_argument('--lr', default=2e-3, type=float)
parser.add_argument('--lr_gamma', default=0.99, type=float)
parser.add_argument('--grad_clip', type=int, default=2333)
# other config
parser.add_argument('--epochs', default=200, type=int)
parser.add_argument('--seed', default=42, type=int)
parser.add_argument('--vocab', default='datas')
parser.add_argument('--logdir', default='runs', type=str)
parser.add_argument('--num_workers', default=0, type=int)
parser.add_argument('--nums', default=None, type=int)
opt = parser.parse_args()
train(opt)
训练使用的优化器是Adam,损失函数是交叉熵损失函数。
训练技巧方面引入了学习率指数衰减和梯度裁剪,梯度裁剪可能不大需要。
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=opt.lr_gamma)
# 损失函数
cross_loss = nn.CrossEntropyLoss()
好了,我们看看训练的结果吧

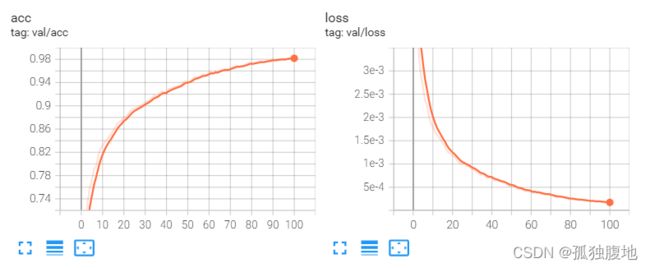
曲线很好看,但是因为teacher forcing的原因,这个验证的准确率不能反应真实的结果。
我们还是得实际测试一下
import argparse
import torch
from datasets import Tokenizer
def predict(opt):
device = opt.device
model = torch.load("runs/exp/weights/best.pt", map_location=device)
en_tokenizer = Tokenizer(f"{opt.vocab}/en.vec", is_en=True)
ch_tokenizer = Tokenizer(f"{opt.vocab}/ch.vec", is_en=False)
while True:
s = input("请输入英文:")
s = model.inference(s, en_tokenizer, ch_tokenizer)
print(s)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--device', default=torch.device("cuda:0" if torch.cuda.is_available() else "cpu"))
parser.add_argument('--vocab', default='datas')
opt = parser.parse_args()
predict(opt)

实际结果就很尴尬了,不过也正常,毕竟数据集太小了,这个结果还是能接受的。
训练代码
import argparse
import os
import random
import numpy as np
import torch
import torch.nn as nn
from tensorboardX import SummaryWriter
from torch.nn.utils import clip_grad_norm_
from tqdm import tqdm
from datasets import Tokenizer, MyDataset
from seq2seq import Seq2Seq
def train_val_split(dataset, batch_size, num_workers, validation_split=0.2):
dataset_size = len(dataset)
indices = list(range(dataset_size))
split = int(np.floor(validation_split * dataset_size))
train_indices, val_indices = indices[split:], indices[:split]
train_sampler = SequentialSampler(train_indices)
valid_sampler = SequentialSampler(val_indices)
train_iter = DataLoader(dataset, sampler=train_sampler, batch_size=batch_size, num_workers=num_workers,
collate_fn=dataset.collate_fn)
valid_iter = DataLoader(dataset, sampler=valid_sampler, batch_size=batch_size, num_workers=num_workers,
collate_fn=dataset.collate_fn)
return train_iter, valid_iter
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.random.manual_seed(seed)
def train(opt):
set_seed(opt.seed)
batch_size, encoder_embedding_size, decoder_embedding_size, hidden_size, lr, epochs, device, logdir, \
batch_first, num_workers = \
opt.batch_size, opt.encoder_embedding_size, opt.decoder_embedding_size, \
opt.hidden_size, opt.lr, opt.epochs, opt.device, opt.logdir, opt.batch_first, opt.num_workers
en_tokenizer = Tokenizer(f"{opt.vocab}/en.vec", is_en=True)
ch_tokenizer = Tokenizer(f"{opt.vocab}/ch.vec", is_en=False)
dataset = MyDataset(f"{opt.vocab}/translate.csv", en_tokenizer, ch_tokenizer, nums=opt.nums,
batch_first=batch_first)
train_iter, val_iter = train_val_split(dataset, batch_size, num_workers)
if not os.path.exists(logdir):
os.mkdir(logdir)
temp = len(os.listdir(logdir))
save_dir = os.path.join(logdir, 'exp' + ('' if temp == 0 else str(temp)))
# 模型
model = Seq2Seq(encoder_embedding_size, hidden_size, en_tokenizer.length(), decoder_embedding_size, hidden_size,
ch_tokenizer.length(), en_tokenizer, ch_tokenizer, device=device, batch_first=batch_first,
dropout=0.1,
teacher_force_prob=opt.tp_prob,
teacher_force_gamma=opt.tp_gamma)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=opt.lr_gamma)
# 损失函数
cross_loss = nn.CrossEntropyLoss()
cross_loss.to(device)
# 绘制
writer = SummaryWriter(save_dir)
best_acc = .0
for e in range(epochs):
model.train()
for en_index, ch_index in tqdm(train_iter):
en_index = en_index.to(device)
ch_index = ch_index.to(device)
pred = model(en_index, ch_index[:, :-1] if batch_first else ch_index[-1], e)
label = (ch_index[:, 1:] if batch_first else ch_index[1:]).to(device)
loss = cross_loss(pred.reshape(-1, pred.shape[-1]), label.reshape(-1))
optimizer.zero_grad()
clip_grad_norm_(model.parameters(), opt.grad_clip)
loss.backward()
optimizer.step()
scheduler.step()
train_loss = loss.item()
model.eval()
val_acc, val_loss, n = .0, .0, 0
for en_index, ch_index in val_iter:
en_index = en_index.to(device)
ch_index = ch_index.to(device)
pred = model(en_index, ch_index[:, :-1] if batch_first else ch_index[-1], e)
label = (ch_index[:, 1:] if batch_first else ch_index[1:]).to(device)
loss = cross_loss(pred.reshape(-1, pred.shape[-1]), label.reshape(-1))
val_acc += torch.sum(pred.argmax(dim=-1) == label)
val_loss += loss.item()
n += label.shape[0] * label.shape[1]
val_acc /= n
val_loss /= n
writer.add_scalar('x/lr', optimizer.state_dict()['param_groups'][0]['lr'], e)
writer.add_scalar("train/loss", train_loss, e)
writer.add_scalar("val/loss", val_loss, e)
writer.add_scalar("val/acc", val_acc, e)
print(f"epoch {e} train loss {loss.item()} val loss {val_loss} val acc {val_acc}")
# 保存模型
if val_acc > best_acc:
if not os.path.exists(os.path.join(save_dir, 'weights')):
os.makedirs(os.path.join(save_dir, 'weights'))
torch.save(model, os.path.join(save_dir, "weights/best.pt"))
torch.save(model, os.path.join(save_dir, "weights/last.pt"))
writer.close()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--device', default="cuda:0" if torch.cuda.is_available() else "cpu")
# network structure
parser.add_argument('--encoder_embedding_size', default=128, type=int)
parser.add_argument('--decoder_embedding_size', default=128, type=int)
parser.add_argument('--hidden_size', default=256, type=int)
# hyper-parameters
parser.add_argument('--batch-size', default=32, type=int)
parser.add_argument('--lr', default=2e-3, type=float)
parser.add_argument('--lr_gamma', default=0.99, type=float)
parser.add_argument('--grad_clip', type=int, default=1)
# other config
parser.add_argument('--epochs', default=100, type=int)
parser.add_argument('--seed', default=42, type=int)
parser.add_argument('--batch_first', default=True, type=bool)
parser.add_argument('--vocab', default='datas')
parser.add_argument('--logdir', default='runs', type=str)
parser.add_argument('--num_workers', default=4, type=int)
parser.add_argument('--nums', default=None, type=int)
opt = parser.parse_args()
train(opt)