深入理解pytorch分布式并行处理工具DDP——从工程实战中的bug说起
近期博主在使用分布式并行处理工具DDP(DistributedDataParallel)训练单目深度估计模型Featdepth(源码地址:https://github.com/sconlyshootery/FeatDepth)时遇到了bug:

原因很容易定位出来:
在3D投影模块有以下代码:
class Backproject(nn.Module):
def __init__(self, batch_size, height, width):
super(Backproject, self).__init__()
self.batch_size = batch_size
self.height = height
self.width = width
meshgrid = np.meshgrid(range(self.width), range(self.height), indexing='xy')
self.id_coords = np.stack(meshgrid, axis=0).astype(np.float32)
self.id_coords = torch.from_numpy(self.id_coords)
self.ones = torch.ones(self.batch_size, 1, self.height * self.width)
self.pix_coords = torch.unsqueeze(torch.stack([self.id_coords[0].view(-1), self.id_coords[1].view(-1)], 0), 0)
self.pix_coords = self.pix_coords.repeat(batch_size, 1, 1)
self.pix_coords = torch.cat([self.pix_coords, self.ones], 1)
def forward(self, depth, inv_K):
cam_points = torch.matmul(inv_K[:, :3, :3], self.pix_coords.cuda())
cam_points = depth.view(self.batch_size, 1, -1) * cam_points
cam_points = torch.cat([cam_points, self.ones.cuda()], 1)
return cam_points
从这段代码可知,self.pix_coords,cam_points的第一个维度大小写死为self.batch_size(假设为4),这个是在配置文件中设定的,而此模块的输入张量depth由报错可知第一个维度大小为1(输入图片大小为512*1280=655360),所以这两个张量无法相乘。但从代码逻辑中来看,depth张量是由输入张量经过depth网络得到的,第一个维度应该与输入张量相同,也应该为batch_size,为什么变成1了呢?
经过一番定位,终于发现问题出在DDP的使用上。以下为DDP源码的注释:
This container parallelizes the application of the given module by
splitting the input across the specified devices by chunking in the batch
dimension. The module is replicated on each machine and each device, and
each such replica handles a portion of the input. During the backwards
pass, gradients from each node are averaged.
注释中说,本容器可以将输入数据在batch维度平均分配到各个设备上(数据并行),把模型在每个设备上复制一份(模型并行),每个模型副本负责处理一部分输入数据,在反向传播中,每个节点的梯度将被平均。
源码中还有这一句:
if device_ids is None:
device_ids = list(range(torch.cuda.device_count()))
看到这里就明白了,如果device_ids这个参数没有设置,DDP的device将默认设为所有可见的GPU,模型的输入数据也将在batch维度被平均分割,我的batch_size设为4,而可用的GPU有8个,所以部分GPU分到了batch_size为1的数据,部分GPU被闲置。
解决这个问题很简单,将源代码中对模型的包装:
model = MMDistributedDataParallel(model.cuda())
修改为:
model = MMDistributedDataParallel(model.cuda(), device_ids=[local_rank], find_unused_parameters=True)
这里的local_rank代表本进程中使用的GPU编号,在开启进程中指定,这里在torch.distributed.launch.py代码中将local_rank作为参数传入了每个进程:
for local_rank in range(0, args.nproc_per_node):
cmd = [sys.executable,
"-u",
args.training_script,
"--local_rank={}".format(local_rank)] + args.training_script_args
这样即指定了device_id只为本进程对应的GPU编号,输入数据不会被平均分配到每个GPU。
find_unused_parameters参数代表模型中存在不参与梯度更新的参数,不设置也会导致出错。
而在每个进程开始时,还要使用:
torch.cuda.set_device(local_rank)
指定本进程所有数据和模型都放在对应编号的GPU上。之所以这两个地方都要设置,是因为set_device()方法在官方文档中不推荐,因为优先级比较低,假如模型的device_id被默认设置为所有的GPU,set_device即失效。但如果不用set_device,无法保证进程中的所有张量都放在相应的GPU上,会导致0号GPU内存不足。当然还可以在进程中指定可见的GPU:
os.environ['CUDA_VISABLE_DEVICES'] = local_rank
这个环境变量优先级较高,可以直接指定进程中使用的GPU。
其实这个问题的本质原因在于,多进程和多GPU之间并没有一定的关联性,多进程默认在cpu上开启,需要手动设置到GPU上,所以可以单进程多GPU,也可以多进程单GPU,具体怎么使用也需要我们手动来指定,而DDP只是一个在多进程中复制模型和分发数据的工具,具体要分发和复制到哪些GPU上,需要我们来指定。
从这个实例深入挖掘,可以进一步加深对DDP的理解。如果没有接触过DDP,可以参照以下博客(上中下三篇)介绍得更加详细:
https://zhuanlan.zhihu.com/p/178402798
本文主要对DDP一些比较重要的点和实际使用中遇到的问题进行简要总结:
一、DDP的基本步骤以及与DP的比较
DP(DataParallel)是比较容易使用的,单进程多线程的多卡处理工具,只需要一行代码:
wrapped_net = torch.nn.DataParallel(net, device_ids=YOUR_CUDA_DEVICES)
即可完成模型的包装,其他的使用与单卡一致。因为只有一个进程,也不需要手动开启多进程,输入数据在多卡中的分发(scatter)与收集(gather)、模型的复制也是在DP中自动进行,可以说整个应用就是傻瓜式的,非常方便。但由于DP默认将0号GPU作为主GPU,数据的收集和梯度的同步都在主GPU上进行,所有的GPU都要与0号GPU通信,会导致传输效率较低,负载不均衡。
DDP(DistributedDataParallel)看名字多了个分布式,即代表它是利用了多进程分布式处理,每个GPU可以在独立进程中并行处理,避免了GIL(python的全局解释器锁)的影响,同时还用了ring-reduce的思想,即所有的GPU连成一个环,每个GPU只需要与上下游GPU通信,循环两次即可获取全局信息,解决了负载不均衡和通信效率低的缺点。
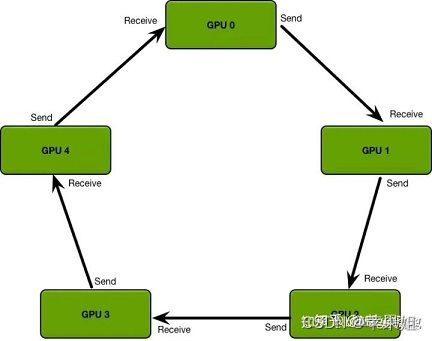
但DDP使用起来就有些复杂,主要包括以下基本步骤:
- 开启多进程,可以使用torch.distributed.launch.py开启,也可以用torch.multiprocessing.spawn开启,每个进程需要分配一个rank,范围是0~GPU数量-1
- 用dist.init_process_group进行多进程初始化,指定backend,一般为nccl
- 用torch.cuda.set_device(rank)设定当前进程使用的GPU
- 使用DistributedSampler根据rank对每个进程的输入数据进行分配:self.train_sampler = DistributedSampler(train_dataset),并作为参数传给data_loader。不同于DP在单进程多线程中的自动分配,这一步是为每个进程分配不同的数据
- 使用DDP对模型进行包装:model = MMDistributedDataParallel(model.cuda(), device_ids=[rank], find_unused_parameters=True)
二、DDP的核心功能:分发、收集和全局梯度更新机制的实现
DDP的主要代码在forward函数中:
def forward(self, *inputs, **kwargs):
if self.require_forward_param_sync:
self._sync_params()
if self.device_ids:
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
if len(self.device_ids) == 1:
output = self.module(*inputs[0], **kwargs[0])
else:
outputs = self.parallel_apply(self._module_copies[:len(inputs)], inputs, kwargs)
output = self.gather(outputs, self.output_device)
else:
output = self.module(*inputs, **kwargs)
if torch.is_grad_enabled() and self.require_backward_grad_sync:
self.require_forward_param_sync = True
if self.find_unused_parameters:
self.reducer.prepare_for_backward(list(_find_tensors(output)))
else:
self.reducer.prepare_for_backward([])
else:
self.require_forward_param_sync = False
return output
代码的前半段使用scatter、gather两个函数实现了输入数据的分发与归集,用parallel_apply函数实现了多个模型副本的并行处理。这一步类似于DP,及单进程多卡。假如我们设置device_id只有一个GPU,即不进行这些处理。
后半段是将准备全局同步梯度的参数注册到了reducer中,reducer在DDP初始化的时候进行了定义:(具体代码是C++代码)
self.reducer = dist.Reducer(
parameters,
list(reversed(bucket_indices)),
self.process_group,
expect_sparse_gradient)
DDP最核心的部分就是梯度的全局同步,也就是reduce机制。这部分代码是C++写的,python工程中看不到,而且位置也比较隐晦,因为pytorch源码中使用了hook(钩子)机制。hook机制简单的说就是把所有额外的功能和主程序解耦,用调用hook类中以位置命名的函数(如before_train_iter(), after_train_epoch()等)实现需要的额外功能,如在每次训练迭代之前执行call_hook(‘before_train_iter’)。
DDP的reduce机制就是通过hook接口调用的。在forward函数中注册需要梯度同步的参数,同时也是注册好了梯步同步的hook(在上文的 dist.Reducer中完成注册),注册hook的代码如下:(位置在torch.tensor.Tensor)
def register_hook(self, hook):
if not self.requires_grad:
raise RuntimeError("cannot register a hook on a tensor that "
"doesn't require gradient")
if self._backward_hooks is None:
self._backward_hooks = OrderedDict()
if self.grad_fn is not None:
self.grad_fn._register_hook_dict(self)
handle = hooks.RemovableHandle(self._backward_hooks)
self._backward_hooks[handle.id] = hook
return handle
这个函数将hook注册在tensor执行backward()函数的后面。在主程序执行到loss.backward()步骤时,所有参与梯度同步的参数将执行全局梯度同步,默认是梯度平均操作,即将所有卡上的梯度值进行平均,用平均值更新所有参数。只要保证参数的初始值一致(一般参数初始化方法都可以保证),即可保证参数在各个GPU上的状态时刻保持一致。
模型的参数不仅包括parameters,还包括buffer(不参与反向传播的参数),每次网络传播开始前,DDP也会将buffer广播给其他节点,保持buffer的全局一致。
三、DDP使用中的其他问题:loss全局平均、全局同步BN(SyncBN)、数据shuffle、模型保存和加载
1.loss的全局平均
我们在监测训练过程时,最主要的指标就是loss。但使用DDP后,由于DDP只自动执行了梯度的全局同步,并没有对loss进行全局同步,所以只能看到单卡的loss,能不能看到全局平均loss呢?当然是可以的。DDP除了自动执行梯度全局同步,也提供了手动的reduce接口:
def all_reduce(tensor,
op=ReduceOp.SUM,
group=group.WORLD,
async_op=False):
"""
Reduces the tensor data across all machines in such a way that all get
the final result.
这个函数可以对任意tensor实现全局同步功能,可以通过torch.distributed.all_reduce()调用,默认是实现全局相加,可以手动变成平均。可以在每次打印loss前手动调用all_reduce实现loss的全局平均:
dist.all_reduce(loss.div_(torch.cuda.device_count()))
这一步骤可以在打印训练集和验证集loss前都使用,就可以都看到全局平均的loss了。而且除了reduce,DDP手动的scatter/gather/broadcast接口也是提供的。
2.全局同步BN(SyncBN)
使用BN(batch normalization)的好处是:训练时在网络内部进行了归一化,为训练过程提供了正则化,防止了中间层feature map的协方差偏移,有助于抑制过拟合。使用BN,不需要特别依赖于初始化参数,可以使用较大的学习率,因此可以加速模型的训练过程。
SyncBN可以在多卡模式下支持全局同步moving mean和moving variance这两个buffer,并且是在DDP中完美支持的,使用方法是只要在使用DDP前机上一行代码即可完成。
# DDP init
dist.init_process_group(backend='nccl')
# 按照原来的方式定义模型,这里的BN都使用普通BN就行了。
model = MyModel()
# 引入SyncBN,这句代码,会将普通BN替换成SyncBN。
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
# 构造DDP模型
model = DDP(model, device_ids=[local_rank], output_device=local_rank)
3.数据shuffle
DDP使用中需要注意的另一个问题是每个epoch开始前最好进行一次数据重排(shuffle)。因为假如不做shuffle,每个epoch加载数据的顺序都是一样的,不利于训练的随机性和鲁棒性。实现方式是在每个epoch执行前加一句:
trainloader.sampler.set_epoch(epoch)
这一步在sampler内部将epoch作为随机数种子,对数据进行了重排。
4.模型保存与加载
模型保存:由于使用DDP后,模型在每个GPU上都复制了一份,而且被包装了一层,所以只需要保存master节点的模型,并且本来的model变成了现在的model.module,在保存模型时要这样操作:
if dist.get_rank() == 0:
torch.save(model.module.state_dict(), "%d.ckpt" % epoch)
而在加载的时候只需要在构造DDP模型之前,在master节点上加载:
if dist.get_rank() == 0 and ckpt_path is not None:
model.load_state_dict(torch.load(ckpt_path))
以上为博主对DDP使用上的一些理解,如有不足欢迎指正。
了解更多计算机视觉、深度估计和python/pytorch方面的知识,欢迎关注本专栏。以下为featdepth模型在DDP使用中的具体调整:
苹果姐:单目深度估计模型Featdepth实战中的问题和拓展