利用pandas对数据集PM2.5 Data of Five Chinese Cites进行清洗
1.项目介绍
最近在b站看到了一个数据清洗的小项目,来自于b站的同济子豪兄的一个视频,中国五城市六年PM2.5大数据可视化。介绍了中国五个城市的PM2.5的数据,以及一些天气数据,利用数据清洗和可视化对原数据集进行处理,从而挖掘出数据之间的关系,找到PM2.5和哪些因数有关,方便制作出相关策略应对治理PM2.5。
但是子豪兄的视频并没有给出如何进行数据清洗的过程,而是非常方便的把处理好的数据给了我们,如果利用excel的相关函数,也可以进行数据清洗。
但是最近正好又在学习机器学习的相关知识,这让我想到了可以利用pandas进行数据清洗,Pandas是基于NumPy的一个开源 Python 库,它被广泛用于快速分析数据。
2. 数据清洗代码
原始数据集下载地址:PM2.5 Data of Five Chinese Cities
这是kaggle官网上面下载的。
import pandas as pd
# 设置读取文件路径
data_path = ["D:\\study-project\\bigdata_pm2.5(11.23)\\BeijingPM20100101_20151231.csv",
"D:\\study-project\\bigdata_pm2.5(11.23)\\ShanghaiPM20100101_20151231.csv",
"D:\\study-project\\bigdata_pm2.5(11.23)\\GuangzhouPM20100101_20151231.csv",
"D:\\study-project\\bigdata_pm2.5(11.23)\\ChengduPM20100101_20151231.csv",
"D:\\study-project\\bigdata_pm2.5(11.23)\\ShenyangPM20100101_20151231.csv"
]
# 对北京的数据集进行清洗
# 读取数据
data1 = pd.read_csv(data_path[0])
# 对缺失值进行填充,即将缺失值填充汉字”缺失“
data1 = data1.fillna("缺失")
# 更改列名
data1 = data1.rename(columns = {'season': '季节' ,
'No' : "数据号",
'PM_Dongsihuan' : "PM2.5测点1数据",
'PM_Nongzhanguan' : "PM2.5测点2数据",
'PM_US Post' : "PM2.5测点3数据",
'DEWP' : "露点(摄氏度)",
'HUMI' : "相对湿度(摄氏度)" ,
'PRES' : "大气压(hPa)",
'TEMP' : "温度(摄氏度)",
'cbwd' : "风向",
'Iws' : "累计风速",
'precipitation' : "小时降水",
'Iprec' : "累计降水"
})
# 添加列名 城市
data1 = data1.assign(城市 = "北京")
# 添加时间 并删除剩其他的时间列
data1['时间'] = pd.to_datetime(data1[{"year", "month", "day", "hour"}])
data1 = data1.drop(labels={'year','month','day','hour','PM_Dongsi'}, axis=1)
# 将时间列前移
mid = data1['时间'] # 取备采集时间的值
data1.pop('时间') # 删除备采集时间
data1.insert(1, '时间', mid) # 插入采集时间列
# 替换列中的元素
data1["风向"] = data1["风向"].replace("NW", "西北风")
data1["风向"] = data1["风向"].replace("cv", "风向不定")
data1["风向"] = data1["风向"].replace("NE", "东北风")
data1["风向"] = data1["风向"].replace("SE", "东南风")
data1["风向"] = data1["风向"].replace("SW", "西南风")
data1["季节"] = data1["季节"].replace(4, "冬")
data1["季节"] = data1["季节"].replace(3, "秋")
data1["季节"] = data1["季节"].replace(2, "夏")
data1["季节"] = data1["季节"].replace(1, "春")
data1
结果显示:
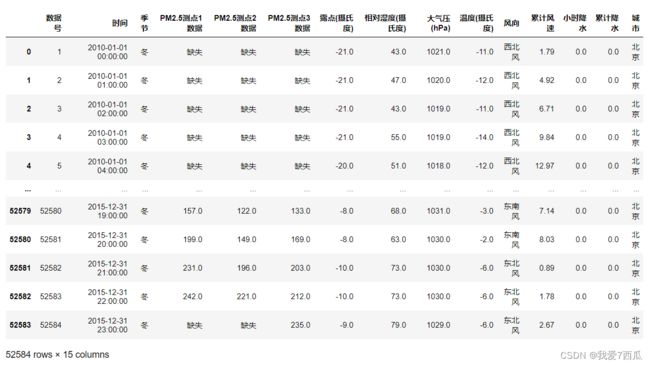
然后我们利用同样的方式进行对其他几个数据集进行处理最后再合并
3.数据集拼接
将其他处理好的数据集进行叠加在data1数据集上,也就是北京的数据集,最后导出
data1 = data1.append(data2, ignore_index = True)
data1 = data1.append(data3, ignore_index = True)
data1 = data1.append(data4, ignore_index = True)
data1 = data1.append(data5, ignore_index = True)
data1
# encoding='utf_8_sig'是为了防止导出的数据乱码
data1.to_csv('putout/北上广深PM2.5数据集.csv' ,encoding='utf_8_sig')
输出的数据集:
