机器学习 | 李宏毅课程笔记(二)深度学习任务攻略
【深度学习中的一些概念】
神经网络的结构:https://www.bilibili.com/video/BV1bx411M7Zx
梯度下降法(Gradient Descent):https://www.bilibili.com/video/BV1Ux411j7ri
反向传播:https://www.bilibili.com/video/BV16x411V7Qg
分段线性(piecewise linear):任何一段都是线性的分段函数,可以近似拟合任何曲线
独热向量(one-hot vector):向量中只有一个1,剩下都是0
激励函数(activate function):添加在每层网络后面,使网络可以拟合非线性函数,两个ReLU 神经元的线性叠加即可拟合博雷尔可测函数,采用ReLU的神经网络,对于拟合解决实际问题中常见的函数来说是绰绰有余了。
【为什么引入非线性激励函数?】
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。因此我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
【为什么引入Relu?】
- 采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
- 对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
注:此部分转自
机器学习的入门指南,李宏毅2021机器学习课程知识点框架(从深度学习开始了解机器学习) - 张梓寒 - 博客园
【深度学习任务攻略】
【深度学习模型训练的常见问题】

两种误差来源:Bias & Variance
Bias 即为模型的期望输出与其真实输出之间的差异;Variance 是指相同模型在不同数据上拟合得到的函数之间的离散程度,刻画了不同训练集得到的模型的输出与这些模型期望输出的差异。
模型越复杂,对数据越敏感,感知数据变化能力越强,Bias越小,Variance越大。
Underfitting (High Bias、Low Variance) & Overfitting (Low Bias、High Variance)
欠拟合是指模型在训练集、验证集和测试集上均表现不佳的情况;过拟合是指模型在训练集上表现很好,到了验证和测试阶段就大不如意了,即模型的泛化能力很差。
过拟合与欠拟合也可以用 Bias与Variance的角度来解释,欠拟合会导致高 Bias ,过拟合会导致高 Variance,所以模型需要在 Bias与Variance之间做出一个权衡。
若模型在训练集与测试集上误差均很大,则说明模型的 Bias很大,此时需要想办法处理 under-fitting ;若是训练误差与测试误差之间有个很大的 Gap ,则说明模型的 Variance 很大,这时需要想办法处理 over-fitting。
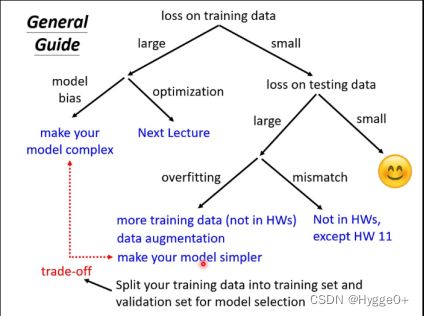
【为了提高预测结果的准确性,应该怎么做?】
- 检查Training Data的Loss
【Loss过大】——在训练资料上没有学好
可能原因1:Model Bias 模型过于简单,导致该模型可以描述的函数集中没有可以让Loss变的足够小的函数(海底捞针针不在海里)
解决方法:重新设计模型 增加输入特征或通过deep learning设计更复杂的模型,增加模型弹性(如利用sigmoid函数将线性变成非线性函数)
可能原因2:Optimization issue 在训练过程中可能卡到一个局部最优点(local minima)的地方,虽然网络中存在一个最好的函数,但是你无法找到让Loss最小的一组参数θ*。(海底捞针针在海里但没有办法找到它)
解决办法:next lecture【单独对Optimization issue展开陈述】
【预告:展开陈述Optimization为什么会失败以及如何解决时将引入类神经网络中的一些概念:局部最小值Local minima和鞍点Saddle point的概念,以及如何计算判断二者、如何根据计算Hessian进行下一步更新参数;引入batch与momentum...】
如何判断是Model Bias还是Optimization issue?
通过比较不同的模型。当一个神经网络的层数比另外一个神经网络要大,但Loss值却更大,则是Optimization issue,因为越深的网络的鲁棒性会更大;此外则是Model Bias。
[注:当Testing data上的误差大时,不一定是Overfitting。]
2.检查Testing Data的Loss
【Training Data Loss足够小,Testing Data Loss过大】
可能原因1:Overfitting
为什么会出现在训练数据上的误差很小,在测试数据上误差却很大呢?
[极端例子]通过训练找出一个这样的函数:当能够在训练资料中找到x的话就输出其真实值yi,否则就随机输出一个值。基于此,这个函数在training过程中的Loss为0,但是其什么都没有学到,所以在testing过程中的Loss会很大。
[真实实验]往往是因为model的鲁棒性太强,导致在training后得到的模型有很大的“自由区”而不能很好的拟合testing数据。

解决方法:增加训练资料,减少训练模型的自由区。More training data 、Data Augmentation(数据增强),如对图片进行随机旋转、平移、抖动、缩放等。限制模型的鲁棒性:如根据training的数据设定函数;更少的参数,共用参数;early stopping;Regularization;Droupout。但要注意的是不能给model太多的限制,否则会导致model bias的问题。
Model的复杂程度和Loss呈非线性关系。当model越来越复杂时,虽然Training loss越来越小,但是可能会出现over fitting的问题。

那么如何找到Training Loss和Testing Loss都很小的模型呢?
1.神经网络一共包含三个模块:训练模块、验证模块、预测模块。其中训练和验证模块共用Training data,把Training data分成训练数据和验证数据。当我们在每一个epoch训练后得到的θ参数和loss,我们要将θ进行验证,如果验证组得到的loss更小,说明这组参数是较优的,将此loss替换训练得到的loss,最终找到一组最优解。
2.N-fold Cross Validation N折交叉验证
将训练数据分为N份,N-1份作为训练数据,剩下1份作为验证数据。随机组合成多种情况。可将多个模型均在Training set的所有情况上进行训练,找到平均误差最小的模型。
可能原因2:Mismatch 训练资料和测试资料分布不一样,不是模型的问题。
解决方法:需要用到domain adaptation/transfer learning(后面会解释)