【读点论文】Conformer: Local Features Coupling Global Representations for Visual Recognition卷积提取局部,SA获取全局
Conformer: Local Features Coupling Global Representations for Visual Recognition
Abstract
-
在卷积神经网络(CNN)中,卷积运算善于提取局部特征,但难以捕获全局表示。在视觉transformer中,级联的自我关注模块可以捕获远距离的特征相关性,但不幸的是,会恶化局部特征细节。
-
在本文中,提出了一种称为Conformer的混合网络结构,以利用卷积运算和自关注机制来增强表示学习。Conformer源于特征耦合单元(FCU),它以交互方式融合不同分辨率下的局部特征和全局表示。Conformer采用并发结构,最大限度地保留了局部特征和全局表示。实验表明,在可比的参数复杂度下,Conformer在ImageNet上的性能优于视觉变换器(DeiT-B)2.3%。在MSCOCO上,它在对象检测和实例分割方面分别优于ResNet-101 3.7%和3.6%的mAP,显示了成为通用骨干网络的巨大潜力。
-
代码:pengzhiliang/Conformer: Official code for Conformer: Local Features Coupling Global Representations for Visual Recognition (github.com)
-
论文地址:[2105.03889] Conformer: Local Features Coupling Global Representations for Visual Recognition (arxiv.org)
-
本文是中国科学院大学联合鹏城实验室和华为提出了Conformer模型,将Transformer与CNN进行了融合。并且被ICCV2021录用,2021年最新文章。Conformer模型可以在不显著增加计算量的前提下显著提升了基网表征能力。
-
Conformer是CNN和Transformer第一个并行的混合网络,通过特征耦合模块FCU在每个阶段的局部特征和全局特征都会进行交互,使得Conformer兼具两者的优势。在分类上,以更小的参数和计算量取得更高的准确率,在目标和实例分割上也能一致地取得大幅度的提升。
-
在卷积神经网络(CNN)中,卷积运算擅长提取局部特征,但在捕获全局特征表示方面还是有一定的局限性。在Vision Transformer中,级联自注意力模块可以捕获长距离的特征依赖,但会忽略局部特征的细节。本文提出了一种混合网络结构,称为Conformer,以利用卷积操作和自注意力机制来增强特征表示的学习。Conformer依靠特征耦合单元(FCU),以交互的方式在不同分辨率下融合局部特征表示和全局特征表示。此外,Conformer采用并行结构,以最大限度地保留局部特征和全局表示。
-
提出的双网络结构Conformer,能够将基于CNN的局部特征与基于Transformer的全局表示相结合,以增强表示学习。Conformer由一个CNN分支和一个Transformer分支组成,这两个分支由局部卷积块、自我注意模块和MLP单元的组合而成。在训练过程中,交叉熵损失函数被用于监督CNN和Transformer两个分支的训练,以获得同时具备CNN风格和Transformer风格的特征。
-
考虑到CNN与Vision Transformer特征之间的不对称性,作者设计了特性耦合单元(FCU)作为CNN与Vision Transformer 之间的桥接。一方面,为了融合两种风格的特征,FCU利用1×1卷积对齐通道尺寸,用下/上采样策略对齐特征分辨率,用LayerNorm和BatchNorm对齐特征值 。另一方面,由于CNN和Vision Transformer分支倾向于捕获不同级别的特征(局部和全局),因此将FCU插入到每个block中,以 连续 交互的方式消除它们之间的语义差异 。这种融合过程可以极大地提高局部特征的全局感知能力和全局表示的局部细节。
Introduction
-
卷积神经网络(CNN)具有显著先进的计算机视觉任务,如图像分类、对象检测和实例分割。这在很大程度上归因于卷积运算,卷积运算以分层方式收集局部特征作为强大的图像表示。尽管在局部特征提取方面具有优势,但CNN在捕获全局表示(例如,视觉元素之间的长距离关系)方面遇到了困难,这对于高级计算机视觉任务通常是至关重要的。一个直观的解决方案是扩大接受野,但这可能需要更密集但破坏性的池化操作。
-
最近,transformer架构已被引入视觉任务。ViT方法通过将每个图像分割为具有位置嵌入的块来构造标记序列,并应用级联变换块来提取参数化向量作为视觉表示。由于自我注意机制和多层感知器(MLP)结构,视觉transformer反映了构成全局表示的复杂空间变换和远距离特征依赖。不幸的是,视觉transformer忽略了局部特征细节,这降低了背景和前景之间的可辨性,如下图(c)和(g)所示。
-

-
CNN(ResNet-101)、Visual Transformer(DeiT-S)和本文提出的的Conformer的特征图的比较。transformer中的贴片嵌入被重塑为用于可视化的特征图。
-
当CNN激活有区别的局部区域(例如,孔雀的头部在(a)和尾部在(e))时,Conformer的CNN分支利用来自视觉transformer的全局线索,从而激活完整的对象(例如,(b)和(f)中孔雀的全部范围)。
-
与CNN相比,视觉变换器的局部特征细节恶化(例如,(c)和(g))。相比之下,Conformer的transformer分支保留了来自CNN的局部特征细节,同时降低了背景(例如,(d)和(h)中的孔雀轮廓比(c)和(g)中的更完整)。(最佳彩色视图)
-
从上图可以看出,Conformer每个分支的特征表示都比单独使用CNN或者单独使用Transformer结构的特征表示要更好。传统的CNN倾向于保留可区分的局部区域,而Conformer的CNN分支还可以激活完整的物体范围。Vision Transformer的特征很难区分物体和背景,Conformer的分支对局部细节信息的捕获更好。
-
-
改进的视觉transformer提出了标记化模块或利用CNN特征图作为输入标记来捕获特征邻近信息。然而,如何将局部特征和全局表示精确地嵌入到彼此之间的问题仍然存在。
-
在本文中,提出了一种称为Conformer的双网络结构,旨在将基于CNN的局部特征与基于transformer的全局表示相结合,以增强表示学习。Conformer由CNN分支和transformer分支组成,它们分别遵循ResNet和ViT的设计。这两个分支形成了局部卷积块、自我关注模块和MLP单元的综合组合。在训练期间,交叉熵损失用于监督CNN和transformer分支,以耦合CNN风格和transformer风格的特征。
-
考虑到CNN和transformer特征之间的特征未对准,特征耦合单元(FCU)被设计为桥。一方面,为了融合两种风格的特征,FCU利用1×1卷积来对齐通道尺寸,利用下/上采样策略来对齐特征分辨率,利用LayerNorm和BatchNorm来对齐特征值。另一方面,由于CNN和transformer分支倾向于捕获不同级别的特征(例如,本地与全局),因此FCU被插入到每个块中,以交互方式连续消除它们之间的语义差异。这种融合过程可以大大增强局部特征的全局感知能力和全局表示的局部细节。
-
Conformer在耦合局部特征和全局表示方面的能力如上图所示。虽然传统CNN(例如ResNet-101)倾向于保留有区别的局部区域(例如孔雀的头部或尾部),但Conformer的CNN分支可以激活整个对象范围,如上图(b)和(f)所示。当仅使用视觉transformer时,对于弱的局部特征(例如,模糊的对象边界),很难将对象与背景区分开来,图(c)和(g)。局部特征和全局表示的耦合显著增强了基于transformer的特征的可辨性,上图(d)和(h)。
-
The contributions of this paper include:
-
本文提出了一种称为Conformer的双网络结构,它最大限度地保留了局部特征和全局表示。
-
提出了特征耦合单元(FCU),以交互方式将卷积局部特征与基于transformer的全局表示融合。
-
在可比的参数复杂度下,Conformer以显著优势优于CNN和视觉transformer。Conformer继承了CNN和视觉变换器的结构和泛化优势,展示了成为通用骨干网络的巨大潜力。
-
Related Work
-
具有Global Cues的CNN。在深度学习时代,CNN可以被视为具有不同接收场的局部特征的分层集成。不幸的是,大多数CNN擅长提取局部特征,但难以捕捉Global Cues。
-
为了缓解这种限制,一种解决方案是通过引入更深的架构和/或更多的池操作来定义更大的接受野[Squeeze-and-excitation networks,Gather-excite: Exploiting feature context in convolutional neural networks]。扩张卷积方法[Multi-scale context aggregation by dilated convolutions,Dilated residual networks]增加了采样步长,而可变形卷积[Deformable convolutional networks]学习了采样位置。
-
SENet和GENet建议使用全局平均池来聚合全局上下文,然后使用它来重新加权特征通道,而CBAM分别使用全局最大池和全局平均池在空间和通道维度上独立地细化特征。
-
另一个解决方案是全局注意力机制[Non-local neural networks,Gcnet,Attention augmented convolutional networks,Relation networks for object detection,Bottleneck transformers for visual recognition],它在捕获自然语言处理中的长距离依赖方面表现出了巨大的优势。受非局部均值方法的启发,以自关注的方式将非局部操作引入到CNN,使得每个位置的响应是所有(全局)位置的特征的加权和。
-
注意力增强卷积网络将卷积特征图与自注意力特征图连接起来,以增强卷积操作,以捕获长距离交互。Relation Networks提出了一种对象关注模块,该模块通过一组对象的外观特征和几何结构之间的交互来同时处理这些对象。
-
尽管取得了进展,但将global cues引入CNN的现有解决方案存在明显的缺点。于第一种解决方案,较大的感受野需要更密集的池化操作,这意味着较低的空间分辨率。对于第二种解决方案,如果卷积运算没有与注意机制正确融合,则局部特征细节可能会恶化。
-
Visual Transformers.
-
作为一项开创性的工作,ViT验证了用于计算机视觉任务的纯transformer架构的可行性。为了利用长距离依赖性,transformer块充当独立的架构,或被引入CNN用于图像分类、对象检测[End-to-end object detection with transformers,Deformable detr,Toward transformer-based object detection]、语义分割、图像增强和图像生成。
-
然而,视觉transformer中的自我注意机制经常忽略局部特征细节。为了解决这个问题,DeiT建议使用蒸馏标记将基于CNN的特征转移到视觉transformer,而T2TViT建议使用标记化模块递归地将图像重新组织为考虑相邻像素的标记。DETR方法将CNN提取的局部特征馈送到transformer编码器解码器,以串行方式建模特征之间的全局关系。
-
Conformer
Overview
-
局部特征和全局表示是重要的对应物,它们在视觉描述符的漫长历史中得到了广泛的研究。局部特征及其描述符是局部图像邻域的紧凑矢量表示,是许多计算机视觉算法的构建块。
-
全局表示包括但不限于轮廓表示、形状描述符和远距离对象类型。在深度学习时代,CNN通过卷积运算以分层方式收集局部特征,并将局部线索保留为特征图。视觉transformer被认为通过级联的自我关注模块以软方式聚合压缩补丁嵌入之间的全局表示。
-
为了利用局部特征和全局表示,本文设计了一个并发网络结构,如下图(c)所示,称为Conformer。考虑到这两种风格特征的互补性,在Conformer中,本文将全局上下文从transformer分支连续馈送到特征图,以增强CNN分支的全局感知能力。
-

-
建议的Conformer的网络架构。(a) 上采样和下采样用于特征图和斑块嵌入的空间对齐。(b) CNN块、transformer块和特征耦合单元(FCU)的实现细节。(c) Conformer的缩略图。
-
局部特征是局部图像邻域的紧凑向量表示,一直是许多计算机视觉算法的组成部分。全局表示包括轮廓表示、形状描述符和长距离上的对象表示等等。在深度学习中,CNN通过卷积操作分层收集局部特征,并保留局部线索作为特征。Vision Transformer被认为可以通过级联的Self-Attention模块以一种soft的方式在压缩的patch embedding之间聚合全局表示。
-
-
类似地,来自CNN分支的局部特征被逐步反馈到补丁嵌入,以丰富transformer分支的局部细节。这种过程构成了互动。
-
特别地,Conformer由一个主干模块、双分支、桥接双分支的FCU和用于双分支的两个分类器(一个fc层)组成。茎模块是一个7×7的卷积,步长为2,然后是3×3的最大池,步长2,用于提取初始局部特征(例如,边缘和纹理信息),然后将其馈送到双分支。
-
CNN分支和transformer分支分别由N个(例如,12个)重复卷积和transformer块组成,如下表所示。这样的并发结构意味着CNN和transformer分支可以分别最大限度地保留局部特征和全局表示。FCU被提议作为桥接模块,用于将CNN分支中的局部特征与transformer分支中的全局表示融合,上图(b)。FCU从第二个块应用,因为两个分支的初始化特征相同。沿着分支,FCU以交互方式逐步融合特征图和补丁嵌入。
-

-
Conformer-S的架构,其中MHSA-6表示transformer块中MHSA-6的多多头自关注,fc层在这里被视为1×1卷积。在FCU列中,箭头表示特征流。在输出列中,56×56197分别表示特征图的大小为56×56,嵌入的斑块数为197。
-
-
最后,对于CNN分支,所有特征都被合并并馈送到一个分类器。对于transformer分支,类令牌被取出并馈送到另一个分类器。在训练期间,使用两个交叉熵损失来分别监督两个分类器。损失函数的重要性根据经验设定为相同。在推理过程中,两个分类器的输出被简单地概括为预测结果。
Network Structure
-
CNN Branch.
-
如上图(b)所示,CNN分支采用特征金字塔结构,其中特征图的分辨率随着网络深度而降低,而信道数则增加。将整个分支分为4个阶段,如上表(CNN分支)所述。每个阶段由多个卷积块组成,每个卷积块包含nc个瓶颈。根据ResNet中的定义,瓶颈包含1×1下投影卷积、3×3空间卷积、1×1上投影卷积以及瓶颈输入和输出之间的残余连接。在实验中,在第一个卷积块中将nc设置为1,并满足≥ 在随后的N中为2− 1个卷积块。
-
视觉transformer通过单个步骤将图像块投影到矢量中,导致局部细节丢失。在CNN中,卷积核在重叠的特征图上滑动,这提供了保留精细细节局部特征的可能性。因此,CNN分支能够连续地为transformer分支提供局部特征细节。
-
-
Transformer Branch
- 在ViT之后,该分支包含N个重复的transformer块。如上图(b)所示,每个transformer块包括一个多头自关注模块和一个MLP块(包括一个上投影fc层和一个下投影fc层)。在自关注层和MLP块中的每个层和残差连接之前应用层规范。对于标记化,通过线性投影层将由stem模块生成的特征图压缩为14×14个无重叠的块嵌入,该线性投影层是步长为4的4×4卷积。然后将类标记伪装为块嵌入进行分类。考虑到CNN分支(3×3卷积)编码局部特征和空间位置信息,不再需要位置嵌入。这有助于提高下游视觉任务的图像分辨率。
-
Feature Coupling Unit.
-
鉴于CNN分支中的特征图和transformer分支中的补丁嵌入,如何消除它们之间的不对准是一个重要问题。为了解决这个问题,本文建议FCU以交互方式将局部特征与全局表示连续耦合。
-
一方面,必须意识到CNN和transformer的特征维度是不一致的。CNN特征图的维度为C×H×W(C、H、W分别为通道、高度和宽度),而块嵌入的形状为(K+1)×E,其中K、1和E分别表示图像块的数量、类标记和嵌入维度。当馈送到transformer分支时,特征图首先需要通过1×1卷积,以对齐贴片嵌入的通道编号。然后使用下采样模块(上图(A))完成空间维度对齐。
-
最后,如上图(b)所示,特征图添加了补丁嵌入。当从transformer分支反馈到CNN分支时,需要对贴片嵌入进行上采样(上图(a))以对齐空间尺度。然后通过1×1卷积将信道维度与CNN特征图的信道维度对齐,并添加到特征图中。同时,LayerNorm和BatchNorm模块用于正则化特征。
-
另一方面,特征图和补丁嵌入之间存在显著的语义差距,即,特征图是从局部卷积算子中收集的,而补丁嵌入是用全局自关注机制聚合的。因此,FCU应用于每个块(第一块除外),以逐步填补语义空白。
-
Analysis and Discussion
-
Structure Analysis.
-
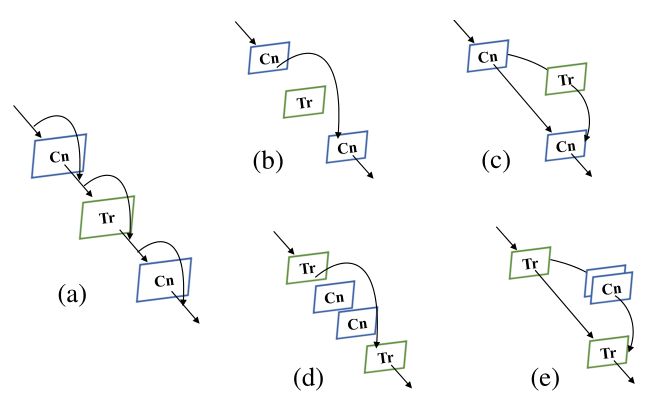
通过将FCU视为短连接,我们可以将所提出的对偶结构抽象为特殊的串行残差结构,如下图(a)所示。在不同的残差连接单元下,Conformer可以实现瓶颈(如ResNet,下图(b))和transformer块(如ViT,下图))的不同深度组合,这意味着Conformer继承了CNN和视觉transformer的结构优势。此外,它实现了不同深度的瓶颈和变压器块的不同排列,包括但不限于下图(c)和(e)。这大大增强了网络的表示能力。
-
-
结构分析。Cn和Tr分别表示瓶颈和变压器块。(a) 对偶结构可以被认为是残差结构的一种特殊序列情况。(b) CNN(例如ResNet);(c) 一种特殊的混合结构,其中transformer块嵌入瓶颈。(d) 视觉transformer(例如ViT);(e) 瓶颈嵌入transformer块的特殊情况。
-
-
Feature Analysis.
-
本文将上文第一张图中的特征图、下图中的类激活图和注意力图可视化。与ResNet相比,通过耦合的全局表示,Conformer的CNN分支倾向于激活更大的区域而不是局部区域,这表明了增强的长距离特征依赖性,这在上文图(f)和下图(a)中得到了显著证明。由于CNN分支逐步提供的精细细节局部特征,Conformer中transformer分支的补丁嵌入保留了重要的细节局部特征(上文图(d)和(h)),这些特征会因视觉transformer而恶化(上文图)(c)和(g))。此外,下图(b)中的注意力区域更完整,而背景被显著抑制,这意味着Conformer对学习特征表示的识别能力更高。
-

-
特征分析。(a) 通过使用CAM方法在ResNet-101和Conformer-S的CNN分支中进行类激活映射。(b) 通过使用注意力滚动方法,在DeiT-S和Conformer-S的transformer分支中进行注意力映射。(最佳彩色视图)
-
Experiments
Model Variants
- 通过调整CNN和transformer分支的参数,本文得到了分别称为ConformerTi、-S和-B的模型变量。Conformer-S的详细信息见上文表。Conformer-S/32将特征图拆分为7×7个补丁,即transformer分支中的补丁大小为32×32。
Image Classification
-
Experimental Setting.
-
Conformer在ImageNet-1k训练集上用1.3M张图像进行训练,并在验证集上进行测试。下表中报告了Top-1精度。为了使transformer收敛到合理的性能,遵循DeiT中的数据增强和正则化技术。这些技术包括Mixup、CutMix、Erasing、RandAugment和随机深度)。使用AdamW优化器对模型进行了300个epoch的训练,批大小为1024,权重衰减为0.05。初始学习率设置为0.001,并在余弦计划中衰减。
-
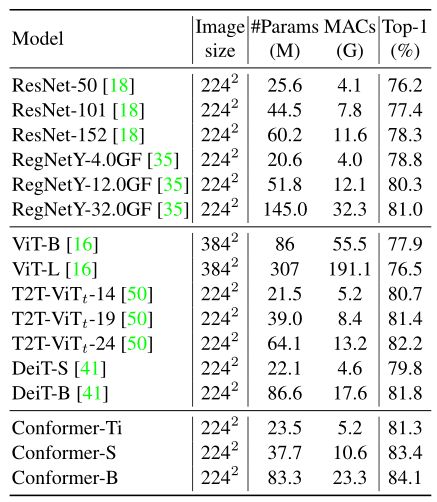
-
ImageNet验证集上图像分类的最高精度。
-
-
Performance.
- 在类似的参数和计算预算下,上表,Conformers的表现优于CNN和视觉transformer。例如,Conformer-S(具有37.7M参数和10.6G MAC)的性能分别优于ResNet-152(具有60.2M参数和11.6G MAC的性能)4.1%(83.4%对78.3%)和DeiT-B(具有86.6M参数和17.6G MAC的性能)1.6%(83.4%对。81.8%). Conformer-B具有可比的参数和适中的MAC成本,其性能优于DeiT-B 2.3%(84.1%对81.8%)。除了卓越的性能,Conformer比视觉transformer收敛得更快。
Object Detection and Instance Segmentation
-
为了验证Conformer的通用性,本文在MSCOCO数据集上对实例级任务(例如,对象检测)和像素级任务(如,实例分割)进行了测试。Conformer作为主干,在不需要额外设计的情况下进行迁移,相对精度和参数比较见下表。通过CNN分支,可以使用[c2,c3,c4,c5]的输出特征图作为侧输出来构建特征金字塔。
-
Experimental Setting.
- 按照惯例,模型在MSCOCO训练集上进行训练,并在MSCOCO minival集上进行测试。在下表中,我们报告了APbbox(APsegm)、APbboxS(APsegm S)、APbboxM(APsemm M)和APbboxL(APsem L),分别为IoU阈值上的平均值、盒子的小、中、大对象(掩模)。除非明确规定,否则使用批次大小32,学习率为0.0002,优化器AdamW,权重衰减为0.0001,最大epoch为12。学习率在第8个和第11个epoch衰减一个量级。
-
Performance.
-
如下表所示,Conformer显著增强了APbbox和APsegm。对于物体检测,Conformer-S/32的mAP(55.4 M和288.4 GFLOP)比FPN基线(ResNet-101、60.5 M和295.7 GFLOPs)高3.7%。例如,分割,Conformer-S/32的mAP(58.1M和341.4 GFLOP)比Mask R-CNN基线(ResNet-101、63.2 M和348.8 GFLOPs)高3.6%。这证明了全局表示对于高级任务的重要性,并表明Conformer作为通用骨干网络的巨大潜力。
-

-
MSCOCO最小集上的对象检测和实例分割性能。†意味着结果由mmdetection库报告。
-
Ablation Studies
-
Number of Parameters.
-
建议的Conformer的参数是CNN和transformer分支的组合。两个分支的参数比例是一个有待实验确定的超参数。在下表中,评估了两个分支在不同参数设置下的性能。对于CNN分支,通过改变通道和瓶颈的数量来调整CNN分支的参数,这些通道和瓶颈分别控制CNN分支宽度和深度。对于transformer分支,通过改变嵌入尺寸和头的数量来调整参数。从下表可以看出,通过增加CNN或transformer支路的参数可以提高精度。更多的CNN参数带来更大的改进,同时计算成本开销更低。
-
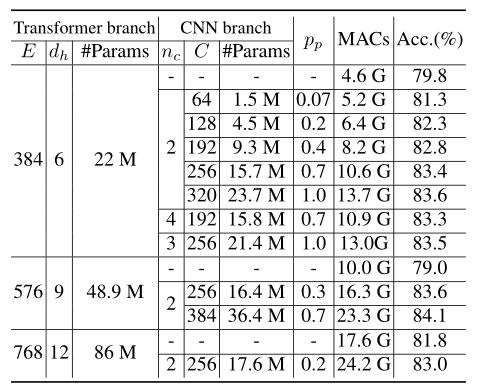
-
不同参数比例下的性能。E和dh分别表示transformer分支中的多头关注模块中的嵌入尺寸和头部。C和nc分别表示CNN分支中每个卷积块内的信道c2和瓶颈数。pp是CNN(包括主干和FCU)和transformer支路参数的比例
-
-
Dual Structure.
-
Conformer是一种双模式,与串行混合ViT完全不同(CNN→ transformer)。在下表中,ResNet-26/50d和DeiT-S是一个混合模型,由ResNet-26/50d和DeiT-S组成,其中DeiT-S在ResNet-25/50d提取的特征图上形成标记。尽管ResNet-26/50d可以在茎段内保留更多的局部信息,但Conformer-S/32在相当的计算成本开销下优于串行混合模型。
-

-
混合结构的比较。DeiT-S/32表示DeiT-S模型的补丁大小为32×32。ResNet26/50d是ResNet-26/50的变体,其主干模块由三个3×3卷积组成。
-
-
Positional Embeddings.
-
考虑到CNN分支(3×3卷积)对局部特征和空间位置信息进行编码,假定Conformer不再需要位置嵌入。在下表中,当去除位置嵌入时,DeiT-S的精度下降2.4%,而Conformer-S的精度略有下降(0.1%)。
-

-
位置嵌入策略的比较。“Pos. Embeds”是“learnable positional embeddings”的缩写。
-
-
Sampling Strategies.
-
在FCU中,为了使基于CNN的特征图与基于Transformer的补丁嵌入耦合,使用上/下采样操作来对齐空间尺度。在下表中,比较了不同的上/下采样策略,包括Maxpooling、Avgpooling、卷积和基于注意力的采样。与Max/Avgpooling采样相比,卷积和基于注意力的采样方法使用了更多的参数和计算成本,但实现了相当的精度。因此,选择Avgpooling策略。
-
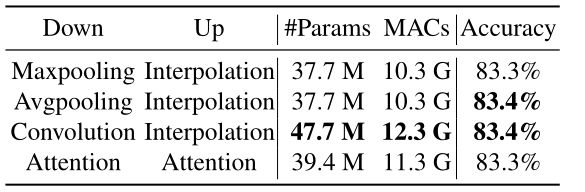
-
抽样策略的比较。使用最近邻插值。
-
-
Comparison with Ensemble Models.
-
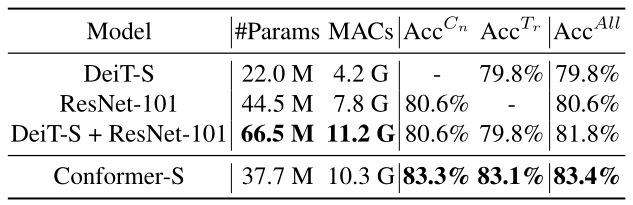
Conformer与结合CNN和transformer输出的集成模型进行了比较。为了公平比较,本文使用相同的数据增强和正则化策略以及相同的训练epoch(300)来训练ResNet-101,并将其与DeiT-S模型相结合以形成集成模型,并在下表中报告了准确性。CNN分支、transformer分支和Conformer-S的准确性分别达到83.3%、83.1%和83.4%。相比之下,集成模型(DeiT-S+ResNet-101)的存档率为81.8%,比Conformer-S(83.4%)低1.6%,尽管它使用了更多的参数和MAC。
-
-
集成模型的性能比较。AccCn和AccTr分别表示CNN和transformer分支的精度。
-
Generalization Capability
-
Rotation Invariance.
-
为了验证模型在旋转方面的泛化能力,将测试图像旋转0◦, 60◦, 120◦, 180◦, 240◦ 和300◦ 并评估在相同数据增强设置下训练的模型的性能。如下图(a)所示,所有模型都报告了无旋转(0◦). 对于旋转的测试图像,ResNet-101的性能显著下降。相比之下,Conformer-S报告了更高的性能,这意味着更强的旋转不变性。
-
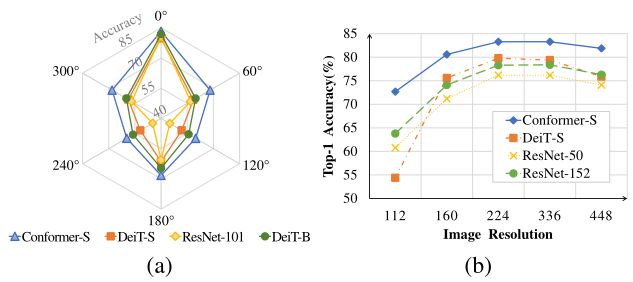
-
泛化能力。(a) 旋转不变性的比较。比较的模型在相同的数据增强设置下进行训练,并直接在旋转图像上进行评估,而无需模型微调。(b) 尺度不变性的比较。在分辨率为224×224的图像上训练模型,并在不进行模型微调的情况下在不同的图像分辨率上进行测试。
-
-
Scale Invariance.
- 在上图(b)中,本文比较了Conformer与视觉transformer(DeiT-S)和CNN(ResNet)的尺度适应能力。对DeiT-S的位置嵌入进行插值,以使其在推断过程中适应不同分辨率的输入图像。当输入图像的大小从224减少到112时,DeiT-S的性能下降25%,ResNet-50/152的性能下降15%。相比之下,Conformer的性能仅下降了10%,这表明学习的特征表示具有更高的尺度不变性。
Conclusion
- 本文提出Conformer,这是第一个将CNN与视觉transformer相结合的双主干。在Conformer中,利用卷积算子来提取局部特征,并利用自关注机制来捕获全局表示。设计了特征耦合单元(FCU),以融合局部特征和全局表示,以交互方式增强视觉表示的能力。实验表明,具有可比参数和计算预算的Conformer优于传统CNN和视觉transformer,与现有技术形成了鲜明对比。在下游任务上,Conformer显示出成为一个简单而有效的骨干网络的巨大潜力。
A. Model Architectures
-
Conformer Ti/B的架构如下表所示。与Conformer S相比,Conformer Ti将CNN分支的信道数减少了1/4,ConformerB将CNN支路的信道数、多头注意力模块的头数和transformer支路的嵌入尺寸增加了1.5。
-

-
CNNTransformer-Ti和CNNTransformer-B的结构,其中MHSA-6/9表示transformer块中MHSA-6/9的多头自关注,fc层在这里被视为1×1卷积。在输出列中,56×56,197分别表示特征图的大小为56×56,嵌入的斑块数为197。
-
B. Attention-based Sampling
-
本文还设计了一种基于特征图和补丁嵌入之间的交叉关注的下采样上采样策略。
-
设h、w和c分别表示块中特征图的高度、宽度和通道(为了简单起见,这里省略了批次维度),K和E分别表示变换器分支中的块嵌入数(称为Pt)和通道维度。将特征图分成K个斑块(例如,14×14),称为Pc。每个斑块的尺寸为n×c。通过1×1卷积对齐通道尺寸后,每个斑块的形状为n×e。
-
对于下采样,Pc中的斑块i(表示为P ic)和Pt中的斑块j(表示为Pj t)之间的融合公式为
-
P i j = P i j + S o f t m a x ( ( P t j W q ) ( P c i W k ) T E ) ( P c i W v ) , ( 1 ) P^j_i=P^j_i+Softmax(\frac{(P^j_tW_q)(P^i_cW_k)^T}{\sqrt{E}})(P^i_cW_v),(1) Pij=Pij+Softmax(E(PtjWq)(PciWk)T)(PciWv),(1)
-
其中Wq、Wk、Wv∈ RE×E是学习的线性变换,分别将输入Pj t映射到查询Q、键K和值V。
-
-
对于上采样,重复使用等式1中的注意力权重,并将过程公式化为
-
P c i ˉ = P c i ˉ + S o f t m a x ( ( P t j W q ) ( P c i W k ) T E ) ( P t j ) ˉ , ( 1 ) \bar{P^i_c}=\bar{P^i_c}+Softmax(\frac{(P^j_tW_q)(P^i_cW_k)^T}{\sqrt{E}})(\bar{P^j_t)},(1) Pciˉ=Pciˉ+Softmax(E(PtjWq)(PciWk)T)(Ptj)ˉ,(1)
-
其中~P ic和~P ic分别表示P ic由卷积层处理,P j t由transformer块处理。
-
C. Inference Time
-
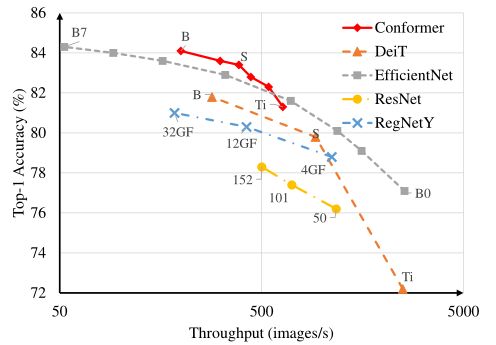
分类:在DeiT之后,本文评估并比较了下图中各种方法的吞吐量。可以看出,在可比吞吐量下,本文的Conformer优于EfficientNet。
-
-
与DeiT、ResNet、RegNetY和EfficientNet相比,Conformer在ImageNet上的吞吐量和准确性。吞吐量以32GB V100 GPU上每秒处理的图像数量来衡量。
-
-
Object detection and instance segmentation.
-
类似地,本文测量每秒帧数(FPS)作为推理速度,并在下表中进行了比较。结合本文中的表3和此处的下表,与ResNet-101相比,Conformer-S/32具有可比的参数、GFLOP和推理速度,但在对象检测和实例分割任务中都可以显著优于ResNet-101,这进一步证明了成为通用骨干网络的潜力。
-

-
推理时间比较。FPS是在批大小为1的32GB V100 GPU上测量的。
-
D. Residual Structure
-
如上图所示,通过将FCU视为短连接,将具有对偶结构的Conformer抽象为具有残差连接的串行结构。换句话说,在不同的残差连接下,Conformer可以退化为不同的子结构。我们测试了一些子结构,并在下表中报告了相应的性能。从下表可以看出,提出的残差结构优于其他子结构。
-
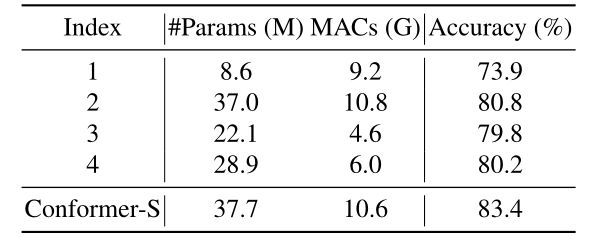
-
Conformer子结构的性能。其中索引1、2、3和4分别表示图[Structure analysis](b)、(c)、(d)和(e)。
-
E. Fusion Interval
-
在本文中,本文提出了一个特征耦合单元,用于交互每个块中的局部特征和全局表示,以逐步对齐特征以填补语义空白。为了验证是否应该在每个块中进行融合,对融合间隔进行了实验,并在下表中报告了ImageNet上的性能。从表11可以看出,较小的融合间隔报告了较高的性能,这意味着频繁的交互有助于表示学习。
-

-
融合间隔的比较。1、2和4分别表示每1、2、4个块执行融合。
-
F. Convergence speed
-
对于引入的卷积运算,下图,ConformerS的CNN分支和transformer分支在前50个epoch都显著优于DeiT。这证明了卷积的归纳偏差有助于视觉transformer的收敛。
-

-
Training Accuracy on the val set.
-