SETR:将transformers用于语义分割
论文地址:https://arxiv.org/abs/2012.15840
目录
0、摘要
1、引言
2、相关工作
3、方法
3.1、基于FCN的语义分割
3.2、SETR
3.3、Decoder的设计
(1)朴素上采样(Naive)
(2)渐进上采样(PUP)
(3)多级特征融合(MLA)
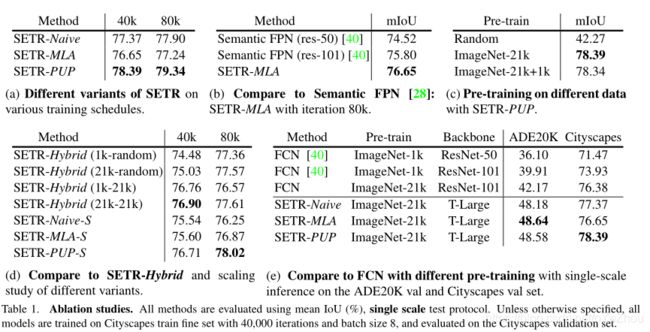
4、实验结果
5、总结
0、摘要
近期大多数语义分割模型都是基于带有Encoder-Decoder结构的FCN进行设计的。Encoder逐渐降低空间分辨率,同时利用逐渐变大的感受野学习到更为抽象的语义特征。鉴于上下文建模对语义分割的重要性,最新的一些研究聚焦于使用空洞卷积或者插入注意力模块来增大感受野这个方面。然而,这些研究仍然是基于Encoder-Decoder的FCNs架构的。本文的目的是通过将语义分割视为一个sequence-to-sequence的预测任务,提供一个可供选择的替代品。具体地,使用了一个纯粹的transformer结构(也即:没有卷积和下采样过程)将一张图像作为一组patchs进行编码。通过transformer中每一层所建模的全局上下文,Encoder即可接上一个简单的decoder,从而组合为一个强大的语义分割模型,该模型称为SETR。大量实验表明,SETR在ADE20K(50.28%mIOU)、 Pascal Context (55.83%mIoU)达到了新的SOTA,并在Cityscapes达到了有竞争力的结果,特别是在ADE20K测试服务器排行榜上位列第一,达到44.42% mIoU。
1、引言
自FCN之后,现有语义分割模型都是基于此进行的开发。一个标准的FCN语义分割模型是有着Encoder-Decoder结构的:encoder用于特征表示学习,decoder用于对特征表示进行像素级分类。这两者之间,特征表示学习(也即encoder)可以说是最重要的部分。encoder部分,正如大多CNNs的设计初衷是为了图像理解,其由大量的卷积层堆叠而成。在堆叠过程中,考虑到计算量,会逐渐降低feature maps的空间分辨率,同时增大了后续像素点的感受野,也因此使得encoder可以学到更为抽象的特征表示。这种设计有两个优点:平移等变性和局部性。平移等变性使得网络具有一定的泛化能力,而局部性通过参数共享降低了模型复杂度。然而,CNNs难以学习长距离依赖关系,而这种关系对语义分割至关重要。
为了解决上述难点,涌现了大量方法:
- 直接修改卷积操作:大卷积核、空洞卷积、图像/特征金字塔等;
- 引入注意力模块,对feature map中各个像素建模全局上下文信息。
上述两种方式的结构仍然属于Encoder-Decoder的FCN。最近,有研究( Axial-deeplab)仅用注意力模块而不用卷积,进行了尝试。然而,其虽然没有使用卷积,但是仍未摆脱FCN结构:使用Encoder对输入进行空间分辨率的降采样,得到用于语义分割的feature maps,然后使用Decoder上采样feature maps,得到原图大小的分割map。
本文重新思考了语义分割模型的设计,使用仅包含transformers的Encoder,来替代原来的堆叠卷积进行特征提取的方式,这种方式称之为 SEgmentation TRansformer (SETR)。SETR的Encoder通过学习patch embedding将一副图片视为一个包含了一组image patches的序列,并利用全局自注意力对这个序列进行学习。具体来说:
- 首先,将图像分解成一个由固定大小的小块组成的网格,形成一系列的patches;
- 然后,对每个patch拉直后使用一个线性embedding层进行学习,即可获得一个特征嵌入向量的序列,并将该序列作为transformers的输入;
- 接着,经过transformers Encoder之后,得到学习后的高度抽象feature maps;
- 最后,使用一个简单的decoder获得原始分辨率大小的分割map。
SETR的整个过程中,很关键的一点就是没有下采样过程,这和传统基于卷积的backbone进行特征提取的方式是不同的。
这种纯transformers的设计,是受到NLP领域transformer巨大成功所启发,正如ViT、DETR在分类、目标检测上的做法一样。作者也表明,SETR并非简单的将ViT从分类扩展到分割,这里面还是有很多东西要做的,这个过程并不想想象的那么简单。
SETR的主要贡献有以下几点:
- (1)对语义分割任务重新进行了定义,将其视为sequence-to-sequence的问题,这是除了基于Encoder-decoder结构的FCN模型的另一个选择;
- (2)使用纯transformers作为Encoder,对序列化的图片进行特征表示;
- (3)设计了三种decoder,来对自注意力进行深入研究;
2、相关工作
语义分割:
随着深度神经网络的发展,语义图像分割得到了长足的发展。FCN移除分类模型的全连接层,并添加了decoder,开启了深度学习的语义分割时代。而FCN的预测结果比较粗糙,因此又发展出了CRF/MRF的后处理方式来对结果进行精细化调整。为了弥补语义和空间之间的固有矛盾,又在Encoder和Decoder中对深层、浅层进行了融合,这也导致产生了大量具有不同融合方式的变种。
近期的很多研究都集中在解决有限感受野和上下文信息建模的问题上。为了增大感受野,DeepLab和Dilation引入了空洞卷积;而PSPNet和DeepLabv2则是为了进行更好的上下文建模。PSPNet提出了PPM模块来获取不同区域的上下文信息,DeepLabv2则提出了带有不同膨胀率的金字塔空洞卷积模块——ASPP。此外,GCN则通过分解大卷积核来获取大的感受野;PSANet开发了逐点的空间注意力模块来动态捕获长距离上下文;DANet则同时嵌入了空间注意力和通道注意力;CCNet则侧重于在引入全局注意力的同时降低计算量;DGMN构建了一个动态的图消息传递网络用于场景建模,大大降低了计算复杂度。需要注意的是,这些方法都是基于FCN进行的改进:特征提取部分(也即Encoder)都是基于分类模型,如VGG、ResNet等卷积网络,去掉全连接后得到的部分。本文所提出的SETR只这些方法则完全不同,给出了一种新的解决思路。
Transformer:
transformer和自注意力模型彻底改变了机器翻译和NLP领域。近期,也有很多研究探索了将其用于图像识别。Non-local网络将transformer风格的注意力放入了卷积backbone中;AANet混合了卷积和自注意力,进行backbone的训练;LRNet和stand-alone网络探索了局部自注意力来避免由全局自注意力所导致的大计算量;SAN探索了两种类型的自注意力模块;Axial注意力将全局空间注意力分解为两个独立的轴向注意力,大大减少了计算量。上述方法都是一些纯transformer的模型,还有一些CNN和transformer相结合的方法。DETR及其后的变形版本利用transformer进行目标检测,其中transformer包含在检测头中;STTR和LSTR分别采用transformer进行视差估计和车道形状预测。最近,ViT是第一个表明基于纯transformer的图像分类模型可以达到SOTA的工作。这也直接启发了SETR的作者,利用纯transformer设计Encoder。
与SETR最相关的工作是 Axial-deeplab,它也在图像分割上利用了注意力。不过有几点不同:
- 首先,虽然与SETR一样,都去掉了卷积,但Axial-deeplab在Encoder部分仍沿用了FCN中逐渐降低空间分辨率进行降采样的方法,而SETR的Encoder始终保持相同的空间分辨率;
- 其次,为了最大限度地提高在现代硬件加速器上的可扩展性,并使其易于使用,SETR坚持使用标准的自注意力,而Axial-deeplab使用特殊设计的 axial-attention,它对标准计算设备的可扩展性较差;
- 最后,在分割精度上也有优势。
3、方法
3.1、基于FCN的语义分割
FCNs语义分割的Encoder由一系列卷积层堆叠而成,第一层接受尺寸为H*W*3的输入图像,随后若干卷积层的输入尺寸为h*w*d,其中,h和w是feature maps的高和宽,d为其通道数。在深层中每个张量的位置,是由其前面所有浅层一层层计算得来的,也即:感受野。由于卷积运算的局部性,感受野是随着层的叠加而线性增加的,增加的快慢取决于卷积核的大小。最终,在FCN架构中,只有深层才能够具有大感受野,才能建模长距离依赖关系。但是,也有研究表明,随着层次的加深,其带来的感受野增加等收益也在逐渐降低。因此,对于普通的FCN架构来说,在上下文建模方面,其有限的感受野成为其固有的限制。
近期,一些SOTA方法也表明了,将FCNs与注意力机制相结合是一种更为有效的提取长距离上下文信息的策略。但是,由于注意力机制的次幂复杂度,feature maps的分辨率越高所需的计算量就越大,因此这些方法都是将注意力机制放在分辨率较小的深层后面,以利用其小尺寸的输入来降低计算复杂度。这也就意味着,缺失了浅层中注意力依赖关系的学习。SETR的提取也就是为了解决这个问题。
3.2、SETR
整个的SETR结构如图1所示:
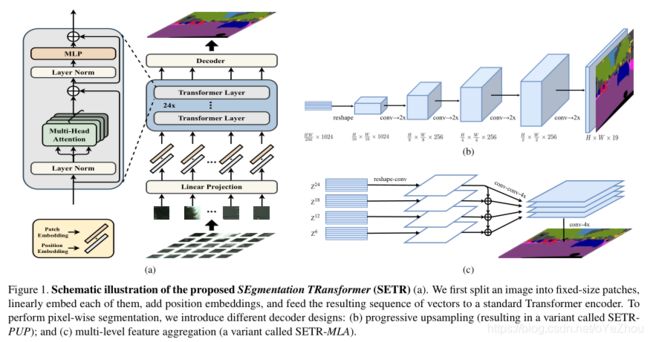
Image to sequence:
SETR遵循了NLP中的输入-输入结构,使用的是一维序列,因此,2D图像和1D序列之间就不匹配了。具体的,如图1(a)中所示,transformer接受一个1D的序列![]() 作为输入,L为序列长度,C为隐藏通道的尺寸。因此,图像序列化就需要将输入图像
作为输入,L为序列长度,C为隐藏通道的尺寸。因此,图像序列化就需要将输入图像![]() 转化为
转化为![]() 。
。
图像序列化的一个简单粗暴的方式就是将图像直接拉直为3HW维的1D向量,不过这种做法得到的1D向量维度过高,如480*480的图像拉直之后就是480*480*3=691200维,再加上transformer的平方复杂度,这不管是空间还是时间复杂度都是极其复杂的。因此,这种方式是行不通的。
鉴于为语义分割设计的典型编码器会对二维图像![]() 进行下采样,得到
进行下采样,得到![]() ,因此,SETR也将transformer的输入长度L设计为
,因此,SETR也将transformer的输入长度L设计为![]() 。这样一来,transformer的输出序列也可以简单地reshape为目标feature map
。这样一来,transformer的输出序列也可以简单地reshape为目标feature map![]() 。
。
为了获取长度为![]() 的输入序列,将一张图片分解为一个包含
的输入序列,将一张图片分解为一个包含![]() 个patchs的网格,然后将该网格拉伸为一个序列。通过使用线性投影函数
个patchs的网格,然后将该网格拉伸为一个序列。通过使用线性投影函数![]() 将每个向量化的patch p进一步映射到一个潜在的C维嵌入空间,我们得到了图像x的一个一维的patch嵌入序列。为了编码每个位置i的空间信息,学习了一个特殊的嵌入
将每个向量化的patch p进一步映射到一个潜在的C维嵌入空间,我们得到了图像x的一个一维的patch嵌入序列。为了编码每个位置i的空间信息,学习了一个特殊的嵌入 ,并与
,并与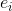 相加,得到最终的输入序列:。如此,尽管transformer中的自注意力是无序的,但空间位置信息仍被嵌入到输入当中了。
相加,得到最终的输入序列:。如此,尽管transformer中的自注意力是无序的,但空间位置信息仍被嵌入到输入当中了。
Transfomer:
给定一个1D的嵌入序列E作为输入,然后使用一个基于纯transformer的encoder进行特征表示学习。这意味着,每个transformer层都有着全局感受野,这也就一次性地解决了在FCNs的encoder中所存在的感受野受限问题。transformer encoder由![]() 层多头自注意力(MSA)模块和多层感知机(MLP)组成,如图1(a)所示。在第
层多头自注意力(MSA)模块和多层感知机(MLP)组成,如图1(a)所示。在第 层中,自注意力的输入是一个从输入
层中,自注意力的输入是一个从输入![]() 计算得到三维元组 (query, key, value):
计算得到三维元组 (query, key, value):
![]() (1)
(1)
其中,![]() 为三个线性投影层的可学习参数,
为三个线性投影层的可学习参数, 为 (query, key, value)的维度。自注意力(SA)可以表示为:
为 (query, key, value)的维度。自注意力(SA)可以表示为:
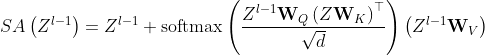 (2)
(2)
而MSA则是由m个SA操作拼接起来然后投影得到:![]() ,其中:
,其中:![]() ,d通常设置为C/m。然后,MSA的输出被一个带有残差跳跃连接的MLP块进行转换:
,d通常设置为C/m。然后,MSA的输出被一个带有残差跳跃连接的MLP块进行转换:
![]() (3)
(3)
注意,在MSA和MLP之前,还应用了层归一化,为了简单起见,这里并为体现出来。
到这里,就得到了transformer各层的输出:![]() 。
。
3.3、Decoder的设计
为了评估SETR所编码的特征的有效性,设计了三种不同的decoder进行像素级分割。对于decoder来说,其目标是生成与原图大小(H*W)相同的2D分割结果,因此需要将encoder的feature map从2D尺寸![]() reshape到标准的3D尺寸
reshape到标准的3D尺寸![]() 。接下来,将简要介绍三种decoder。
。接下来,将简要介绍三种decoder。
(1)朴素上采样(Naive)
这种朴素decoder首先将transformer的特征![]() 投影到类别个数的维度上(如Cityscapes中有19类)。这里实现了一个简单的2层网络结构:1*1卷积 + sync BN (W/ReLI)+1*1卷积。之后,直接双线性插值上采样,得到原分辨率大小的输出,最后接着一个带有像素级交叉熵损失的分类层。当使用这种decoder时,得到的模型称为SETR-Naive。
投影到类别个数的维度上(如Cityscapes中有19类)。这里实现了一个简单的2层网络结构:1*1卷积 + sync BN (W/ReLI)+1*1卷积。之后,直接双线性插值上采样,得到原分辨率大小的输出,最后接着一个带有像素级交叉熵损失的分类层。当使用这种decoder时,得到的模型称为SETR-Naive。
(2)渐进上采样(PUP)
直接一步上采样可能会引入噪声,与之相反,作者又设计了一种交替执行卷积和上采样操作的渐进式上采样decoder。为了最大化的减轻对抗效应,将上采样倍数限制为2倍。因此,要想从尺寸为![]() 的
的![]() 得到原始分辨率,就需要进行共4次上采样操作,具体细节如图1(b)所示。当使用这种decoder时,得到的模型称之为SETR-PUP。
得到原始分辨率,就需要进行共4次上采样操作,具体细节如图1(b)所示。当使用这种decoder时,得到的模型称之为SETR-PUP。
(3)多级特征融合(MLA)
第三种decoder设计主要特点是多级特征融合,这与特征金字塔具有相似的理念。不过,不同的是,这里的特征表示![]() 是来自每个SETR的transformer层并具有相同的分辨率,不像特征金字塔那样具有不同分辨率。特别的,这里将来自M个层的特征表示
是来自每个SETR的transformer层并具有相同的分辨率,不像特征金字塔那样具有不同分辨率。特别的,这里将来自M个层的特征表示![]() ,这M层特征是每隔
,这M层特征是每隔![]() 层提取一层得到的,每一层都聚焦于一个特定选取的transformer层。这M条路径中,每条都包含了同样的处理过程:先将encoder中的特征
层提取一层得到的,每一层都聚焦于一个特定选取的transformer层。这M条路径中,每条都包含了同样的处理过程:先将encoder中的特征![]() 从
从![]() reshape到
reshape到![]() ;然后,应用了一个3层(1*1,3*3,3*3)神经网络进行处理,在第一和第三层分别将通道数减半,并在第三层之后进行4倍双线性上采样。为了增强不同路径之间的信息交互,还设计了一个自顶向下的融合过程,从第二条路径开始,依次融合前面路径的特征。在像素级特征融合之后,再次使用了一个3*3卷积层。最后,将每条路径得到feature maps进行通道维度的拼接,并进行4倍双线性插值上采样。当使用这种decoder时,所得模型称之为SETR-MLA。
;然后,应用了一个3层(1*1,3*3,3*3)神经网络进行处理,在第一和第三层分别将通道数减半,并在第三层之后进行4倍双线性上采样。为了增强不同路径之间的信息交互,还设计了一个自顶向下的融合过程,从第二条路径开始,依次融合前面路径的特征。在像素级特征融合之后,再次使用了一个3*3卷积层。最后,将每条路径得到feature maps进行通道维度的拼接,并进行4倍双线性插值上采样。当使用这种decoder时,所得模型称之为SETR-MLA。
4、实验结果
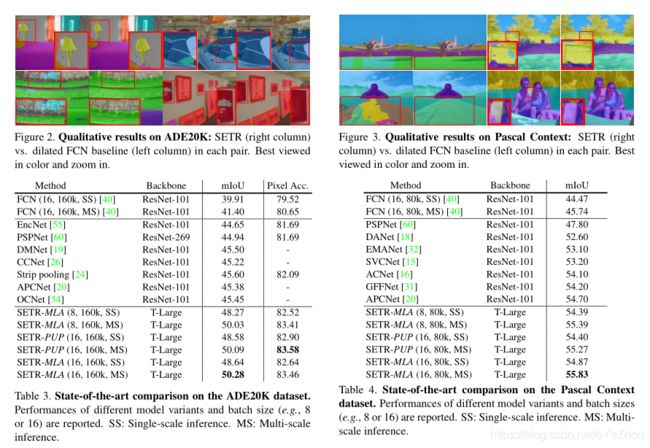
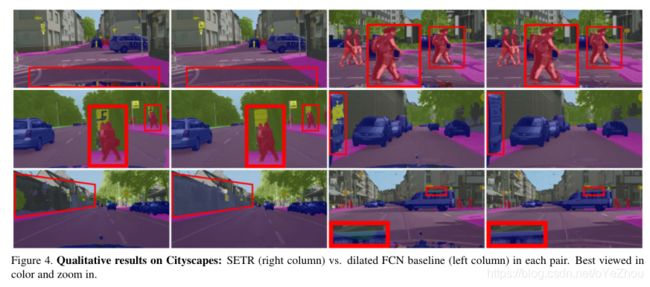
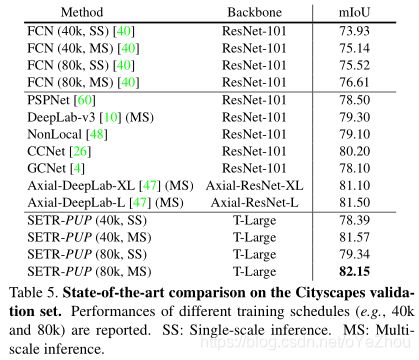
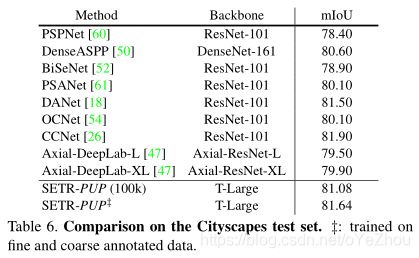
5、总结
这篇文章,主要是将分割任务作为序列-序列的预测任务,从而提出了一种新的语义分割的模型设计角度。与现有基于FCN的模型利用空洞卷积和注意力模块来增大感受野的方式不同,SETR使用transformer作为encoder,在encoder的每层中都进行全局上下文建模,完美去掉了对FCN中卷积的依赖。结合所设计的三种不同复杂度的decoder,形成了强大的分割模型,且没有最近一些模型中的花哨的操作。大量实验也表明,SETR达到了新的SOTA:ADE20K (50.28% mIoU)、 Pascal Context(55.83% mIoU) 、Cityscapes中有竞争力的结果,并在ADE20K测试服务器排行榜位列第一。