第八章——大数据
一、大数据概述
1.大数据概念
大数据(big data)是一个抽象的概念,至今尚无确切、统一的定义,不同的研究机构与学者对其有着不同的定义。
全球最具权威的IT研究与顾问研究机构高德纳(TheGartner Group)咨询公司给出了这样的定义:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
麦肯锡全球研究所对大数据的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换言之,如果把大数据比作一种产业,那么这种产业实现盈利的关键在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。
从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据必然无法用单台的计算机进行处理,必须采用分布式架构。它的特色在于对海量数据进行分布式数据挖掘,因此它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术。
大数据需要特殊的技术,以有效地处理大量的容忍经过时间内的数据。
2.特征
IBM公司认为大数据具有3V特定,即规模性(Volume)、多样性(Variety)和实时性(Velocity),但是这没有体现出大数据的巨大价值。而以IDC为代表的业界则认为大数据具备4V特点,即在3V的基础上增加价值性(Value),具体表现为大数据虽然价值总量高但其价值密度底。目前,大家公认的是大数据具有4个基本特征:数据规模大,数据种类多,处理速度快以及数据价值密度低,即4V。
(1)数据规模大。第一个特征是数据量大,包括采集、存储和计算的量都非常大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)
(2)数据种类多。第二个特征是种类和来源多样化。包括结构化、半结构化和非结构化数据,具体表现为网络日志音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
(3)处理速度快。第三个特征数据增长速度快,处理速度也快,时效性要求高。比如搜索引擎要求几分钟前的新闻能够被用户查询到,个性化推荐算法尽可能要求实时完成推荐。这是大数据区别于传统数据挖掘的显著特征。
(4)价值密度低(Value)。第四个特征是数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵。随着互联网以及物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,是大数据时代最需要解决的问题。
3.发展历程
全球首次将“大数据”划分为四大阶段,即“大数据出现阶段,“大数据”热门阶段,“大数据”时代特征阶段和“大数据”爆发期阶段。
出现阶段(1980-2008年)
“大数据”一词在1980年[美]著名未来学家阿尔文·托夫勒著的《第三次浪潮》书中将“大数据”称为“第三次浪潮的华彩乐章”。1997年美国宇航局研究员迈克尔·考克斯和大卫·埃尔斯沃斯首次使用“大数据”这一术语来描述20世纪90年代的挑战:模拟飞机周围的气流—一是不能被处理和可视化的。数据集通常之大,超出了主存储器、本地磁盘,甚至远程磁盘的承载能力。称之为“大数据问题。”
热门阶段(2009-2011年)
从2009-2010年“大数据”成为互联网技术行业中的热门词汇。2009年美国政府通过启动Data.qov网站的方式进一步开放了数据的大门;2010年肯尼斯库克尔发表大数据专题报告《数据,无所不在的数据》;2011年2月扫描2亿年的页面信息,或4兆兆字节磁盘存储,只需几秒即可完成。在2011年6月麦肯锡发布了关于“大数据”的报告,正式定义了大数据的概念,后逐渐受到了各行各业关注;2011年12月,工信部发布的物联网十二五规划上,把信息处理技术作为4项关键技术创新工程之一被提出来,其中包括了海量数据存储、数据挖掘、图像视频智能分析,这些是大数据的重要组成部分。
特征阶段(2012-2016年)
《纽约时报》2012年2月的一篇专栏中称“大数据”时代已经降临,在商业、经济及其他领域中,决策将日益基于数据和分析而作出,而并非基于经验和直觉。2012年,美国奥巴马政府在白宫网站发布了《大数据研究和发展倡议》,这一倡议标志着大数据已经成为重要的时代特征;2012年5月,联合国在纽约发布了一份关于大数据政务的白皮书《大数据促发展,挑战与机遇》,总结了各国政府如何利用大数据更好地服务和保护人民。随着2013年的一系列标志性事件的发生,人们越来越感到大数据时代的力量,因此2013年被许多国外媒体和专家称为“大数据元年”。
爆发期阶段(2017-2022年)
2017年,大数据已经渗透到人们生活的方方面面,我国大数据产业的发展也进入爆发期。2017年2月8日,贵阳市向首批16个具有引领性和标志性的大数据产业集聚区和示范基地进行授牌,作为国家大数据综合试验区核心区。2018年达沃斯世界经济论坛等全球性重要会议都把“大数据”作为重要议题,进行讨论和展望。“大数据”是2018年达沃斯世界经济论坛的热词之一。大数据发展浪潮席卷全球。全球各经济社会系统采集、处理、积累的数据增长迅猛,大数据全产业市场规模逐步提升。2018年大数据产业或呈现开源大数据商业化进一步深入等七大发展趋势:产业应用将是主旋律。
4.应用
大数据在人们生活的各个方面都有所应用。
二、数据获取
1.网络爬虫
1)概念与原理:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。它的定义有广义和狭义之分。
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。整个搜索引擎系统包含4个模块,分别为信息搜索模块、信息索引模块、信息检索模块和用户接口部分,而网络爬虫便是信息搜索模块的核心。
Web网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据来源。很多大型的网络搜索引擎系统都被称为基于 Web数据采集的搜索引擎系统,比如 Google、Baidu。由此可见Web 网络爬虫系统在搜索引擎中的重要性。网页中除了包含供用户阅读的文字信息外,还包含一些超链接信息。Web网络爬虫系统正是通过网页中的超连接信息不断获得网络上的其它网页。正是因为这种采集过程像一个爬虫或者蜘蛛在网络上漫游,所以它才被称为网络爬虫系统或者网络蜘蛛系统,在英文中称为Spider或者Crawler。
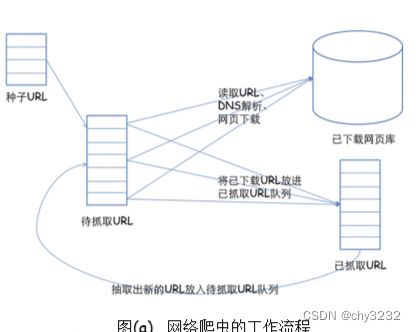
①系统架构
在网络爬虫的系统框架中,主过程由控制器、解析器、资源库三部分组成。
(1)控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。
(2)解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。
(3)资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
②抓取对象
网络爬虫的抓取对象可以分为以下4类:
(1) 静态网页(2)动态网页(3)特殊内容(4)文件对象
③抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1)深度优先策略
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件)。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。
2)广度优先策略
对于一些动态网页或小网站,采取广度优先策略抓取,搜索引擎会抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。其基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
3)聚焦搜索策略
聚焦搜索策略只挑出某个特定主题的页面,根据“最好优先原则”进行访问,快速、有效地获得更多与主题相关的页面。
4)最佳优先搜索策略。这种策略按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取。它只访问经过网页分析算法预测为“有用”的网页。存在的一个问题是,在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种局部最优搜索算法。
5)基于IP地址的搜索策略。先赋予爬虫一个起始的IP地址,然后根据IP地址递增的方式搜索本IP地址段后的每一个WWW地址中的文档,它完全不考虑各文档中指向其它Web 站点的超级链接地址。优点是搜索全面,能够发现那些没被其它文档引用的新文档的信息源;缺点是不适合大规模搜索。
搜索策略目前常见的是广度优先策略和最佳优先策略。关键技术分析
1)抓取目标的定义与描述
①针对有目标网页特征的网页级信息。
② 针对目标网页上的结构化数据。
2)网页的分析与信息的提取
①基于网页拓扑关系的分析算法。
②基于网页内容的分析算法。
③基于用户访问行为的分析算法。