目标检测之DETR:End-to-End Object Detection with Transformers
特点:self-attention layers,end-to-end set predictions,bipartite matching loss
The DETR model有两个重要部分:
1)保证真实值与预测值之间唯一匹配的集合预测损失。
2)一个可以预测(一次性)目标集合和对他们关系建模的架构。
3)由于是加了自注意力机制,而且在学习的过程中,观众的注意力训练的很好,每个人的关注点都不一样,所以分割效果很好,有效的解决遮挡问题


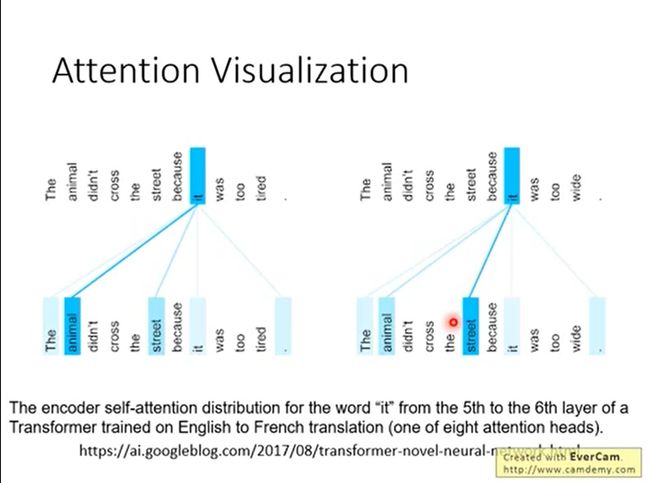
DETR 将目标检测任务视为一个图像到集合(image-to-set)的问题,即给定一张图像,模型的预测结果是一个包含了所有目标的无序集合。
这个将目标检测任务转化为一个序列预测(set prediction)的任务,使用transformer编码-解码器结构和双边匹配的方法,由输入图像直接得到预测结果序列.他不产生anchor,直接产生预测结构
缺点:对于小目标、多目标场景较差
1.基础知识
1.1one-hot矩阵:是指每一行有且只有一个元素为1,其他元素都是0的矩阵。针对字典中的每个单词,我们分配一个编号,对某句话进行编码时,将里面的每个单词转换成字典里面这个单词编号对应的位置为1的one-hot矩阵就可以了。比如我们要表达“the cat sat on the mat”,可以使用如下的矩阵表示。
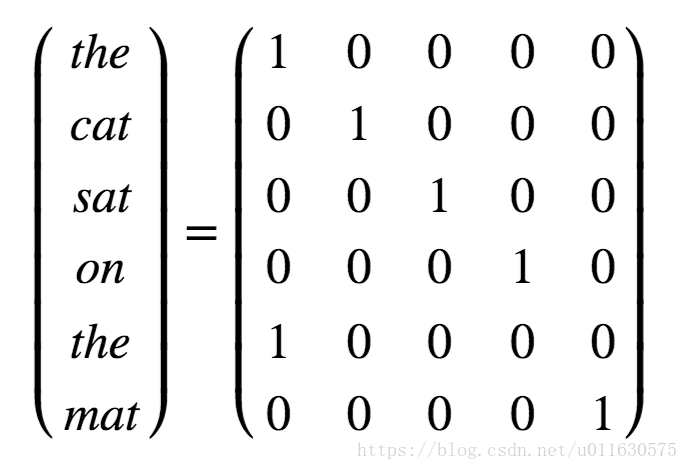
one-hot表示方式很直观,但是有两个缺点,第一,矩阵的每一维长度都是字典的长度,比如字典包含10000个单词,那么每个单词对应的one-hot向量就是1X10000的向量,而这个向量只有一个位置为1,其余都是0,浪费空间,不利于计算。第二,one-hot矩阵相当于简单的给每个单词编了个号,但是单词和单词之间的关系则完全体现不出来。比如“cat”和“mouse”的关联性要高于“cat”和“cellphone”,这种关系在one-hot表示法中就没有体现出来。
1.2词嵌入向量Word Embedding:解决了这两个问题。Word Embedding矩阵给每个单词分配一个固定长度的向量表示,这个长度可以自行设定,比如300,实际上会远远小于字典长度(比如10000)。而且两个单词向量之间的夹角值可以作为他们之间关系的一个衡量。如下表示


三个w矩阵就是衡量qkv权重的矩阵,权重矩阵都是训练得来的,自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
查询向量:将每个词嵌入向量与WQ 向量相乘得到。用于与所有的键向量相乘直接得到分数。
键向量:同样的,将每个词嵌入向量与W K 得到。
值向量:同上。用于对每个单词的分数的加权。
1.3自注意力计算步骤:

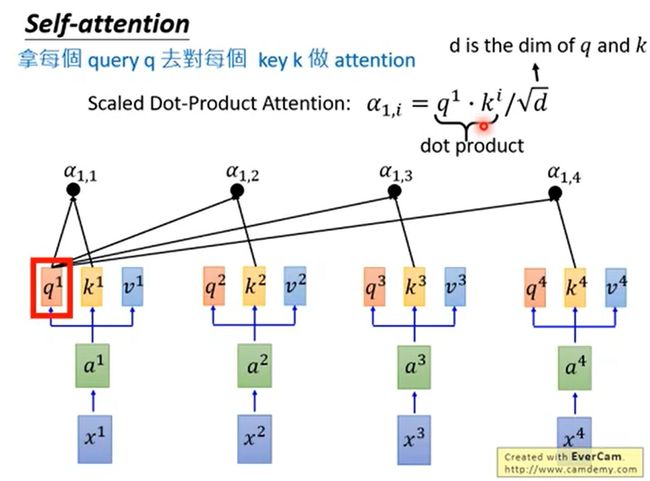



1.将查询向量与每个键向量相乘,得到打分,比如112,96,此打分评估Thinking与Machines这两个单词与自身以及其余单词的相关性。
2.将打分除以键向量维数的平方根(sqrt{64}=8),维度惩罚项目,这样有利于梯度稳定。
3.进行softmax进行归一化,每个单词都得到一个权重。
4.将每个值向量按照每个单词的权重进行加权求和。得到Z i
bi是集合了全局信息的变量,只要在∑时候只算(1,1)就是只收集局部信息。
1.4多头自注意力:对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中


之后把八个矩阵给concat,再用一个训练号的矩阵w0给他融合注意力

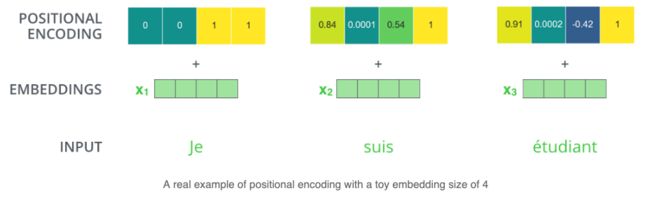
1.5位置编码positional encoding:
在NLP中,句子中的单词也需要一个位置编码,用于建立单词之间的距离。encoder 为每个输入 embedding 添加了一个向量,这些向量符合一种特定模式,可以确定每个单词的位置,或者序列中不同单词之间的距离。例如,input embedding 的维度为4,那么实际的positional encodings如下所示
1.代码中作者自己的思想
Arg:一个超参数集合
Namespace(aux_loss=True, backbone='resnet50', batch_size=2, bbox_loss_coef=5, clip_max_norm=0.1, coco_panoptic_path=None, coco_path=None, dataset_file='coco', dec_layers=6, device='cuda', dice_loss_coef=1, dilation=False, dim_feedforward=2048, dist_url='env://', distributed=False, dropout=0.1, enc_layers=6, eos_coef=0.1, epochs=300, eval=False, frozen_weights=None, giou_loss_coef=2, hidden_dim=256, lr=0.0001, lr_backbone=1e-05, lr_drop=200, mask_loss_coef=1, masks=False, nheads=8, num_queries=100, num_workers=2, output_dir='', position_embedding='sine', pre_norm=False, remove_difficult=False, resume='', seed=42, set_cost_bbox=5, set_cost_class=1, set_cost_giou=2, start_epoch=0, weight_decay=0.0001, world_size=1)
作者新建的一种数据类型用来存放特征:tensor就是我么的图片的值,当一个batch中的图片大小不一样的时候,我们要把它们处理的整齐,简单说就是把图片都padding成最大的尺寸,padding的方式就是补零,那么batch中的每一张图都有一个mask矩阵,一个mask矩阵即用以指示哪些是真正的数据,哪些是padding,1代表真实数据;0代表padding数据。
NestedTensor数据类型:
#NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
class NestedTensor(object):
def __init__(self, tensors, mask: Optional[Tensor]):
self.tensors = tensors
self.mask = mask
def to(self, device):
# type: (Device) -> NestedTensor # noqa
cast_tensor = self.tensors.to(device)
mask = self.mask
if mask is not None:
assert mask is not None
cast_mask = mask.to(device)
else:
cast_mask = None
return NestedTensor(cast_tensor, cast_mask)
def decompose(self):
return self.tensors, self.mask
def __repr__(self):
return str(self.tensors)
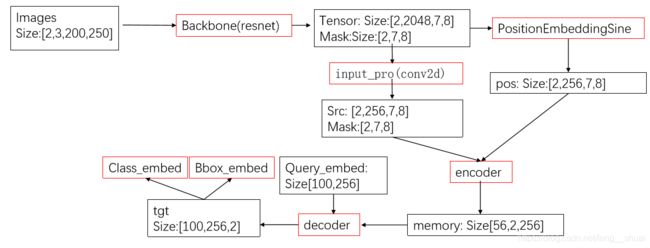
2.DETR网络结构
detr没提出新的layer,他直接提出了新的框架。先通关传统的cnn来提取特征,与此同时同步再进行positional encoding。经过Transformer的encoder、decoder后经过简单的前向传播网络(FNN)后得到结果。

class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
2.0backbone
他要求的比较简单,只要满足
输入是C=3×H×W,输出是C = 2048和H,W = H / 32,W / 32。
之后把所有的feature map铺平,变成了CxWH规模的,此时的位置信息就是二维的

2.1position encode

Main.py:
def main(args):
model, criterion, postprocessors = build_model(args)
if __name__ == '__main__':
parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
args = parser.parse_args()
if args.output_dir:
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)
Detr.py:
def build(args):
backbone = build_backbone(args)
position encoding:
def build_position_encoding(args):
N_steps = args.hidden_dim // 2#隐藏层维度的一半
if args.position_embedding in ('v2', 'sine'):
# TODO find a better way of exposing other arguments
position_embedding = PositionEmbeddingSine(N_steps, normalize=True)
elif args.position_embedding in ('v3', 'learned'):
position_embedding = PositionEmbeddingLearned(N_steps)
else:
raise ValueError(f"not supported {args.position_embedding}")
return position_embedding
class PositionEmbeddingSine(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.搞了个和Attention is all you need paper一样的位置编码方式
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
mask = tensor_list.mask
assert mask is not None
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32)
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t#这里的x——embed就是posx
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = ((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
2.2Transform

class Transformer(nn.Module):
def __init__(self, d_model=512, nhead=8, num_encoder_layers=6,
num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False,
return_intermediate_dec=False):
super().__init__()
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
encoder_norm = nn.LayerNorm(d_model) if normalize_before else None
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, encoder_norm)
#六次自编码:每次都是一次八头自注意力+FFN
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=return_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)#扩展成两通道的,并且新的那一层是复制而来
mask = mask.flatten(1)#铺平
tgt = torch.zeros_like(query_embed)#输出一个大小和query_embed一样但全是0的矩阵,初始化作为一开始第一次层固定输入
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)#编码
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)#解码
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
class PositionEmbeddingLearned(nn.Module):
"""
Absolute pos embedding, learned.
"""
def __init__(self, num_pos_feats=256):
super().__init__()
self.row_embed = nn.Embedding(50, num_pos_feats)
self.col_embed = nn.Embedding(50, num_pos_feats)
self.reset_parameters()
def reset_parameters(self):
nn.init.uniform_(self.row_embed.weight)
nn.init.uniform_(self.col_embed.weight)
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
h, w = x.shape[-2:]
i = torch.arange(w, device=x.device)
j = torch.arange(h, device=x.device)
x_emb = self.col_embed(i)
y_emb = self.row_embed(j)
pos = torch.cat([
x_emb.unsqueeze(0).repeat(h, 1, 1),
y_emb.unsqueeze(1).repeat(1, w, 1),
], dim=-1).permute(2, 0, 1).unsqueeze(0).repeat(x.shape[0], 1, 1, 1)
return pos
2.2.1Transformer encoder
首先,1x1卷积将高阶特征图f的通道维数从C降低到更小的维数d。由于transformer要求输入的是一个序列,故将此特征的每个通道拉成一个向量,成为d X WH大小。由于这个transformer具备置换不变性(permutation invariant,输入的顺序对结果没有影响,所以直接没有了位置信息),故需要补充固定的位置编码作为输入。每个encoder层由 multi-head self-attention模块和FFN组成每个输入通过编码器都会输出一个d维的特征向量。
在“多头”注意机制下,我们为每个头保持独立的查询/键/值权重矩阵,只需八次不同的权重矩阵运算,我们就会得到八个不同的Z矩阵
编码器的左右只是为了服务解码器,把输入的特征做了自注意力加权映射,如果有更好的backbone网络,可以完全不编码

encoder的输入为:src, mask, pos_embed
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)#对encoder_layer复制num_layers次
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
#output进行六次编码
if self.norm is not None:
output = self.norm(output)
return output
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):#位置编码
return tensor if pos is None else tensor + pos
#pre和post的区别在于有无归一化
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)#位置编码融入,pos + src
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)# 类似于残差网络的加法
src = self.norm1(src)#layernorm,不是batchnorm
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))#两个ffn
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
前五次的输出都是src用于下一次的训练,组后一次输出的较memory,哟关于传递到decoder,两个一样,只是命名不同
2.2.2Transformer decoder
和编码原理差不多,就是要加入编码-解码注意力,解码才是Transformer 的关键,前面的一大堆都可以看成特征提取,解码是要输出预测的类别和回归坐标。
他的输入是N个 object queries ,在经过自注意力机制后,混入解码的输出在做编码解码自注意力。然后通过前馈网络,将它们独立解码为框坐标和类标签,从而产生N个最终预测。使用自注意力和编码-解码注意力对这些嵌入的关注,模型全局地使用所有对象之间的成对关系,同时能够使用整个图像作为上下文信息
输入:memory:这个就是encoder的输出size=[56,2,256]
mask:还是上面的mask
pos_embed:还是上面的pos_embed
query_embed:随机生成的观众注意力,size=[100,2,256]
tgt: 每一层的decoder的输入,第一层的话等于0
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
intermediate = []
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0)
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)#自注意力
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)#和上面是一个东西,不过是解码注意力
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)#前馈神经网络
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
2.3Object querise
是产生的一组随机向量,模拟观众的关注度,论文中模拟了n=100个观众的关注点,这些关注点可以没有目标是空集。而且每个观众都会由三种颜色的主义力–green color corresponds to small
boxes, red to large horizontal boxes and blue to large vertical boxes
在class detr里有这么一句话:
self.query_embed = nn.Embedding(num_queries, hidden_dim)
这句话就是用来生成观众注意力的
num_embeddings (python:int) – 词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999)
embedding_dim (python:int) – 嵌入向量的维度,即用多少维来表示一个符号。
padding_idx (python:int, optional) – 填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
max_norm (python:float, optional) – 最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
norm_type (python:float, optional) – 指定利用什么范数计算,并用于对比max_norm,默认为2范数。
scale_grad_by_freq (boolean, optional) – 根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
sparse (bool, optional) – 若为True,则与权重矩阵相关的梯度转变为稀疏张量.

把这些Object querise先进行一遍self attenton,之后用他们去和encoder产生的self attention,合在一起再去做编码-解码attention,这时候的特征就是加了观众注意力的特征,然后再去做FFN络输出class和bbox的整合信息,再传给两个FFN分别去做分类和回归

2.4回归
class detr:定义一下bbox_embed和class_embed ,就是最后的产生bbox的FFN和类,classes+1是因为有背景信息
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
self.class_embed = nn.Linear(hidden_dim, num_classes + 1)
FFN模块,比较简单
class MLP(nn.Module):
""" Very simple multi-layer perceptron (also called FFN)"""
def __init__(self, input_dim, hidden_dim, output_dim, num_layers):
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim]))
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
return x
class detr:
outputs_class = self.class_embed(hs)
outputs_coord = self.bbox_embed(hs).sigmoid()
pred_logits:[2,100,classes+1]
outputs_coord:[2,100,4]
3.损失函数
由于DETR特殊的结构,所以要重新构造损失函数。DETR输出固定大小的N(文章里n取100)个预测结果,N通常比实际的一张图片中的目标数要多。预测的主要困难就是给输出目标(包括类别,位置,尺寸)一个打分。
y拔表示n个预测的集合,由于n是远大于图中目标的个数,所以要把y用∅pad一下。n个y拔和n个y要找到一个损失最小的,就变成了一个二分图的最大匹配问题,所以可以使用加权的匈牙利算法(km算法):递归的找除一组损失最小损失两两匹配顺序,其关键就是找到增广路(augmenting path)–假设目前已有一个匹配结果,存在一组未匹配定点的,能够找到一条路径,这条路径上匹配和未匹配的定点交替出现,称为增广路。
ps:用贪心算法也可以获得近似最优解,而且计算量比较小
这样把计算gt和region proposal的iou,并不再使用非极大值抑制来减少region proposa产生,同时减少了人工成本。下面公式的含义:找到y和y拔匹配中损失最小的一对,最后求全局所有配对的最小损失

损失函数就是类别损失与box损失的线性组合,左边为class损失,右边为box损失。
先说class损失:σ拔就是在最优匹配下的情况,pσ就是此时的概率,然后以其为指数,以10为底数求对数的交叉熵损失(c为真实概率,p为预测概率)。由于一个图片中的类别c肯定小于n(n=100)所以,c有可能为空集,当c为空集的时候,把log-probability 权重降低10倍,来解决正负样本不平衡。

def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
"""Classification loss (NLL)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
assert 'pred_logits' in outputs
src_logits = outputs['pred_logits']
idx = self._get_src_permutation_idx(indices)
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
target_classes[idx] = target_classes_o
loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)#交叉熵
losses = {'loss_ce': loss_ce}
后面bbox具体损失为:L1 loss 与IOU loss的组合,因为直接使用L1loss的话,loss对目标的大小很敏感,权重蓝不大为超参数,要人工设置
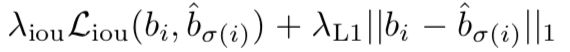
def loss_boxes(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size.
"""
assert 'pred_boxes' in outputs#断言,就是会报错的if
idx = self._get_src_permutation_idx(indices)
src_boxes = outputs['pred_boxes'][idx]
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0)
loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none')
losses = {}#losses是字典类型
losses['loss_bbox'] = loss_bbox.sum() / num_boxes#第一部分损失L1 loss
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes#第二部分损失
return losses
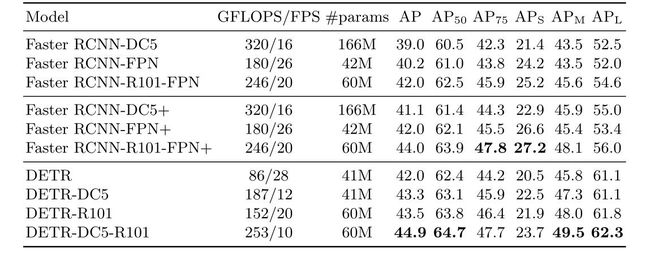
4.实验结果