虚假视频处理的门道
今天视频号直播,与彭涛哥连麦聊天,从Python自动化办公聊到了程序自动化去赚钱,然后聊到了我前段弄的视频批量生成(目的在于对抗平台进行视频去重)。
直播完后,多位朋友私聊我相关的技术细节和处理后视频的效果,其结论是:技术这块我跑通过了,对少量视频进行测试,在抖音和shorts上是没啥问题的,至于大量测试嘛,因为心不在此,暂时没测,有心人可以利用本文提出的技术手段尝试一下,如果你愿意将测试结果告知于我,那就更好了。
本文主要是简单介绍一下,生成虚拟视频中我使用过的一些技术手段,我对视频处理并不是常规的混剪、换音乐、给视频加一些特效或加字幕等传统方式,而是通过对视频进行换脸处理、视频背景替换来实现的,当然在这过程中,我也尝试了其他方向,比如唇语视频生成实现对视频里的人说的内容进行操控,还比如实现一个虚拟播报人,对于一些常见的新闻视频做到虚拟生成视频播报等尝试。
二两:本文尽力少提技术细节,朋友们请放心食用。
换脸处理
换脸的底层技术是GAN(生成对抗网络),你想了解这块的技术细节可以购买我之前出的书籍《深入浅出GAN生成对抗网络》,此书质量不错,已输出到台湾(繁体版本),有兴趣的技术同学可以下单一本。
当然你也可以阅读我之前写的换脸技术浅析的文章。
广告时间结束,回到正题,我试过市面上绝大多数换脸相关的开源项目,从易上手角度来讲,推荐DeepFaceLab项目(https://github.com/iperov/DeepFaceLab)

对于Windows系统的同学,DeepFaceLab(简称:DFL)提供了非常完善的工具链,比如上图,就是DFL提供了扣脸工具XsegEditor,正常情况下,DFL会通过算法(s3fd算法)直接扣脸,但对于一些特殊情况,如上图半脸情况或脸部被话筒、眼镜等不规则物体遮挡时,就需要人为手动介入,借助XsegEditor工具完成人脸抠像。
一些视频中可能会存在遮挡物,如上文提到的脸部被话筒、眼镜等物体遮挡,对于常规的遮挡物,可以通过DFL提供的通用遮罩识别模型进行识别,但对于特殊的遮罩物,比如鲜花等,效果就比较差了。
DFL虽然提供了比较好的工具链,但它并没有提供预训练模型,所以你还是需要自己收集目标人脸,收集时,注意角度尽可能多,DFL集成了人脸数据集检测算法,对每个人脸25%的偏侧进行检测,从而判断人脸数据集的质量,角度不全的数据集,在换脸时效果比较难把控,此外,换脸时,视频中人物动作幅度如果很大,s3fd人脸提取算法可能无法识别,所以非业务必要尽力不去选动作幅度大的视频。
我个人在Windows上跑通后,将整套简单调整后整合到自己的FakeVideo项目中,放在Ubuntu服务器上跑,对于人脸无法识别出的部分,直接跳过处理,因为我并不是需要一个完美换脸视频,而是能用的换脸视频,对于视频中某几帧的失败处理,并不关心。
因为DFL自己基于TensorFlow封装了一个深度学习框架,所以源码读起来,需要花点时间,但如果只是单纯的使用,其实你不需要关心这些。
最后,我实现的效果如下,左边是原视频,右边是换成欧阳娜娜的处理后视频:

换脸技术在直播上的应用
一些公司担心旗下主播跑路,所以希望通过换脸技术将主播的脸替换掉,使用公司生成的人脸,此时人脸就是公司资产了,目前主要有两个方式,第一种,就是直播时替换成其他真实人脸(非卡通、虚拟人物脸),第二种,就是替换成卡通人脸。
先说第一种,替换真实人脸,可以使用DeepFaceLive(https://github.com/iperov/DeepFaceLive)
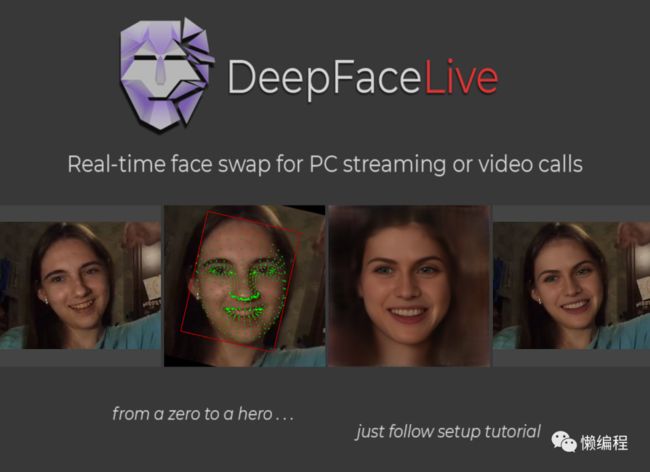
DeepFaceLive可以做到实时替换人脸,就如上图所示,结合OBS推流工具便可以实现实时替换主播的效果,当然,这需要你本地有一台搭载了GPU的PC电脑,但有技术背景的同学完全可以魔改。
比如,我看见别人说可以提供不需要搭载GPU的PC也可以实现实时换脸效果的技术,如果是我,我可以在服务器上搭建好DeepFaceLive,然后结合OBS直接帮助用户推流,这样对用户而言,就是用我提供给你的软件在进行直播,视频流的运算丢到了服务器处理后直接推流到相应的媒体实现直播。
因为我本人没有需求,所以没有深入使用过DeepFaceLive,这里便不多赘述。
接着来说第二种,替换成卡通人脸,我们可以使用kalidokit(https://github.com/yeemachine/kalidokit)。
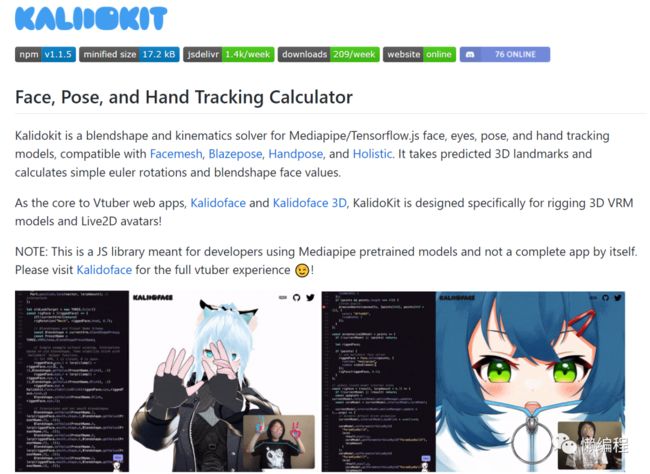
这个就挺有意思的,Kalidokit基于TensorFlow.js实现,你不止可以使用它来控制人脸,还可以对虚拟人物的骨干进行控制,而且它也是实时,你完全可以结合OBS实现卡通人直播。
当然还有一些其他方案,比如通过虚幻引擎构建出虚拟人的模型,然后结合Python人脸网格(Face Mesh)和人体骨干相关的库实现对虚幻引擎中虚拟人的操作(抖音上挺多人售卖相关教程的)。
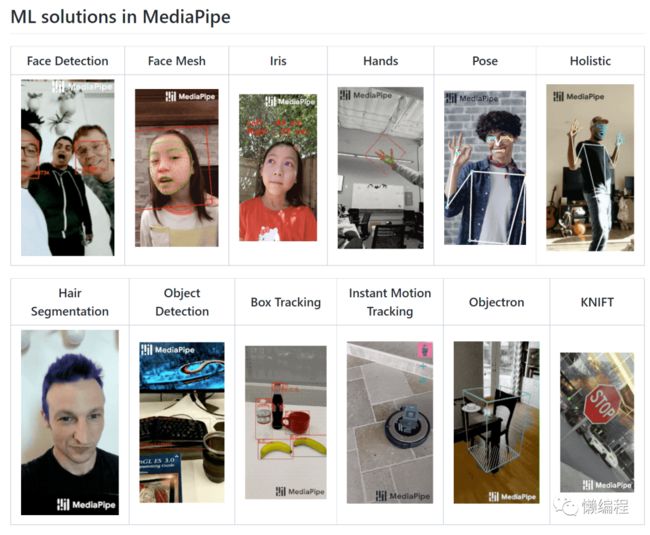
题外话,关于人体骨干、人脸、手势等各种部位的识别,请务必试试Google的mediapipe(https://github.com/google/mediapipe),简单几行代码便可实现各种复杂效果(可能的不足是,Python能支持的效果不算多)。
视频背景的替换
因为单纯的换脸过不了抖音的去重,所以我需要更进一步,我的想法是替换视频的背景,因为我处理的例子是知识类博主的口播视频,即背景是比较固定且内容与背景没啥关系的,所以替换背景是一个比较好的选择,市面上很多付费软件的做法是添加字幕、添加一些特效等等,我也参考着实现了,但这里还是先聊聊视频背景替换吧。
剪映有视频抠像功能,而视频背景的替换其实就是先通过抠像功能将视频中的人物扣取出来,然后再将新的背景视频合成上去,一个思路是自动化手机来利用剪映等工具批量导出抠像后的视频,再自己通过简单的代码将背景图与抠像视频合成在一起。
我这里走的是另个一个方案,使用视频抠像模型直接去处理视频,大家可以试试BackgroundMattingV2(https://github.com/PeterL1n/BackgroundMattingV2),它可以实现发丝级别的视频抠像,而且给出了预训练模型和colab,开箱即用。
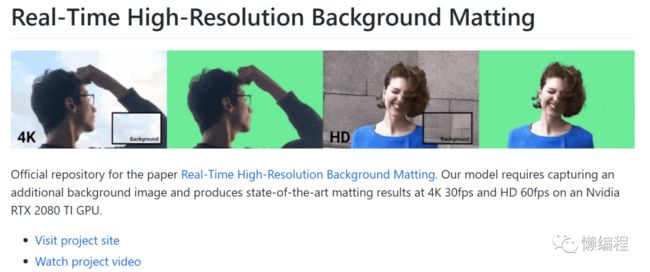
当然,也是存在问题的,最大的问题便是,没有提供完整抠像数据集。

训练一个好用的抠像模型,我们需要高质量的抠像数据集,这种数据集有较高的商业价值,不提供出来也可以理解,但这其实就限制了我们的使用,比如在处理带货的视频,因为训练数据集中缺失这部分抠像数据,所以抠出来的效果会失真,要优化,就只能自己花钱找外包去获得更多的抠像数据集。
在我个人的使用经验上,建议你选择画面比较简单的视频,比如口播类视频,从而实现较好的视频抠像效果。
最后我实现的效果如下,左边是对原视频换脸后的视频,右边是抠像后的视频,随后通过背景替换的逻辑便可以轻松给视频替换上不同的背景了。

唇语视频生成
相信你见过一些视频连说的话都是伪造出来的,这便是唇语生成技术,这类技术我测试使用下来,效果不太理解,其原因也是训练数据的缺失,我难以进一步优化,但你还是可看一下,少走一些弯路。
目前业界常用的是Wav2Lip(https://github.com/Rudrabha/Wav2Lip)模型,它可以对任何视频进行唇语生成与同步,简单而言,你获得一段音频和一个无声的视频作为Wav2Lip的输入,Wav2Lip便会给你一个处理后的视频,该视频使用音频的内容并且视频里人物的口型与音频内容相对应。
对于开源版本的Wav2Lip,受限于训练数据集,效果不太理想,但作者提供商业级别精度的模型,说明这事是可以以假乱真的。
我并没有联系作者,在多次使用后,发现如下一些问题:
1.口齿模糊,即牙齿无法清晰的展现出来

2.下巴可能会被削去
语音模仿
为了更进一步,我还尝试了语音模仿,举个简单的例子,我现在有一段周杰伦说话的音频,我想通过这个声音说一下我想让他说的内容,这里有2个技术点,一个是语音的模仿,另一个是文字生成语音(学术点,叫语音合成,TTS)。
关于音色模仿的项目,多数可以追溯到2019 Google提出的SV2TTS模型,这个模型可以提取音频中的特征从而学习音频中说话人的音色。关于文字生成语音的项目,多数使用了WaveNet模型。
对于中文语音而言,可以尝试MockingBird(https://github.com/babysor/MockingBird),只需5s原声音频,便可以实现音色模仿。
另外,我们也没啥其他可选的项目,其核心原因还是在于训练数据的缺失,目前公开的中文语音数据有aidatatang_200zh、magicdata、aishell3,但数据量还是不足,所以在同等技术水平下,难以做到像英文语音项目那样的效果。
MockingBird提供了Web测试版,你可以试用一下,因为数据量级的原因,对于那些包含情绪的声音,模型难以模仿。
题外话:
将虚假生成人脸、唇语生成和文字转语音结合起来便可以实现虚拟主播的效果,而百度基于其深度学习框架PaddlePaddle提供了完整的生态,百度的好处在于适应国情而且多数模型都提供了预训练模型,不需要自己再训练一遍,对于很多通用的任务这些预训练模型效果确实不错,这对很多中小型公司想使用AI来处理业务提供了一条非常低成本的路径,建议做老板的关注一下。
在PaddlePaddle生态中,可以通过PaddleGAN(https://github.com/PaddlePaddle/PaddleGAN)生成虚假人脸,再通过PaddleSpeech(https://github.com/PaddlePaddle/PaddleSpeech)实现文字转语音并生成唇语视频的效果,有人将其结合起来,构成了paddleBoBo(https://github.com/JiehangXie/PaddleBoBo)这个项目。
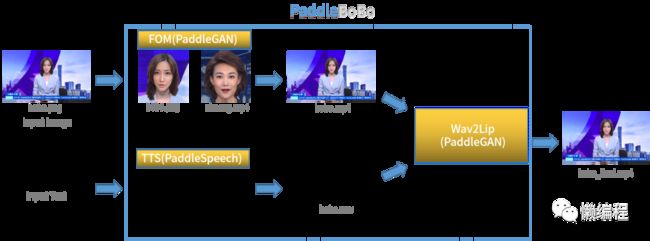
这个项目其实不能实用,因为离商业效果还有一定的距离,但可以作为一个baseline,在此之上,有心人可以魔改着看看,我自己魔改了一半,其难点还是在于唇语生成那块,数据量级不够,效果不够逼真。
结尾
我常听很多主播或言论提及学习英文的好处,你可以看到更广阔的的世界,你能在职场上走更远,这些其实都没有错,但相比于英文,我更建议你学习编程,看更广阔的的世界可以用机器翻译,其背后是NLP模型,是编程,职场想走更远可以使用自动化办公技术,其背后也是简单的编程原理。
我并不是说学英文不好,其好处很明显,但对于长时间生活在国内的你来说,学习编程从功利角度而言,其实是更好的选择,现在很多深度学习的项目不需要你懂他背后的数学原理,不需要懂它的编码实现,你只需要简单的编程知识(20%编程知识足以解决大部分问题),你就可以用起来了。这么多有趣的东西自己无法参与,多可惜,学编程吧,朋友们。
利益相关:本人副业是教编程的,可能是屁股决定了脑袋,请辩证看哈。
决定要学了,可以购买一本我出的《Python自动化办公》,有社群、有视频教程哦。
我是二两,我们下篇文章见。