自回归(AR)模型的功率谱估计
随机信号的参数模型
假定随机信号 x ( n ) x(n) x(n) 是由白噪声 w ( n ) w(n) w(n) 激励某一确定系统的响应。如下图所示:
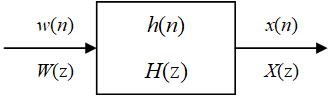
随机信号 x ( n ) x(n) x(n)、白噪声 w ( n ) w(n) w(n)和系统的冲击响应 h ( n ) h(n) h(n) 之间的关系为: x ( n ) = h ( n ) ∗ w ( n ) = ∑ k = − ∞ + ∞ h ( k ) w ( n − k ) x(n)=h(n)*w(n)=\sum^{+\infin}_{k=-\infin}h(k)w(n-k) x(n)=h(n)∗w(n)=k=−∞∑+∞h(k)w(n−k)其中, ∗ * ∗ 为卷积操作。如果确定白噪声 w ( n ) w(n) w(n) 的参数(假设为 a k a_k ak),也就相当于确定系统中的参数 h ( k ) h(k) h(k)。这样,就能将研究随机信号转化成研究产生随机信号的系统。
自回归滑动平均模型
在自回归滑动平均(Auto Regression Moving Average,ARMA)模型中,随机噪声 x ( n ) x(n) x(n) 由白噪声 w ( n ) w(n) w(n)、信号的若干过去值 x ( n − k ) x(n-k) x(n−k) 和若干激励值 w ( n − k ) w(n-k) w(n−k)线性组合而成。用线性差分方程表示为 x ( n ) + ∑ k = 1 p a k x ( n − k ) = w ( n ) + ∑ k = 1 p b k w ( n − k ) x(n)+\sum^p_{k=1}a_kx(n-k)=w(n)+\sum^p_{k=1}b_kw(n-k) x(n)+k=1∑pakx(n−k)=w(n)+k=1∑pbkw(n−k)对两边进行z变换,有: ∑ k = 0 p a k X ( z ) z − k = ∑ k = 0 p b k W ( z ) z − k \sum^p_{k=0}a_kX(z)z^{-k}=\sum^p_{k=0}b_kW(z)z^{-k} k=0∑pakX(z)z−k=k=0∑pbkW(z)z−k其中, a k a_k ak 为模型的参数,p为模型的阶数。系统函数为: H ( z ) = X ( z ) W ( z ) = ∑ k = 0 p b k z − k 1 + ∑ k = 1 p a k z − k H(z)=\frac{X(z)}{W(z)}=\frac{\displaystyle\sum^p_{k=0}b_kz^{-k}}{1+\displaystyle\sum^p_{k=1}a_kz^{-k}} H(z)=W(z)X(z)=1+k=1∑pakz−kk=0∑pbkz−k
滑动平均模型
在滑动平均(Moving Average,MR)模型中,随机信号 x ( n ) x(n) x(n) 由白噪声 w ( n ) w(n) w(n) 和若干激励值 w ( n − k ) w(n-k) w(n−k) 线性组合而成。用线性差分方程表示为: x ( n ) = w ( n ) + ∑ k = 1 p b k w ( n − k ) x(n)=w(n)+\sum^p_{k=1}b_kw(n-k) x(n)=w(n)+k=1∑pbkw(n−k)对两边进行z变换,有: X ( z ) = ∑ k = 0 p b k W ( z ) z − k X(z)=\sum^p_{k=0}b_kW(z)z^{-k} X(z)=k=0∑pbkW(z)z−k其中, a k a_k ak 为模型的参数,p为模型的阶数。系统函数为: H ( z ) = X ( z ) W ( z ) = X ( z ) = ∑ k = 0 p b k z − k H(z)=\frac{X(z)}{W(z)}=X(z)={\displaystyle\sum^p_{k=0}b_kz^{-k}} H(z)=W(z)X(z)=X(z)=k=0∑pbkz−k
自回归模型
在自回归(Auto Regression,AR)模型中,随机信号 x ( n ) x(n) x(n) 由白噪声 w ( n ) w(n) w(n) 和信号本身的若干次过去值 x ( n − k ) x(n-k) x(n−k) 线性组合而成。用线性差分方程表示为: x ( n ) + ∑ k = 1 p a k x ( n − k ) = w ( n ) x(n)+\sum^p_{k=1}a_kx(n-k)=w(n) x(n)+k=1∑pakx(n−k)=w(n)对两边进行z变换,有: ∑ k = 0 p a k X ( z ) z − k = W ( z ) \sum^p_{k=0}a_kX(z)z^{-k}=W(z) k=0∑pakX(z)z−k=W(z)其中, a k a_k ak 为模型的参数,p为模型的阶数。系统函数为: H ( z ) = X ( z ) W ( z ) = 1 W ( z ) = 1 1 + ∑ k = 1 p a k z − k H(z)=\frac {X(z)} {W(z)}=\frac {1}{W(z)}=\frac {1}{1+\displaystyle{\sum^p_{k=1}a_kz^{-k}}} H(z)=W(z)X(z)=W(z)1=1+k=1∑pakz−k1
自回归模型的参数估计
信号处理中的自相关函数,反映同一个信号在不同时刻取值间的相关程度。信号的自相关函数和信号的功率谱密度互为傅里叶变换,通过信号的自相关函数可以求得信号的功率谱密度。
随机噪声 x ( n ) x(n) x(n) 的自相关函数 R x x ( m ) R_{xx}(m) Rxx(m) 为: R x x ( m ) = E [ x ( n ) x ( n + m ) ] R_{xx}(m)=E[x(n)x(n+m)] Rxx(m)=E[x(n)x(n+m)]将随机信号 x ( n ) x(n) x(n) 的表达式代入,得: R x x ( m ) = E { x ( n ) [ w ( n + m ) − ∑ k = 1 p a k x ( n + m − k ) ] } = E [ x ( n ) w ( n + m ) ] − ∑ k = 1 p a k E [ x ( n ) x ( n + m − k ) ] = R x w ( m ) − ∑ k = 1 p a k R x x ( m − k ) \begin{aligned}R_{xx}(m)&=E\{x(n)[w(n+m)-\sum^p_{k=1}a_kx(n+m-k)]\}\\&=E[x(n)w(n+m)]-\sum^p_{k=1}a_kE[x(n)x(n+m-k)]\\&=R_{xw}(m)-\sum^p_{k=1}a_kR_{xx}(m-k)\end{aligned} Rxx(m)=E{x(n)[w(n+m)−k=1∑pakx(n+m−k)]}=E[x(n)w(n+m)]−k=1∑pakE[x(n)x(n+m−k)]=Rxw(m)−k=1∑pakRxx(m−k)由于 R x w ( m ) = { σ p 2 m=0 0 m>0 R_{xw}(m)=\begin{cases}\sigma^2_p&\text{m=0}\\0&\text{m>0}\end{cases} Rxw(m)={σp20m=0m>0则自相关函数 R x x ( m ) R_{xx}(m) Rxx(m) 可以表示为: R x x ( m ) = { σ p 2 − ∑ k = 1 p a k R x x ( m − k ) m=0 − ∑ k = 1 p a k R x x ( m − k ) m>0 R_{xx}(m)=\begin{cases}\sigma^2_p-\displaystyle\sum^p_{k=1}a_kR_{xx}(m-k)&\text{m=0}\\ -\displaystyle\sum^p_{k=1}a_kR_{xx}(m-k) &\text{m>0}\end{cases} Rxx(m)=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧σp2−k=1∑pakRxx(m−k)−k=1∑pakRxx(m−k)m=0m>0 其中, m = 0 , 1 , . . . , p m=0,1,...,p m=0,1,...,p。用矩阵(Yule-Walker方程)可以表示为: [ R x x ( 0 ) R x x ( − 1 ) ⋯ R x x ( − p ) R x x ( 1 ) R x x ( 0 ) ⋯ R x x ( 1 − p ) ⋮ ⋮ ⋱ ⋮ R x x ( p ) R x x ( p − 1 ) ⋯ R x x ( 0 ) ] [ 1 a 1 ⋮ a p ] = [ σ p 2 0 ⋮ 0 ] \begin{bmatrix} R_{xx}(0)&R_{xx}(-1)&\cdots&R_{xx}(-p)\\ R_{xx}(1)&R_{xx}(0)&\cdots&R_{xx}(1-p)\\ \vdots&\vdots&\ddots&\vdots\\ R_{xx}(p)&R_{xx}(p-1)&\cdots&R_{xx}(0)\\ \end{bmatrix} \begin{bmatrix} 1\\ a_1\\ \vdots\\ a_p \end{bmatrix}= \begin{bmatrix} \sigma^2_p\\ 0\\ \vdots\\ 0\\ \end{bmatrix} ⎣⎢⎢⎢⎡Rxx(0)Rxx(1)⋮Rxx(p)Rxx(−1)Rxx(0)⋮Rxx(p−1)⋯⋯⋱⋯Rxx(−p)Rxx(1−p)⋮Rxx(0)⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡1a1⋮ap⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡σp20⋮0⎦⎥⎥⎥⎤目前,求解Yule-Walker方程的方法主要有Yule-Walker法、Levinson-Durbin法、Burg法、协方差法和修正协方差法这五种,这五种方法有各自的优缺点。下面分别介绍这五种方法:
Yule-Walker法(预测误差最小)
对于预测模型,假设第n个数据 x ( n ) x(n) x(n) 是由前p个数据 x ( n − p ) , x ( n − p + 1 ) , . . . , x ( n − 1 ) x(n-p),x(n-p+1),...,x(n-1) x(n−p),x(n−p+1),...,x(n−1) 预测得到的。即: x ^ ( n ) = − ∑ k = 1 p a k x ( n − k ) \hat{x}(n)=-\sum^p_{k=1}a_kx(n-k) x^(n)=−k=1∑pakx(n−k)那么预测误差 e ( n ) e(n) e(n) 为: e ( n ) = x ( n ) + x ^ ( n ) = x ( n ) + ∑ k = 1 p a k x ( n − k ) e(n)=x(n)+\hat{x}(n)=x(n)+\sum^p_{k=1}a_kx(n-k) e(n)=x(n)+x^(n)=x(n)+k=1∑pakx(n−k)而对于自回归(AR)模型而言,有: w ( n ) = x ( n ) + ∑ k = 1 p a k x ( n − k ) w(n)=x(n)+\sum^p_{k=1}a_kx(n-k) w(n)=x(n)+k=1∑pakx(n−k)如果自回归模型和预测模型的系数 a k a_k ak 相同,那么预测误差 e ( n ) e(n) e(n) 就等于白噪声 w ( n ) w(n) w(n)。因此,Yule-Walker法的基本思想就是计算预测误差功率 ρ e \rho_e ρe 最小时模型的预测系数 a k a_k ak: ρ e = 1 N E [ e 2 ( n ) ] = 1 N E [ x ( n ) + ∑ k = 1 p a k x ( n − k ) ] 2 \rho_e=\frac 1 N E[e^2(n)]=\frac{1}{N}E[x(n)+\sum^p_{k=1}a_kx(n-k)]^2 ρe=N1E[e2(n)]=N1E[x(n)+k=1∑pakx(n−k)]2为了使预测误差功率最小,有: ∂ ρ e ∂ a k = ∂ E [ e 2 ( n ) ] ∂ a k = 0 \frac{\partial{\rho_e}}{\partial a_k}=\frac{\partial{E[e^2(n)}]}{\partial a_k}=0 ∂ak∂ρe=∂ak∂E[e2(n)]=0而 E [ e 2 ( n ) ] = E { [ x ( n ) + ∑ k = 1 p a k x ( n − k ) ] 2 } = E [ x 2 ( n ) ] + 2 ∑ k = 1 p a k E [ x ( n ) x ( n − k ) ] + ∑ i = 1 p a i ∑ k = 1 p a k E [ x ( n − i ) x ( n − k ) ] = R x x ( 0 ) + 2 ∑ k = 1 p a k R x x ( k ) + ∑ i = 1 p a i ∑ k = 1 p a k R x x ( i − k ) \begin{aligned}E[e^2(n)]&=E\{[x(n)+\sum^p_{k=1}a_kx(n-k)]^2\}\\&=E{[x^2(n)]}+2\sum^p_{k=1}a_kE[x(n)x(n-k)]+\sum^p_{i=1}a_i\sum^p_{k=1}a_kE[x(n-i)x(n-k)]\\&=R_{xx}(0)+2\sum^p_{k=1}a_kR_{xx}(k)+\sum^p_{i=1}a_i\sum^p_{k=1}a_kR_{xx}(i-k)\end{aligned} E[e2(n)]=E{[x(n)+k=1∑pakx(n−k)]2}=E[x2(n)]+2k=1∑pakE[x(n)x(n−k)]+i=1∑paik=1∑pakE[x(n−i)x(n−k)]=Rxx(0)+2k=1∑pakRxx(k)+i=1∑paik=1∑pakRxx(i−k)则有: ∂ E [ e 2 ( n ) ] ∂ a k = 2 R x x ( k ) + 2 ∑ i = 1 p a i R x x ( i − k ) = 0 \frac{\partial{E[e^2(n)}]}{\partial a_k}=2R_{xx}(k)+2\sum^p_{i=1}a_iR_{xx}(i-k)=0 ∂ak∂E[e2(n)]=2Rxx(k)+2i=1∑paiRxx(i−k)=0即: ∑ i = 1 p a i R x x ( i − k ) = − R x x ( k ) \sum^p_{i=1}a_iR_{xx}(i-k)=-R_{xx}(k) i=1∑paiRxx(i−k)=−Rxx(k)其中, k = 1 , 2 , . . . , p k=1,2,...,p k=1,2,...,p。写成矩阵形式: [ R x x ( 0 ) R x x ( 1 ) ⋯ R x x ( p − 1 ) R x x ( − 1 ) R x x ( 0 ) ⋯ R x x ( p − 2 ) ⋮ ⋮ ⋱ ⋮ R x x ( 1 − p ) R x x ( 2 − p ) ⋯ R x x ( 0 ) ] [ a 1 a 2 ⋮ a p ] = [ − R x x ( 1 ) − R x x ( 2 ) ⋮ − R x x ( p ) ] \begin{bmatrix} R_{xx}(0)&R_{xx}(1)&\cdots&R_{xx}(p-1)\\ R_{xx}(-1)&R_{xx}(0)&\cdots&R_{xx}(p-2)\\ \vdots&\vdots&\ddots&\vdots\\ R_{xx}(1-p)&R_{xx}(2-p)&\cdots&R_{xx}(0)\\ \end{bmatrix} \begin{bmatrix} a_1\\ a_2\\ \vdots\\ a_p \end{bmatrix}= \begin{bmatrix} -R_{xx}(1)\\ -R_{xx}(2)\\ \vdots\\ -R_{xx}(p)\\ \end{bmatrix} ⎣⎢⎢⎢⎡Rxx(0)Rxx(−1)⋮Rxx(1−p)Rxx(1)Rxx(0)⋮Rxx(2−p)⋯⋯⋱⋯Rxx(p−1)Rxx(p−2)⋮Rxx(0)⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡a1a2⋮ap⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡−Rxx(1)−Rxx(2)⋮−Rxx(p)⎦⎥⎥⎥⎤
则预测系数 a k a_k ak 可以表示成: [ a 1 a 2 ⋮ a p ] = [ R x x ( 0 ) R x x ( 1 ) ⋯ R x x ( p − 1 ) R x x ( − 1 ) R x x ( 0 ) ⋯ R x x ( p − 2 ) ⋮ ⋮ ⋱ ⋮ R x x ( 1 − p ) R x x ( 2 − p ) ⋯ R x x ( 0 ) ] − 1 [ − R x x ( 1 ) − R x x ( 2 ) ⋮ − R x x ( p ) ] \begin{bmatrix} a_1\\ a_2\\ \vdots\\ a_p \end{bmatrix}= \begin{bmatrix} R_{xx}(0)&R_{xx}(1)&\cdots&R_{xx}(p-1)\\ R_{xx}(-1)&R_{xx}(0)&\cdots&R_{xx}(p-2)\\ \vdots&\vdots&\ddots&\vdots\\ R_{xx}(1-p)&R_{xx}(2-p)&\cdots&R_{xx}(0)\\ \end{bmatrix}^{-1} \begin{bmatrix} -R_{xx}(1)\\ -R_{xx}(2)\\ \vdots\\ -R_{xx}(p)\\ \end{bmatrix} ⎣⎢⎢⎢⎡a1a2⋮ap⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡Rxx(0)Rxx(−1)⋮Rxx(1−p)Rxx(1)Rxx(0)⋮Rxx(2−p)⋯⋯⋱⋯Rxx(p−1)Rxx(p−2)⋮Rxx(0)⎦⎥⎥⎥⎤−1⎣⎢⎢⎢⎡−Rxx(1)−Rxx(2)⋮−Rxx(p)⎦⎥⎥⎥⎤
然后根据模型的系数 a k a_k ak求 σ p 2 \sigma^2_p σp2: σ p 2 = R x x ( 0 ) + ∑ k = 1 p a k R x x ( − k ) \sigma^2_p=R_{xx}(0)+\sum^p_{k=1}a_kR_{xx}(-k) σp2=Rxx(0)+k=1∑pakRxx(−k)
Levinson-Durbin法(递归)
假设 p p p 阶自回归模型的系数为 a p k a_{pk} apk,其中 p p p 表示此时自回归模型的阶数,也就是当前阶数情况下总共有几个系数, k k k 表示当前系数的序列索引。对于Yule-Walker方程,
当 p = 1 p=1 p=1 时,有: [ R x x ( 0 ) R x x ( 1 ) R x x ( 1 ) R x x ( 0 ) ] [ 1 a 11 ] = [ σ 1 2 0 ] \begin{bmatrix} R_{xx}(0)&R_{xx}(1)\\ R_{xx}(1)&R_{xx}(0)\\ \end{bmatrix} \begin{bmatrix} 1\\ a_{11}\\ \end{bmatrix}= \begin{bmatrix} \sigma^2_1\\ 0\\ \end{bmatrix} [Rxx(0)Rxx(1)Rxx(1)Rxx(0)][1a11]=[σ120]解得: a 11 = − R x x ( 1 ) R x x ( 0 ) a_{11}=-\frac{R_{xx}(1)}{R_{xx}(0)} a11=−Rxx(0)Rxx(1) σ 1 2 = ( 1 − ∣ a 11 ∣ 2 ) R x x ( 0 ) \sigma^2_1=(1-|a_{11}|^2)R_{xx}(0) σ12=(1−∣a11∣2)Rxx(0)当 p = 2 p=2 p=2 时,有: [ R x x ( 0 ) R x x ( 1 ) R x x ( 2 ) R x x ( 1 ) R x x ( 0 ) R x x ( 1 ) R x x ( 2 ) R x x ( 1 ) R x x ( 0 ) ] [ 1 a 21 a 22 ] = [ σ 2 2 0 0 ] \begin{bmatrix} R_{xx}(0)&R_{xx}(1)&R_{xx}(2)\\ R_{xx}(1)&R_{xx}(0)&R_{xx}(1)\\ R_{xx}(2)&R_{xx}(1)&R_{xx}(0)\\ \end{bmatrix} \begin{bmatrix} 1\\ a_{21}\\ a_{22}\\ \end{bmatrix}= \begin{bmatrix} \sigma^2_2\\ 0\\ 0\\ \end{bmatrix} ⎣⎡Rxx(0)Rxx(1)Rxx(2)Rxx(1)Rxx(0)Rxx(1)Rxx(2)Rxx(1)Rxx(0)⎦⎤⎣⎡1a21a22⎦⎤=⎣⎡σ2200⎦⎤解得: a 22 = − R x x ( 2 ) − a 11 R x x ( 1 ) σ 1 2 a_{22}=-\frac{R_{xx}(2)-a_{11}R_{xx}(1)}{\sigma^2_1} a22=−σ12Rxx(2)−a11Rxx(1) a 21 = a 11 + a 22 a 11 a_{21}=a_{11}+a_{22}a_{11} a21=a11+a22a11 σ 2 2 = ( 1 − ∣ a 22 ∣ 2 σ 1 2 ) \sigma^2_2=(1-|a_{22}|^2\sigma^2_1) σ22=(1−∣a22∣2σ12)推广到 k k k 阶时,有: a k k = − R x x ( k ) − ∑ l = 1 k − 1 a k − 1 , l R x x ( k − l ) σ k − 1 2 a_{kk}=-\frac{R_{xx}(k)-\displaystyle\sum^{k-1}_{l=1}a_{k-1,l}R_{xx}(k-l)}{\sigma^2_{k-1}} akk=−σk−12Rxx(k)−l=1∑k−1ak−1,lRxx(k−l) a k i = a k − 1 , i + a k k a k − 1 , k − i , i = 1 , 2 , . . . , k − 1 a_{ki}=a_{k-1,i}+a_{kk}a_{k-1,k-i},i=1,2,...,k-1 aki=ak−1,i+akkak−1,k−i,i=1,2,...,k−1 σ k 2 = ( 1 − ∣ a k k ∣ 2 ) σ k − 1 2 , σ 0 2 = R x x ( 0 ) \sigma^2_k=(1-|a_{kk}|^2)\sigma^2_{k-1},\sigma^2_0=R_{xx}(0) σk2=(1−∣akk∣2)σk−12,σ02=Rxx(0)Levinson-Durbin法的基本思想就是通过递归到所需要的阶数时,求得所估计的模型系数 a p i , i = 1 , 2 , . . . , k a_{pi},i=1,2,...,k api,i=1,2,...,k 和 σ p 2 \sigma^2_p σp2。
Burg法(前后向平均预测误差最小+递归)
对于预测模型,假设随机信号 x ( n ) x(n) x(n) 是由前 p p p 个数据 x ( n − p ) , x ( n − p + 1 ) , . . . , x ( n − 1 ) x(n-p),x(n-p+1),...,x(n-1) x(n−p),x(n−p+1),...,x(n−1) 预测得到的: x ^ ( n ) = − ∑ k = 1 p a p k x ( n − k ) \hat{x}(n)=-\sum^p_{k=1}a_{pk}x(n-k) x^(n)=−k=1∑papkx(n−k)则预测误差 e p ( n ) e_p(n) ep(n) 为: e p ( n ) = x ( n ) − x ^ ( n ) = x ( n ) + ∑ k = 1 p a p k x ( n − k ) e_p(n)=x(n)-\hat{x}(n)=x(n)+\sum^p_{k=1}a_{pk}x(n-k) ep(n)=x(n)−x^(n)=x(n)+k=1∑papkx(n−k)而随机信号 x ( n − p ) x(n-p) x(n−p) 是由后 p p p 个数据 x ( n − p + 1 ) , x ( n − p + 2 ) , . . . , x ( n ) x(n-p+1),x(n-p+2),...,x(n) x(n−p+1),x(n−p+2),...,x(n) 预测得到的: x ^ ( n − p ) = − ∑ k = 1 p a p k x ( n − p + k ) \hat{x}(n-p)=-\sum^p_{k=1}a_{pk}x(n-p+k) x^(n−p)=−k=1∑papkx(n−p+k)则预测误差 b p ( n ) b_p(n) bp(n) 为: b p ( n ) = x ( n − p ) − x ^ ( n − p ) = x ( n − p ) + ∑ k = 1 p a p k x ( n − p + k ) b_p(n)=x(n-p)-\hat{x}(n-p)=x(n-p)+\sum^p_{k=1}a_{pk}x(n-p+k) bp(n)=x(n−p)−x^(n−p)=x(n−p)+k=1∑papkx(n−p+k)称 e p ( n ) e_p(n) ep(n) 和 b p ( n ) b_p(n) bp(n) 分别为前向预测误差和后向预测误差。Burg法的基本思想就是递归地求前后向预测误差平均功率 ρ p \rho_p ρp 最小时的反射系数 K p = a p p K_p=a_{pp} Kp=app,然后再根据反射系数 K p K_p Kp 求模型的参数 a p k a_{pk} apk 和 σ p 2 \sigma^2_{p} σp2。
假设随机信号 x ( n ) x(n) x(n) 的观测区间为 0 ≤ n ≤ N − 1 0\le n\le N-1 0≤n≤N−1,则前向预测功率 ρ p e \rho_{pe} ρpe、后向预测功率 ρ p b \rho_{pb} ρpb 和平均预测功率 ρ p \rho_{p} ρp 分别为: ρ p e = 1 N − p ∑ n = p N − 1 ∣ e p ( n ) ∣ 2 = 1 N − p ∑ n = p N − 1 ∣ x ( n ) + ∑ k = 1 p a p k x ( n − k ) ∣ 2 \rho_{pe}=\frac{1}{N-p}\sum^{N-1}_{n=p}|e_p(n)|^2=\frac{1}{N-p}\sum^{N-1}_{n=p}|x(n)+\sum^p_{k=1}a_{pk}x(n-k)|^2 ρpe=N−p1n=p∑N−1∣ep(n)∣2=N−p1n=p∑N−1∣x(n)+k=1∑papkx(n−k)∣2 ρ p b = 1 N − p ∑ n = p N − 1 ∣ b p ( n ) ∣ 2 = 1 N − p ∑ n = p N − 1 ∣ x ( n − p ) + ∑ k = 1 p a p k x ( n − p + k ) ∣ 2 \rho_{pb}=\frac{1}{N-p}\sum^{N-1}_{n=p}|b_p(n)|^2=\frac{1}{N-p}\sum^{N-1}_{n=p}|x(n-p)+\sum^p_{k=1}a_{pk}x(n-p+k)|^2 ρpb=N−p1n=p∑N−1∣bp(n)∣2=N−p1n=p∑N−1∣x(n−p)+k=1∑papkx(n−p+k)∣2 ρ p = 1 2 ( ρ p e + ρ p b ) \rho_p=\frac{1}{2}(\rho_{pe}+\rho_{pb}) ρp=21(ρpe+ρpb)当反射系数最小时,有: ∂ ρ p ∂ K p = 0 \frac{\partial{\rho_p}}{\partial{K_p}}=0 ∂Kp∂ρp=0解得: K p = a p p = − 2 ∑ n = p N − 1 [ e p − 1 ( n ) b p − 1 ( n − 1 ) ] ∑ n = p N − 1 [ e p − 1 2 ( n ) + b p − 1 2 ( n − 1 ) ] K_p=a_{pp}=\frac{-2\displaystyle\sum^{N-1}_{n=p}[e_{p-1}(n)b_{p-1}(n-1)]}{\displaystyle\sum^{N-1}_{n=p}[e^2_{p-1}(n)+b^2_{p-1}(n-1)]} Kp=app=n=p∑N−1[ep−12(n)+bp−12(n−1)]−2n=p∑N−1[ep−1(n)bp−1(n−1)]由于 e 0 ( n ) = b 0 ( n ) = x ( n ) e_0(n)=b_0(n)=x(n) e0(n)=b0(n)=x(n),且前向预测误差和后向预测误差分别存在递推公式: e p ( n ) = e p − 1 ( n ) + K p b p − 1 ( n − 1 ) e_p(n)=e_{p-1}(n)+K_pb_{p-1}(n-1) ep(n)=ep−1(n)+Kpbp−1(n−1) b p ( n ) = b p − 1 ( n − 1 ) + K p e p − 1 ( n ) b_p(n)=b_{p-1}(n-1)+K_pe_{p-1}(n) bp(n)=bp−1(n−1)+Kpep−1(n)故可以根据反射系数 K p K_p Kp 递推地求出模型的参数 a p i a_{pi} api 和 σ p 2 \sigma^2_p σp2,有: a p i = a p − 1 , i + K p a p − 1 , p − i , i = 1 , 2 , . . . , p − 1 a_{pi}=a_{p-1,i}+K_pa_{p-1,p-i},i=1,2,...,p-1 api=ap−1,i+Kpap−1,p−i,i=1,2,...,p−1 σ p 2 = ( 1 − K p 2 ) σ p − 1 2 \sigma^2_p=(1-K_p^2)\sigma^2_{p-1} σp2=(1−Kp2)σp−12
协方差法(预测误差最小)
协方差法和Yule-Walker法都是通过最小化预测功率求模型的参数。但不同于Yule-Walker法,协方差法的预测功率为: ρ e = 1 N − p ∑ n = p N − 1 ∣ e 2 ( n ) ∣ = 1 N − p ∑ n = p N − 1 ∣ x ( n ) + ∑ k = 1 p a p k x ( n − k ) ∣ 2 \rho_e=\frac{1}{N-p}\sum^{N-1}_{n=p}|e^2(n)|=\frac{1}{N-p}\sum^{N-1}_{n=p}|x(n)+\sum^p_{k=1}a_{pk}x(n-k)|^2 ρe=N−p1n=p∑N−1∣e2(n)∣=N−p1n=p∑N−1∣x(n)+k=1∑papkx(n−k)∣2当预测功率最小时,有: ∂ ρ e ∂ a p k = 1 N − p ∑ n = p N − 1 [ x ( n ) + ∑ k = 1 p a p k x ( n − k ) ] x ( n − l ) = 0 \frac{\partial{\rho_e}}{\partial{a_{pk}}}=\frac{1}{N-p}\sum^{N-1}_{n=p}[x(n)+\sum^p_{k=1}a_{pk}x(n-k)]x(n-l)=0 ∂apk∂ρe=N−p1n=p∑N−1[x(n)+k=1∑papkx(n−k)]x(n−l)=0其中, l = 1 , 2 , . . . , p l=1,2,...,p l=1,2,...,p。用 c ^ x x ( k , l ) \hat{c}_{xx}(k,l) c^xx(k,l) 来表示上式,得: ∑ k = 1 p a p k c ^ x x ( l , k ) = − c ^ x x ( l , 0 ) \sum^p_{k=1}a_{pk}\hat{c}_{xx}(l,k)=-\hat{c}_{xx}(l,0) k=1∑papkc^xx(l,k)=−c^xx(l,0)其中: c ^ x x ( k , l ) = { 1 N − p ∑ n = p N − 1 [ x ( n − k ) x ( n − l ) ] c ^ x x ( l , k ) \hat{c}_{xx}(k,l)=\begin{cases}\displaystyle\frac{1}{N-p}\sum^{N-1}_{n=p}[x(n-k)x(n-l)]\\\hat{c}_{xx}(l,k)\end{cases} c^xx(k,l)=⎩⎪⎨⎪⎧N−p1n=p∑N−1[x(n−k)x(n−l)]c^xx(l,k)写成矩阵形式为: [ c ^ x x ( 1 , 1 ) c ^ x x ( 1 , 2 ) ⋯ c ^ x x ( 1 , p ) c ^ x x ( 2 , 1 ) c ^ x x ( 2 , 2 ) ⋯ c ^ x x ( 2 , p ) ⋮ ⋮ ⋱ ⋮ c ^ x x ( p , 1 ) c ^ x x ( p , 2 ) ⋯ c ^ x x ( p , p ) ] [ a p 1 a p 2 ⋮ a p p ] = [ − c ^ x x ( 1 , 0 ) − c ^ x x ( 2 , 0 ) ⋮ − c ^ x x ( p , 0 ) ] \begin{bmatrix} \hat{c}_{xx}(1,1)&\hat{c}_{xx}(1,2)&\cdots&\hat{c}_{xx}(1,p)\\ \hat{c}_{xx}(2,1)&\hat{c}_{xx}(2,2)&\cdots&\hat{c}_{xx}(2,p)\\ \vdots&\vdots&\ddots&\vdots\\ \hat{c}_{xx}(p,1)&\hat{c}_{xx}(p,2)&\cdots&\hat{c}_{xx}(p,p)\\ \end{bmatrix} \begin{bmatrix} a_{p1}\\ a_{p2}\\ \vdots\\ a_{pp}\\ \end{bmatrix}= \begin{bmatrix} -\hat{c}_{xx}(1,0)\\ -\hat{c}_{xx}(2,0)\\ \vdots\\ -\hat{c}_{xx}(p,0)\\ \end{bmatrix} ⎣⎢⎢⎢⎡c^xx(1,1)c^xx(2,1)⋮c^xx(p,1)c^xx(1,2)c^xx(2,2)⋮c^xx(p,2)⋯⋯⋱⋯c^xx(1,p)c^xx(2,p)⋮c^xx(p,p)⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡ap1ap2⋮app⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡−c^xx(1,0)−c^xx(2,0)⋮−c^xx(p,0)⎦⎥⎥⎥⎤则可以求出模型的参数 a p k a_{pk} apk: [ a p 1 a p 2 ⋮ a p p ] = [ c ^ x x ( 1 , 1 ) c ^ x x ( 1 , 2 ) ⋯ c ^ x x ( 1 , p ) c ^ x x ( 2 , 1 ) c ^ x x ( 2 , 2 ) ⋯ c ^ x x ( 2 , p ) ⋮ ⋮ ⋱ ⋮ c ^ x x ( p , 1 ) c ^ x x ( p , 2 ) ⋯ c ^ x x ( p , p ) ] − 1 [ − c ^ x x ( 1 , 0 ) − c ^ x x ( 2 , 0 ) ⋮ − c ^ x x ( p , 0 ) ] \begin{bmatrix} a_{p1}\\ a_{p2}\\ \vdots\\ a_{pp}\\ \end{bmatrix}= \begin{bmatrix} \hat{c}_{xx}(1,1)&\hat{c}_{xx}(1,2)&\cdots&\hat{c}_{xx}(1,p)\\ \hat{c}_{xx}(2,1)&\hat{c}_{xx}(2,2)&\cdots&\hat{c}_{xx}(2,p)\\ \vdots&\vdots&\ddots&\vdots\\ \hat{c}_{xx}(p,1)&\hat{c}_{xx}(p,2)&\cdots&\hat{c}_{xx}(p,p)\\ \end{bmatrix}^{-1} \begin{bmatrix} -\hat{c}_{xx}(1,0)\\ -\hat{c}_{xx}(2,0)\\ \vdots\\ -\hat{c}_{xx}(p,0)\\ \end{bmatrix} ⎣⎢⎢⎢⎡ap1ap2⋮app⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡c^xx(1,1)c^xx(2,1)⋮c^xx(p,1)c^xx(1,2)c^xx(2,2)⋮c^xx(p,2)⋯⋯⋱⋯c^xx(1,p)c^xx(2,p)⋮c^xx(p,p)⎦⎥⎥⎥⎤−1⎣⎢⎢⎢⎡−c^xx(1,0)−c^xx(2,0)⋮−c^xx(p,0)⎦⎥⎥⎥⎤
σ p 2 \sigma^2_p σp2 的估计值: σ p 2 = ρ m i n = 1 N − p ∑ n = p N − 1 [ x ( n ) + ∑ k = 1 p a p k x ( n − k ) ] [ x ( n ) + ∑ l = 1 p a p k x ( n − l ) ] = 1 N − p ∑ n = p N − 1 [ x ( n ) + ∑ k = 1 p a p k x ( n − k ) ] x ( n ) = c ^ x x ( 0 , 0 ) + ∑ k = 1 p a p k c ^ x x ( 0 , k ) \begin{aligned}\sigma^2_p=\rho_{min}&=\frac{1}{N-p}\sum^{N-1}_{n=p}[x(n)+\sum^p_{k=1}a_{pk}x(n-k)][x(n)+\sum^p_{l=1}a_{pk}x(n-l)]\\&=\frac{1}{N-p}\sum^{N-1}_{n=p}[x(n)+\sum^p_{k=1}a_{pk}x(n-k)]x(n)\\&=\hat{c}_{xx}(0,0)+\sum^p_{k=1}a_{pk}\hat{c}_{xx}(0,k)\end{aligned} σp2=ρmin=N−p1n=p∑N−1[x(n)+k=1∑papkx(n−k)][x(n)+l=1∑papkx(n−l)]=N−p1n=p∑N−1[x(n)+k=1∑papkx(n−k)]x(n)=c^xx(0,0)+k=1∑papkc^xx(0,k)可以将参数 a p k a_{pk} apk 和 σ p 2 \sigma^2_p σp2 的求解合并在一个矩阵中,有: [ c ^ x x ( 0 , 0 ) c ^ x x ( 0 , 1 ) ⋯ c ^ x x ( 0 , p ) c ^ x x ( 1 , 0 ) c ^ x x ( 1 , 1 ) ⋯ c ^ x x ( 1 , p ) ⋮ ⋮ ⋱ ⋮ c ^ x x ( p , 0 ) c ^ x x ( p , 1 ) ⋯ c ^ x x ( p , p ) ] [ 1 a p 1 ⋮ a p p ] = [ σ p 2 0 ⋮ 0 ] \begin{bmatrix} \hat{c}_{xx}(0,0)&\hat{c}_{xx}(0,1)&\cdots&\hat{c}_{xx}(0,p)\\ \hat{c}_{xx}(1,0)&\hat{c}_{xx}(1,1)&\cdots&\hat{c}_{xx}(1,p)\\ \vdots&\vdots&\ddots&\vdots\\ \hat{c}_{xx}(p,0)&\hat{c}_{xx}(p,1)&\cdots&\hat{c}_{xx}(p,p)\\ \end{bmatrix} \begin{bmatrix} 1\\ a_{p1}\\ \vdots\\ a_{pp}\\ \end{bmatrix}= \begin{bmatrix} \sigma^2_p\\ 0\\ \vdots\\ 0\\ \end{bmatrix} ⎣⎢⎢⎢⎡c^xx(0,0)c^xx(1,0)⋮c^xx(p,0)c^xx(0,1)c^xx(1,1)⋮c^xx(p,1)⋯⋯⋱⋯c^xx(0,p)c^xx(1,p)⋮c^xx(p,p)⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡1ap1⋮app⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡σp20⋮0⎦⎥⎥⎥⎤
修正协方差法(前后向平均预测误差最小)
修正的协方差法与Burg法类似,使用前后向预测平均误差最小的方法来估计自回归模型的参数。但不同于Burg法,修正的协方差法的后向预测误差 b p ( n ) b_p(n) bp(n) 与Burg法中的后向预测误差不一样。
假设随机信号 x ( n ) x(n) x(n) 是由前 p p p 个数据 x ( n − p ) , x ( n − p + 1 ) , . . . , x ( n − 1 ) x(n-p),x(n-p+1),...,x(n-1) x(n−p),x(n−p+1),...,x(n−1) 预测得到的,则有: x ^ ( n ) = − ∑ k = 1 p a p k x ( n − k ) \hat{x}(n)=-\sum^p_{k=1}a_{pk}x(n-k) x^(n)=−k=1∑papkx(n−k)在修正的协方差法中,前向预测误差 e p ( n ) e_p(n) ep(n) 与Burg法中的前向预测误差一致: e p ( n ) = x ( n ) − x ^ ( n ) = x ( n ) + ∑ k = 1 p a p k x ( n − k ) e_p(n)=x(n)-\hat{x}(n)=x(n)+\sum^p_{k=1}a_{pk}x(n-k) ep(n)=x(n)−x^(n)=x(n)+k=1∑papkx(n−k)对于后向预测误差 b p ( n ) b_p(n) bp(n),假设随机信号 x ( n ) x(n) x(n) 是由后 p p p 个数据 x ( n + 1 ) , x ( n + 2 ) , . . . , x ( n + p ) x(n+1),x(n+2),...,x(n+p) x(n+1),x(n+2),...,x(n+p) 预测得到的: x ^ ( n ) = − ∑ k = 1 p a p k x ( n + k ) \hat{x}(n)=-\sum^p_{k=1}a_{pk}x(n+k) x^(n)=−k=1∑papkx(n+k)那么,后向预测误差 b p ( n ) b_p(n) bp(n) 可以表示为: b p ( n ) = x ( n ) − x ^ ( n ) = x ( n ) + ∑ k = 1 p a p k x ( n + k ) b_p(n)=x(n)-\hat{x}(n)=x(n)+\sum^p_{k=1}a_{pk}x(n+k) bp(n)=x(n)−x^(n)=x(n)+k=1∑papkx(n+k)假设随机信号 x ( n ) x(n) x(n) 的观测区间为 0 ≤ n ≤ N − 1 0\le n\le N-1 0≤n≤N−1,则前向预测功率 ρ p e \rho_{pe} ρpe、后向预测功率 ρ p b \rho_{pb} ρpb 和平均预测功率 ρ p \rho_{p} ρp 可以分别表示为: ρ p e = 1 N − p ∑ n = p N − 1 ∣ e p ( n ) ∣ 2 = 1 N − p ∑ n = p N − 1 ∣ x ( n ) + ∑ k = 1 p a p k x ( n − k ) ∣ 2 \rho_{pe}=\frac{1}{N-p}\sum^{N-1}_{n=p}|e_p(n)|^2=\frac{1}{N-p}\sum^{N-1}_{n=p}|x(n)+\sum^p_{k=1}a_{pk}x(n-k)|^2 ρpe=N−p1n=p∑N−1∣ep(n)∣2=N−p1n=p∑N−1∣x(n)+k=1∑papkx(n−k)∣2 ρ p b = 1 N − p ∑ n = 0 N − 1 − p ∣ b p ( n ) ∣ 2 = 1 N − p ∑ n = 0 N − 1 − p ∣ x ( n ) + ∑ k = 1 p a p k x ( n + k ) ∣ 2 \rho_{pb}=\frac{1}{N-p}\sum^{N-1-p}_{n=0}|b_p(n)|^2=\frac{1}{N-p}\sum^{N-1-p}_{n=0}|x(n)+\sum^p_{k=1}a_{pk}x(n+k)|^2 ρpb=N−p1n=0∑N−1−p∣bp(n)∣2=N−p1n=0∑N−1−p∣x(n)+k=1∑papkx(n+k)∣2 ρ p = 1 2 ( ρ p e + ρ p b ) \rho_p=\frac{1}{2}(\rho_{pe}+\rho_{pb}) ρp=21(ρpe+ρpb)要使平均误差功率 ρ p \rho_p ρp 最小,则: ∂ ρ p ∂ a p k = 1 N − p { ∑ n = p N − 1 [ x ( n ) + ∑ k = 1 p a p k x ( n − k ) ] x ( n − l ) + ∑ n = 0 N − 1 − p [ x ( n ) + ∑ k = 1 p a p k x ( n + k ) ] x ( n + l ) } = 0 \frac{\partial{\rho_p}}{\partial{a_{pk}}}=\frac{1}{N-p}\{\sum^{N-1}_{n=p}[x(n)+\sum^p_{k=1}a_{pk}x(n-k)]x(n-l)+\sum^{N-1-p}_{n=0}[x(n)+\sum^p_{k=1}a_{pk}x(n+k)]x(n+l)\}=0 ∂apk∂ρp=N−p1{n=p∑N−1[x(n)+k=1∑papkx(n−k)]x(n−l)+n=0∑N−1−p[x(n)+k=1∑papkx(n+k)]x(n+l)}=0其中, l = 1 , 2 , . . . , p l=1,2,...,p l=1,2,...,p。经过简化后,有: ∑ k = 1 p a p k [ ∑ n = p N − 1 x ( n − k ) x ( n − l ) + ∑ n = 0 N − 1 − p x ( n + k ) x ( n + l ) ] = − [ ∑ n = p N − 1 x ( n ) x ( n − l ) + ∑ n = 0 N − 1 − p x ( n ) x ( n + l ) ] \sum^p_{k=1}a_{pk}[\sum^{N-1}_{n=p}x(n-k)x(n-l)+\sum^{N-1-p}_{n=0}x(n+k)x(n+l)]=-[\sum^{N-1}_{n=p}x(n)x(n-l)+\sum^{N-1-p}_{n=0}x(n)x(n+l)] k=1∑papk[n=p∑N−1x(n−k)x(n−l)+n=0∑N−1−px(n+k)x(n+l)]=−[n=p∑N−1x(n)x(n−l)+n=0∑N−1−px(n)x(n+l)]则上式可以表示为: ∑ k = 1 p a p k c ^ x x ( l , k ) = − c ^ x x ( l , 0 ) \sum^p_{k=1}a_{pk}\hat{c}_{xx}(l,k)=-\hat{c}_{xx}(l,0) k=1∑papkc^xx(l,k)=−c^xx(l,0)其中: c ^ x x ( l , k ) = { 1 2 ( N − p ) ∑ n = p N − 1 x ( n − k ) x ( n − l ) + ∑ n = 0 N − 1 − p x ( n + k ) x ( n + l ) c ^ x x ( k , l ) \hat{c}_{xx}(l,k)=\begin{cases}\displaystyle\frac{1}{2(N-p)}\sum^{N-1}_{n=p}x(n-k)x(n-l)+\sum^{N-1-p}_{n=0}x(n+k)x(n+l)\\\hat{c}_{xx}(k,l)\end{cases} c^xx(l,k)=⎩⎪⎪⎨⎪⎪⎧2(N−p)1n=p∑N−1x(n−k)x(n−l)+n=0∑N−1−px(n+k)x(n+l)c^xx(k,l)写成矩阵形式: [ c ^ x x ( 1 , 1 ) c ^ x x ( 1 , 2 ) ⋯ c ^ x x ( 1 , p ) c ^ x x ( 2 , 1 ) c ^ x x ( 2 , 2 ) ⋯ c ^ x x ( 2 , p ) ⋮ ⋮ ⋱ ⋮ c ^ x x ( p , 1 ) c ^ x x ( p , 2 ) ⋯ c ^ x x ( p , p ) ] [ a p 1 a p 2 ⋮ a p p ] = − [ c ^ x x ( 1 , 0 ) c ^ x x ( 2 , 0 ) ⋮ c ^ x x ( p , 0 ) ] \begin{bmatrix} \hat{c}_{xx}(1,1)&\hat{c}_{xx}(1,2)&\cdots&\hat{c}_{xx}(1,p)\\ \hat{c}_{xx}(2,1)&\hat{c}_{xx}(2,2)&\cdots&\hat{c}_{xx}(2,p)\\ \vdots&\vdots&\ddots&\vdots\\ \hat{c}_{xx}(p,1)&\hat{c}_{xx}(p,2)&\cdots&\hat{c}_{xx}(p,p)\\ \end{bmatrix} \begin{bmatrix} a_{p1}\\ a_{p2}\\ \vdots\\ a_{pp}\\ \end{bmatrix}=- \begin{bmatrix} \hat{c}_{xx}(1,0)\\ \hat{c}_{xx}(2,0)\\ \vdots\\ \hat{c}_{xx}(p,0)\\ \end{bmatrix} ⎣⎢⎢⎢⎡c^xx(1,1)c^xx(2,1)⋮c^xx(p,1)c^xx(1,2)c^xx(2,2)⋮c^xx(p,2)⋯⋯⋱⋯c^xx(1,p)c^xx(2,p)⋮c^xx(p,p)⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡ap1ap2⋮app⎦⎥⎥⎥⎤=−⎣⎢⎢⎢⎡c^xx(1,0)c^xx(2,0)⋮c^xx(p,0)⎦⎥⎥⎥⎤则模型的参数 a p k a_{pk} apk 估计为: [ a p 1 a p 2 ⋮ a p p ] = [ c ^ x x ( 1 , 1 ) c ^ x x ( 1 , 2 ) ⋯ c ^ x x ( 1 , p ) c ^ x x ( 2 , 1 ) c ^ x x ( 2 , 2 ) ⋯ c ^ x x ( 2 , p ) ⋮ ⋮ ⋱ ⋮ c ^ x x ( p , 1 ) c ^ x x ( p , 2 ) ⋯ c ^ x x ( p , p ) ] − 1 [ − c ^ x x ( 1 , 0 ) − c ^ x x ( 2 , 0 ) ⋮ − c ^ x x ( p , 0 ) ] \begin{bmatrix} a_{p1}\\ a_{p2}\\ \vdots\\ a_{pp}\\ \end{bmatrix}=\begin{bmatrix} \hat{c}_{xx}(1,1)&\hat{c}_{xx}(1,2)&\cdots&\hat{c}_{xx}(1,p)\\ \hat{c}_{xx}(2,1)&\hat{c}_{xx}(2,2)&\cdots&\hat{c}_{xx}(2,p)\\ \vdots&\vdots&\ddots&\vdots\\ \hat{c}_{xx}(p,1)&\hat{c}_{xx}(p,2)&\cdots&\hat{c}_{xx}(p,p)\\ \end{bmatrix}^{-1} \begin{bmatrix} -\hat{c}_{xx}(1,0)\\ -\hat{c}_{xx}(2,0)\\ \vdots\\ -\hat{c}_{xx}(p,0)\\ \end{bmatrix} ⎣⎢⎢⎢⎡ap1ap2⋮app⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡c^xx(1,1)c^xx(2,1)⋮c^xx(p,1)c^xx(1,2)c^xx(2,2)⋮c^xx(p,2)⋯⋯⋱⋯c^xx(1,p)c^xx(2,p)⋮c^xx(p,p)⎦⎥⎥⎥⎤−1⎣⎢⎢⎢⎡−c^xx(1,0)−c^xx(2,0)⋮−c^xx(p,0)⎦⎥⎥⎥⎤白噪声的方差 σ p 2 \sigma^2_p σp2 估计为: σ p 2 = ρ m i n = 1 2 ( N − p ) { ∑ n = p N − 1 [ x ( n ) + ∑ k = 1 p a p k x ( n − k ) ] [ x ( n ) + ∑ l = 1 p a p k x ( n − l ) ] + ∑ n = 0 N − 1 − p [ x ( n ) + ∑ k = 1 p a p k x ( n + k ) ] [ x ( n ) + ∑ l = 1 p a p k x ( n + l ) ] } = 1 2 ( N − p ) { ∑ n = p N − 1 [ x ( n ) + ∑ k = 1 p a p k x ( n − k ) ] x ( n ) + ∑ n = 0 N − 1 − p [ x ( n ) + ∑ k = 1 p a p k x ( n + k ) ] x ( n ) } = 1 2 ( N − p ) [ ∑ n = p N − 1 x 2 ( n ) + ∑ n = 0 N − 1 − p x 2 ( n ) ] + ∑ k = 1 p a p k { 1 2 ( N − p ) [ ∑ n = p N − 1 x ( n ) x ( n − k ) + ∑ n = 0 N − 1 − p x ( n ) x ( n + k ) ] } = c ^ x x ( 0 , 0 ) + ∑ k = 1 p a p k c ^ x x ( 0 , k ) \begin{aligned}\sigma^2_p&=\rho_{min}\\&=\frac{1}{2(N-p)}\{\sum^{N-1}_{n=p}[x(n)+\sum^p_{k=1}a_{pk}x(n-k)][x(n)+\sum^p_{l=1}a_{pk}x(n-l)]+\sum^{N-1-p}_{n=0}[x(n)+\sum^p_{k=1}a_{pk}x(n+k)][x(n)+\sum^p_{l=1}a_{pk}x(n+l)]\}\\&=\frac{1}{2(N-p)}\{\sum^{N-1}_{n=p}[x(n)+\sum^p_{k=1}a_{pk}x(n-k)]x(n)+\sum^{N-1-p}_{n=0}[x(n)+\sum^p_{k=1}a_{pk}x(n+k)]x(n)\}\\&=\frac{1}{2(N-p)}[\sum^{N-1}_{n=p}x^2(n)+\sum^{N-1-p}_{n=0}x^2(n)]+\sum^p_{k=1}a_{pk}\{\frac{1}{2(N-p)}[\sum^{N-1}_{n=p}x(n)x(n-k)+\sum^{N-1-p}_{n=0}x(n)x(n+k)]\}\\&=\hat{c}_{xx}(0,0)+\sum^p_{k=1}a_{pk}\hat{c}_{xx}(0,k)\end{aligned} σp2=ρmin=2(N−p)1{n=p∑N−1[x(n)+k=1∑papkx(n−k)][x(n)+l=1∑papkx(n−l)]+n=0∑N−1−p[x(n)+k=1∑papkx(n+k)][x(n)+l=1∑papkx(n+l)]}=2(N−p)1{n=p∑N−1[x(n)+k=1∑papkx(n−k)]x(n)+n=0∑N−1−p[x(n)+