YoloV3训练自己数据集精简流程,FLIR红外数据集(thermal dataset)训练
本文主要是简述如何训练自己的数据集,这里以FLIR的红外数据集为例,配置运行以及原理不再叙述
1.修改Makefile
这步一般已经在配置运行的时候已经做过了,没什么大问题
2.将自己的数据集处理成yolo训练所需的数据集格式
FLIR官方开源的数据集结构如下:
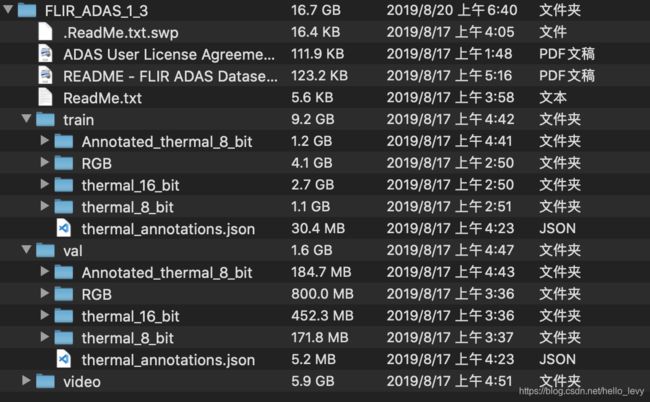
这里的标签文件是一个json文件,而yolo需要的标签文件是txt文件,处理代码链接:https://blog.csdn.net/hello_levy/article/details/105212876
处理后的标签如下,第一个整数代表的是类别,我这里2代表的是car,后面是目标框的中心点和长宽归一化后得到的坐标

每张图片对应一个txt文件:
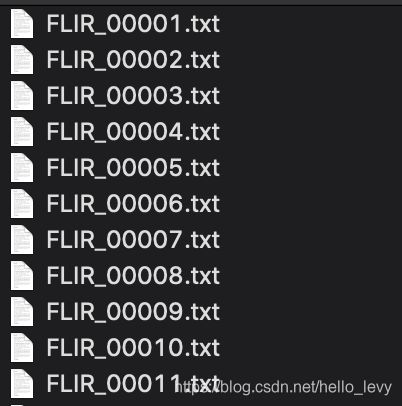
所以我们自己的数据集要做的处理就是:
a.每张图片需要对应一个txt文件的标签文件
b.标签格式为
至此,数据集格式处理完成
3.生成train.txt val.txt
这一步是生成训练集和验证集图片的路径list,代码如下:
import glob
import os
os.chdir("/训练集图片所在路径/")
for file in glob.glob("*.jpeg"):
label = "/训练集在被训练时所想要放的路径/" + file + '\n'
print(label)
print(file)
file = open('../' + 'train.txt的名称' + '.txt', 'a')
file.write(label)
file.close()
可以得到以下内容(所有训练集图片的路径含文件名都在这个txt文件中):
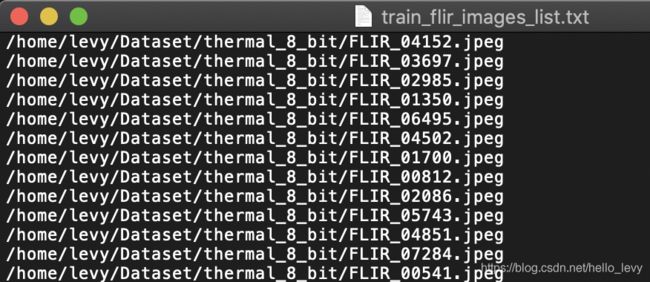
4. 修改cfg文件
这里以yolov3-spp.cfg为例,其他原理一致一共四个地方需要修改
首选,batch和subdivisions的设置,根据自己情况可以稍作修改,
batch:每batch个样本更新一次参数;
subdivisions=16:如果内存不够大,将batch分割为subdivisions个子batch,每个子batch的大小为batch/subdivisions

其次要修改的地方是三个相同的地方,都需要修改,例举一个
每个yolo层以及yolo层前一个convolution层需要修改
filters :3x(classes数目+5),和聚类数目分布有关,详情见论文
classes:类别数
其他暂时不用修改,想修改可以参考:https://github.com/AlexeyAB/darknet

至此,需要训练的cfg文件修改完成
5.修改.names和.data文件
文件所在路径:
data/voc.names 自己有什么类别就填什么,需要注意顺序!,第一个代表的是你标签类别中0代表的类
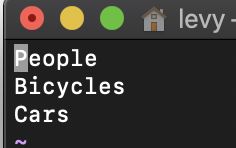
cfg/voc.data
classes= 3 #类别数
train = /home/levy/Dataset/train_flir_images_list.txt #步骤3中train.txt所在路径
valid = /home/levy/Dataset/val_flir_images_list.txt #步骤3中val.txt所在路径
names = data/voc.names
backup = /home/levy/thermal_detection/yolo_model/model_v1 #训练保存模型的路径
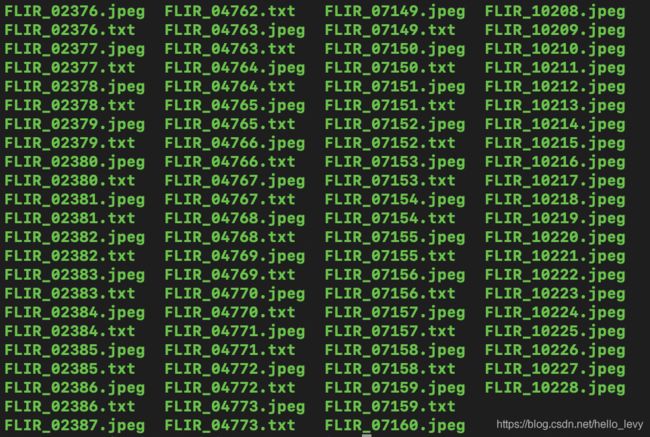
6.关联标签与图片
这里因为我的各文件路径都是随心所欲,所以我直接将标签(一系列.txt文件)放到了训练集图片所在的文件夹,有更好的办法请大佬指点,如图:
7.训练
至此前期准备都完成了,可以直接训练,如果修改了Makefile文件,则需要make clean之后 再进行make
训练命令
./darknet detector train <.data文件路径> <.cfg文件路径> <预训练权重路径(非必须)> <如果有多块gpu,指定gpu:-gpus 0,2>
预训练权重下载:
wget https://pjreddie.com/media/files/darknet53.conv.74