【深度学习】语义分割-数据集调研-处理方法
目录
- 参考笔记
- 数据集类别作用
-
- 为什么要测试集
- 简述
- 数据集
-
- ADE20K
-
- 数据集组成
- 结构
- 图片和注释
- 场景
- 数据集
- COCO Stuff Segmentation
- Pascal VOC2012
-
- 类别
- 结构
- 项目结构
- Stanford background
-
- 详情
- Cityscapes
-
- 数据量
参考笔记
超神经-数据集网站
常用数据集网盘下载1
数据集网盘下载2
【语义分割】——语义分割数据集总结 ADE20K/cityScapes/VOC12_AUG
数据集类别作用
很好的说明!!训练集、验证集、测试集以及交验验证的理解
训练集-----------学生的课本;学生 根据课本里的内容来掌握知识。
验证集------------作业,通过作业可以知道 不同学生学习情况、进步的速度快慢。
测试集-----------考试,考的题是平常都没有见过,考察学生举一反三的能力。
数据集划分比例:
传统机器学习中(小规模数据):数据集分为训练集+测试集,一般比例为7:3;如果分为三类,训练、测试、验证,比例一般为6:2:2。

为什么要测试集
a)训练集直接参与了模型调参的过程,显然不能用来反映模型真实的能力
(防止课本死记硬背的学生拥有最好的成绩,即防止过拟合)。
b)验证集参与了人工调参(超参数)的过程,也不能用来最终评判一个模型
(刷题库的学生不能算是学习好的学生)。
c) 所以要通过最终的考试(测试集)来考察一个学(模)生(型)真正的能力(期末考试)。
但是仅凭一次考试就对模型的好坏进行评判显然是不合理的,所以接下来就要介绍交叉验证法
简述
不同的图像语义分割方法在处理相同类型的图像时的效果参差不齐,而且不同的图像语义分割方法擅长处理的图像类型也各不一样。为了对各种图像语义分割方法的优劣性进行公平的比较,需要一个包含各种图像类型且极具代表性的图像语义分割数据集来测试并得到性能评估指标。
下面将依次介绍图像语义分割领域中常用的数据集,所有常用数据集的数据对比如表1所示
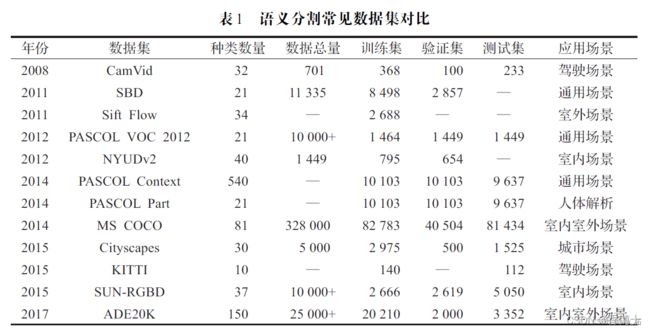
数据集
ADE20K
官网数据集
笔记:
Dataset之ADE20k:ADE20k数据集的简介、安装、使用方法之详细攻略
数据集组成
2016版
该数据集是全尺寸的图像语义分割标注数据集,其中
- 训练图像20210张,
- 验证图像2000张,
- 测试集有3352 张图像。
- 共150个类别(但是语义标注的时候,像素点不能全面覆盖,存在偶尔有点漏掉的现象,于是标注的时候会多一个 “0” 类别,不计入loss的计算,但是网络的输出只有150个类别)
- 语义信息的标注是在一张灰度图像上的,只是各个点的取值范围是(0-150, 0表示背景类,不计入loss计算)
2021版
当前版本的数据集包含:
- 跨越 365 个不同场景的 27,574 张图像(25,574 张用于训练,2,000 张用于测试)。
- 来自 3,688 个类别的 707,868 个唯一对象,以及它们的 WordNet 定义和层次结构。
- 193,238 个带注释的对象零件和零件的零件。
- 具有属性、注释时间、深度排序的多边形注释。

结构
每个图像及其注释都在一个folder_name中,您可以使用index_ade20k.pkl. 进入文件夹名称后,对于给定的图像image_name(例如ADE_train_00016869),您会发现:
1.image_name.jpg:包含原始图像,带有模糊的车牌和面孔(例如ADE_train_00016869.jpg)
2.image_name_seg.png:使用对象和实例的像素级注释(例如ADE_train_00016869_seg.png)。RGB 通道对类和实例信息进行编码。查看 ( utils/utils_ade20k.py)[utils/utils_ade20k.py] 以获取有关如何阅读这些内容的示例。
3.image_name_parts_{i}.png: 带有零件级别的注释i(例如ADE_train_00016869_parts_1.png)。
4.image_name:包含该图像中所有实例的文件夹,存储为 png 编码二进制 amodal 掩码(显示被遮挡的对象)(例如ADE_train_00016869)。
5.image_name.json:一个 json 文件,其中包含有关对象被注释的时间、多边形注释、属性注释等信息(例如ADE_train_00016869.json)。
图片和注释
每个文件夹包含按场景类别(与位置数据库相同的场景类别)分隔的图像。对于每个图像,对象和部分分段存储在两个不同的png文件中。所有对象和部分实例都是稀疏注释的。
场景
室内,室外,自然场景等。单张场景的类别也较多。
包括各种物体(比如人、汽车等)、场景(天空、路面等),150个类别如下:[‘background’ = 0,‘wall=1’, ‘building, edifice=2’, ‘sky=3’, ‘floor, flooring=4’, ‘tree=5’, ‘ceiling=6’, ‘road, route=7’, ‘bed =8’, ‘windowpane, window =9’, ‘grass=10’, ‘cabinet=11’, ‘sidewalk, pavement=12’, ‘person, individual, someone, somebody, mortal, soul=13’, ‘earth, ground=14’, ‘door, double door=15’, ‘table=16’, ‘mountain, mount=17’, ‘plant, flora, plant life=18’, ‘curtain, drape, drapery, mantle, pall=19’, ‘chair=20’, ‘car, auto, automobile, machine, motorcar=21’, 'water=22 ', ‘painting, picture=23’, 'sofa, couch, lounge=24 ', 'shelf=25 ', 'house=26 ', 'sea=27 ', ‘mirror=28’, ‘rug, carpet, carpeting=29’, ‘field=30’, ‘armchair=31’, ‘seat=32’, ‘fence, fencing=33’, ‘desk=34’, ‘rock, stone=35’, ‘wardrobe, closet, press=36’, ‘lamp=37’, ‘bathtub, bathing tub, bath, tub=38’, ‘railing, rail=39’, ‘cushion=40’, ‘base, pedestal, stand=41’, ‘box=42’, ‘column, pillar=43’, ‘signboard, sign=44’, ‘chest of drawers, chest, bureau, dresser=45’, ‘counter=46’, ‘sand=47’, ‘sink=48’, ‘skyscraper=49’, ‘fireplace, hearth, open fireplace=50’, ‘refrigerator, icebox=51’, ‘grandstand, covered stand=52’, ‘path=53’, ‘stairs, steps=54’, ‘runway=55’, ‘case, display case, showcase, vitrine=56’, ‘pool table, billiard table, snooker table=57’, ‘pillow=58’, ‘screen door, screen=59’, ‘stairway, staircase=60’, ‘river=61’, ‘bridge, span=62’, ‘bookcase=63’, ‘blind, screen=64’, ‘coffee table, cocktail table=65’, ‘toilet, can, commode, crapper, pot, potty, stool, throne=66’, ‘flower=67’, ‘book=68’, ‘hill=69’, ‘bench=70’, ‘countertop=71’, ‘stove, kitchen stove, range, kitchen range, cooking stove=72’, ‘palm, palm tree=73’, ‘kitchen island=74’, ‘computer, computing machine, computing device, data processor, electronic computer, information processing system=75’, ‘swivel chair=76’, ‘boat=77’, ‘bar=78’, ‘arcade machine=79’, ‘hovel, hut, hutch, shack, shanty=80’, ‘bus, autobus, coach, charabanc, double-decker, jitney, motorbus, motorcoach, omnibus, passenger vehicle=81’, ‘towel=82’, ‘light, light source=83’, ‘truck, motortruck=84’, ‘tower=85’, ‘chandelier, pendant, pendent=86’, ‘awning, sunshade, sunblind=87’, ‘streetlight, street lamp=88’, ‘booth, cubicle, stall, kiosk=89’, ‘television receiver, television, television set, tv, tv set, idiot box, boob tube, telly, goggle box=90’, ‘airplane, aeroplane, plane=91’, ‘dirt track=92’, ‘apparel, wearing apparel, dress, clothes=93’, ‘pole=94’, ‘land, ground, soil=95’, ‘bannister, banister, balustrade, balusters, handrail=96’, ‘escalator, moving staircase, moving stairway=97’, ‘ottoman, pouf, pouffe, puff, hassock=98’, ‘bottle=99’, ‘buffet, counter, sideboard=100’, ‘poster, posting, placard, notice, bill, card=101’, ‘stage=102’, ‘van=103’, ‘ship=104’, ‘fountain=105’, ‘conveyer belt, conveyor belt, conveyer, conveyor, transporter=106’, ‘canopy=107’, ‘washer, automatic washer, washing machine=108’, ‘plaything, toy=109’, ‘swimming pool, swimming bath, natatorium=110’, ‘stool=111’, ‘barrel, cask=112’, ‘basket, handbasket=113’, ‘waterfall, falls=114’, ‘tent, collapsible shelter=115’, ‘bag=116’, ‘minibike, motorbike=117’, ‘cradle=118’, ‘oven=119’, ‘ball=120’, ‘food, solid food=121’, ‘step, stair=122’, ‘tank, storage tank=123’, ‘trade name, brand name, brand, marque=124’, ‘microwave, microwave oven=125’, ‘pot, flowerpot=126’, ‘animal, animate being, beast, brute, creature, fauna=127’, ‘bicycle, bike, wheel, cycle =128’, ‘lake=129’, ‘dishwasher, dish washer, dishwashing machine=130’, ‘screen, silver screen, projection screen=131’, ‘blanket, cover=132’, ‘sculpture=133’, ‘hood, exhaust hood=134’, ‘sconce=135’, ‘vase=136’, ‘traffic light, traffic signal, stoplight=137’, ‘tray=138’, ‘ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin, dustbin, trash barrel, trash bin=139’, ‘fan=140’, ‘pier, wharf, wharfage, dock=141’, ‘crt screen=142’, ‘plate=143’, ‘monitor, monitoring device=144’, ‘bulletin board, notice board=145’, ‘shower=146’, ‘radiator=147’, ‘glass, drinking glass=148’, ‘clock=149’, ‘flag=150’]。
数据集
格式:
.jpg表示RGB图像
_seg.png表示对象分割mask图像,既包括实例mask也包括类别mask信息,其中通道R与G被编码成对象mask,通道B被编码成实例mask。
*_seg_parts_N.png 表示部分分割mask
*.txt表述每个分割图像的对象与parts的冗余信息文本文件
COCO Stuff Segmentation
官网数据集下载
数据集介绍
COCO Stuff Segmentation Task 旨在推动 Stuff Class 的语义分割技术水平,相较于以解决 Thing Class(人、汽车、大象)为主的目标检测任务,此任务更专注于 Stuff Class(草、墙、天空)。
COCO Stuff 是指具有特定尺寸和形状的物体,其通常由部件组成,Stuff Class 则是由精细尺度属性的均匀或重复模式定义的背景,没有特定或独特的空间范围与形状。其中 Stuff 覆盖了 COCO 中约 66% 的像素,它使得我们能够解释和理解图像的重要方面:场景类型、可能存在的类别及位置、场景的几何属性。
Pascal VOC2012
官网数据集下载链接
在FCN的实际应用
数据集的代码上的展示
类别
VOC2012数据集分为20类,包括背景为21类,分别如下:
人: 人
动物:鸟,猫,牛,狗,马,羊
车辆:飞机,自行车,船,公共汽车,汽车,摩托车,火车
室内:瓶子,椅子,餐桌,盆栽植物,沙发,电视/显示器
结构

其中Annotations其中Annotations文件夹中是图片的XML信息,xml信息包含了该图片的基本信息,xml语言很易读,我们从中可以轻易得出这幅图片的一些基本信息,其中segmented一栏为1,这里的意思是这幅图用于分割(因为VOC2012中一共有10000+图,但并不都用于分割任务,有的用以物体标识或者动作识别等),若这一栏为0说明这幅图不是用于图像分割的。
ImageSets文件夹中有有四个文件夹,其中Segmentation是我们分割所需的文件,其中包含训练,验证检索的.txt文件,
train和val中的图片加一起一共2913张图。
JPEGImages文件中是我们的原始图片,这些图片一共有17125张,我们并不是都使用,我们仅对train.txt和val.txt中列出的图像进行使用,而其他的图像则用于不同的任务中,用于分割的图片在.txt文件中有详细,。
GT图像在SegentationClass文件夹中。
项目结构

Stanford background
下载链接
Stanford Background Dataset介绍和使用
Stanford Background Dataset是一个从各个数据库(LabelMe, MSRC, PASCAL VOC, Geometric Context)中精选出 715 张室外图像分为 sky, tree, road, grass, water, building, mountain, foreground object 共八大类的图像。
详情
images 文件夹包含了 715 张图像;
horizons.txt 图像名称、大小、水平线位置;
labels/*.regions.txt 标识每个像素的语义,0-7 代表八类语义;
labels/*.surfaces.txt 标识每个像素的几何类别(天空,水平,垂直);
labels/*.layers.txt 表示不同图像区域的整数矩阵。
Cityscapes
由奔驰主推,提供无人驾驶环境下的图像分割数据集,用于评估视觉算法在于城市街道场景语义理解方面的性能
数据量
- 5000张像素级标注图片,20000张弱标注图片
- 数据集共有30个类别
- 采集自50个不同的城市
- 不同的月份(春夏秋)
- 白天
- 好、中好天气
- 单张图片中有多个物体,不同的场景布局,不同的背景
Cityscapes数据集共有fine和coarse两套评测标准,前者提供5000张精细标注的图像,后者提供5000张精细标注外加20000张粗糙标注的图像,用PASCAL VOC标准的 intersection-over-union (IoU)得分来对算法性能进行评价。 5000张精细标注的图片分为训练集2975张图片,验证集有500张图片,而测试集有1525张图片,测试集不对外公布,需要将预测结果上传到评估服务器才能计算mIoU值。
Cityscapes包含50个欧洲城市不同场景、不同背景、不同季节的街景的33类标注物体,它包括30个类别的语义和密集像素标注,分为8个类别:平面、人、车辆、建筑、物体、自然、天空和虚空。
包括:{‘unlabeled’=0 , ‘ego vehicle’=1 , ‘rectification border’=2 , ‘out of roi’= 3 , ‘static’=4 , ‘dynamic’=5 , ‘ground’=6 ,‘road’=7 ,‘sidewalk’=8 ,parking’=9 ,‘rail track’=10 ,‘building’=11 ,‘wall’=12 ,‘fence’=13 , ‘guard rail’=14 ,‘bridge’=15 ,‘tunnel’=16 ,‘pole’=17 ,‘polegroup’=18 , ‘traffic light’=19 ,‘traffic sign’=20 , ‘vegetation’=21 , ‘terrain’=22 ,‘sky’=23 , ‘person’=24 , ‘rider’=25 , ‘car’=26 ,‘truck’=27 , ‘bus’=28 ,‘caravan’=29 ,‘trailer’=30 ,‘train’=31 ,‘motorcycle’=32 , ‘bicycle’=33 },但是在这33个类中,评估时只用到了19个类别,因此训练时将33个类映射为19个类,评估时需要将19个类又映射回33个类上传评估服务器。