文本中的对抗学习 + pytorch实现
最近,微软的FreeLB-Roberta [1] 靠着对抗训练 (Adversarial Training) 在GLUE榜上超越了Facebook原生的Roberta,追一科技也用到了这个方法仅凭单模型 [2] 就在CoQA榜单中超过了人类,似乎“对抗训练”一下子变成了NLP任务的一把利器。最近博主正好在参加了基于Adversarial Attack的问题等价性判别比赛,所以记录一下在NLP中的对抗训练领域中学习到的知识。
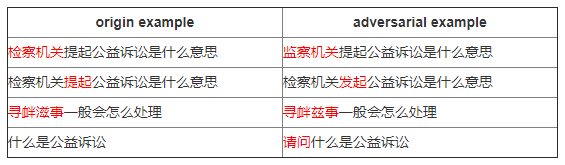 原始文本与对抗样本
原始文本与对抗样本
本文专注于NLP对抗训练的介绍,对对抗攻击基础感兴趣的读者,可以看这几篇博客及论文 [3] [4] [5],这里就不赘述了。
对抗样本
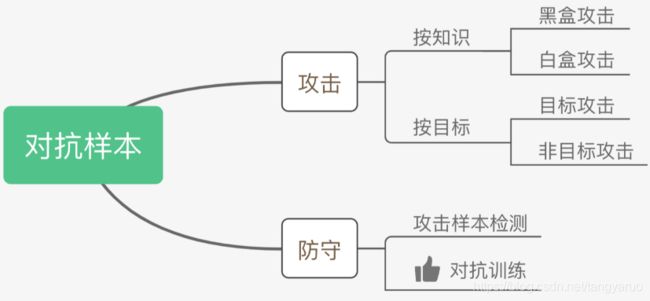
Szegedy在14年的ICLR中 [6] 提出了对抗样本这个概念。如上图,对抗样本可以用来攻击和防御,而对抗训练其实是“对抗”家族中防御的一种方式,其基本的原理就是通过添加扰动构造一些对抗样本,放给模型去训练,以攻为守,提高模型在遇到对抗样本时的鲁棒性,同时一定程度也能提高模型的表现和泛化能力。
那么,什么样的样本才是好的对抗样本呢?对抗样本一般需要具有两个特点:
-
相对于原始输入,所添加的扰动是微小的;
-
能使模型犯错。
下面是一个对抗样本的例子,给大熊猫加了微弱的像素扰动后,被模型识别为长臂猿。

对抗训练的基本概念
GAN之父Ian Goodfellow在15年的ICLR中 [7] 第一次提出了对抗训练这个概念,简而言之,就是在原始输入样本  上加一个扰动
上加一个扰动![]() 得到对抗样本后,用其进行训练。也就是说,问题可以被抽象成这么一个模型:
得到对抗样本后,用其进行训练。也就是说,问题可以被抽象成这么一个模型:
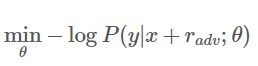
其中, 为gold label,
为gold label, 为模型参数。那扰动要如何计算呢?Goodfellow认为,神经网络由于其线性的特点,很容易受到线性扰动的攻击。于是,他提出了 Fast Gradient Sign Method (FGSM) ,来计算输入样本的扰动。扰动可以被定义为:
为模型参数。那扰动要如何计算呢?Goodfellow认为,神经网络由于其线性的特点,很容易受到线性扰动的攻击。于是,他提出了 Fast Gradient Sign Method (FGSM) ,来计算输入样本的扰动。扰动可以被定义为:
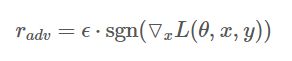
其中,![]() 为符号函数,
为符号函数, 为损失函数。Goodfellow发现,令
为损失函数。Goodfellow发现,令![]() ,用这个扰动能给一个单层分类器造成99.9%的错误率。看似这个扰动的发现有点拍脑门,但是仔细想想,其实这个扰动计算的思想可以理解为:将输入样本向着损失上升的方向再进一步,得到的对抗样本就能造成更大的损失,提高模型的错误率。回想我们上一节提到的对抗样本的两个要求,FGSM刚好可以完美地解决。Goodfellow还总结了对抗训练的两个作用:
,用这个扰动能给一个单层分类器造成99.9%的错误率。看似这个扰动的发现有点拍脑门,但是仔细想想,其实这个扰动计算的思想可以理解为:将输入样本向着损失上升的方向再进一步,得到的对抗样本就能造成更大的损失,提高模型的错误率。回想我们上一节提到的对抗样本的两个要求,FGSM刚好可以完美地解决。Goodfellow还总结了对抗训练的两个作用:
- 提高模型应对恶意对抗样本时的鲁棒性;
- 作为一种regularization,减少overfitting,提高泛化能力。
Min-Max 公式
对抗训练的理论部分被阐述得还是比较intuitive,Madry在2018年的ICLR中 [8]总结了之前的工作,并从优化的视角,将问题重新定义成了一个找鞍点的问题,也就是大名鼎鼎的Min-Max公式:
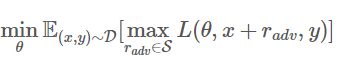
该公式分为两个部分,一个是内部损失函数的最大化,一个是外部经验风险的最小化。
-
内部max是为了找到worst-case的扰动,也就是攻击,其中,
为损失函数, 为扰动的范围空间;
为扰动的范围空间; -
外部min是为了基于该攻击方式,找到最鲁棒的模型参数,也就是防御,其中
 是输入样本的分布。
是输入样本的分布。
Madry认为,这个公式简单清晰地定义了对抗样本攻防“矛与盾”的两个问题:如何构造足够强的对抗样本?以及,如何使模型变得刀枪不入?剩下的,就是如何求解的问题了。
从 CV 到 NLP
以上提到的一些工作都还是停留在CV领域的,那么问题来了,可否将对抗训练迁移到NLP上呢?答案是肯定的,但是,我们得考虑这么几个问题:
首先,CV任务的输入是连续的RGB的值,而NLP问题中,输入是离散的单词序列,一般以one-hot vector的形式呈现,如果直接在raw text上进行扰动,那么扰动的大小和方向可能都没什么意义。Goodfellow在17年的ICLR中 [9] 提出了可以在连续的embedding上做扰动:
Because the set of high-dimensional one-hot vectors does not admit infinitesimal perturbation, we define the perturbation on continuous word embeddings instead of discrete word inputs.
乍一思考,觉得这个解决方案似乎特别完美。然而,对比图像领域中直接在原始输入加扰动的做法,在embedding上加扰动会带来这么一个问题:这个被构造出来的“对抗样本”并不能map到某个单词,因此,反过来在inference的时候,对手也没有办法通过修改原始输入得到这样的对抗样本。我们在上面提到,对抗训练有两个作用,一是提高模型对恶意攻击的鲁棒性,二是提高模型的泛化能力。在CV任务,根据经验性的结论,对抗训练往往会使得模型在非对抗样本上的表现变差,然而神奇的是,在NLP任务中,模型的泛化能力反而变强了,如[1]中所述:
While adversarial training boosts the robustness, it is widely accepted by computer vision researchers that it is at odds with generalization, with classification accuracy on non-corrupted images dropping as much as 10% on CIFAR-10, and 15% on Imagenet (Madry et al., 2018; Xie et al., 2019). Surprisingly, people observe the opposite result for language models (Miyato et al., 2017; Cheng et al., 2019), showing that adversarial training can improve both generalization and robustness.
因此,在NLP任务中,对抗训练的角色不再是为了防御基于梯度的恶意攻击,反而更多的是作为一种regularization,提高模型的泛化能力。
NLP中的两种对抗训练 + PyTorch实现
1)Fast Gradient Method(FGM)
上面我们提到,Goodfellow在15年的ICLR [7] 中提出了Fast Gradient Sign Method(FGSM),随后,在17年的ICLR [9]中,Goodfellow对FGSM中计算扰动的部分做了一点简单的修改。假设输入的文本序列的embedding vectors![]() 为,embedding的扰动:
为,embedding的扰动:

实际上就是取消了符号函数,用二范式做了一个scale,需要注意的是:这里的norm计算的是每个样本的输入序列中出现过的词组成的矩阵的梯度norm。原作者提供了一个TensorFlow的实现 [10],在他的实现中,公式里的是embedding后的中间结果(batch_size, timesteps, hidden_dim),对其梯度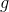 的后面两维计算norm,得到的是一个(batch_size, 1, 1)的向量
的后面两维计算norm,得到的是一个(batch_size, 1, 1)的向量![]() 。为了实现插件式的调用,笔者将一个batch抽象成一个样本,一个batch统一用一个norm,由于本来norm也只是一个scale的作用,影响不大。笔者的实现如下:
。为了实现插件式的调用,笔者将一个batch抽象成一个样本,一个batch统一用一个norm,由于本来norm也只是一个scale的作用,影响不大。笔者的实现如下:
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0:
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}需要使用对抗训练的时候,只需要添加五行代码:
# 初始化
fgm = FGM(model)
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
fgm.attack() # 在embedding上添加对抗扰动
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()PyTorch为了节约内存,在backward的时候并不保存中间变量的梯度。因此,如果需要完全照搬原作的实现,需要用register_hook接口[11]将embedding后的中间变量的梯度保存成全局变量,norm后面两维,计算出扰动后,在对抗训练forward时传入扰动,累加到embedding后的中间变量上,得到新的loss,再进行梯度下降。不过这样实现就与我们追求插件式简单好用的初衷相悖,这里就不赘述了,感兴趣的读者可以自行实现。
2)Projected Gradient Descent(PGD)
内部max的过程,本质上是一个非凹的约束优化问题,FGM解决的思路其实就是梯度上升,那么FGM简单粗暴的“一步到位”,是不是有可能并不能走到约束内的最优点呢?当然是有可能的。于是,一个很intuitive的改进诞生了:Madry在18年的ICLR中[8],提出了用Projected Gradient Descent(PGD)的方法,简单的说,就是“小步走,多走几步”,如果走出了扰动半径为 的空间,就映射回“球面”上,以保证扰动不要过大:
的空间,就映射回“球面”上,以保证扰动不要过大:
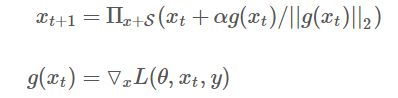
其中![]() 为扰动的约束空间,
为扰动的约束空间, 为小步的步长。
为小步的步长。
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0:
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]使用的时候,要麻烦一点:
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 对抗训练
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()Reference
[1]:FreeLB: Enhanced Adversarial Training for Language Understanding. https://arxiv.org/abs/1909.11764
[2]:Technical report on Conversational Question Answering. https://arxiv.org/abs/1909.10772
[3]:EYD与机器学习:对抗攻击基础知识(一). https://zhuanlan.zhihu.com/p/37260275
[4]:Towards a Robust Deep Neural Network in Text Domain A Survey. https://arxiv.org/abs/1902.07285
[5]:Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey. https://arxiv.org/abs/1901.06796
[6]:Intriguing properties of neural networks. https://arxiv.org/abs/1312.6199
[7]:Explaining and Harnessing Adversarial Examples. https://arxiv.org/abs/1412.6572
[8]:Towards Deep Learning Models Resistant to Adversarial Attacks. https://arxiv.org/abs/1706.06083
[9]:Adversarial Training Methods for Semi-Supervised Text Classification. https://arxiv.org/abs/1605.07725
[10]:Adversarial Text Classification原作实现. https://github.com/tensorflow/models/blob/e97e22dfcde0805379ffa25526a53835f887a860/research/adversarial_text/adversarial_losses.py
[11]:register_hook api. https://www.cnblogs.com/SivilTaram/p/pytorch_intermediate_variable_gradient.html
[12]:huggingface的transformers. https://github.com/huggingface/transformers/tree/master/examples
[13]:Distributional Smoothing with Virtual Adversarial Training. https://arxiv.org/abs/1507.00677
最后,感谢大佬的精彩博文
参考博文:瓦特兰迪斯