NLP对抗训练:PyTorch、Tensorflow
一、定义
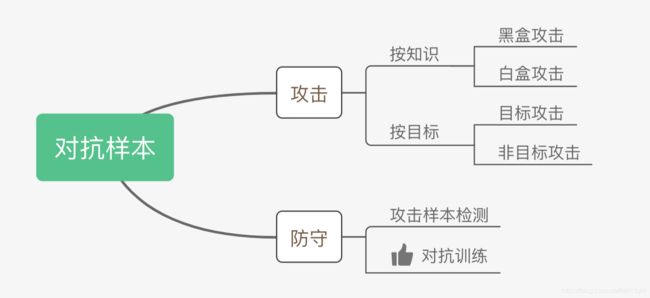
对抗样本:对输入增加微小扰动得到的样本。旨在增加模型损失。
对抗训练:训练模型去区分样例是真实样例还是对抗样本的过程。对抗训练不仅可以提升模型对对抗样本的防御能力,还能提升对原始样本的泛化能力。
二、PyTorch版的NLP对抗训练
三、Tensorflow版的NLP对抗训练
#! -*- coding: utf-8 -*-
import keras
import keras.backend as K
def search_layer(inputs, name, exclude=None):
"""根据inputs和name来搜索层
说明:inputs为某个层或某个层的输出;name为目标层的名字。
实现:根据inputs一直往上递归搜索,直到发现名字为name的层为止;
如果找不到,那就返回None。
"""
if exclude is None:
exclude = set()
if isinstance(inputs, keras.layers.Layer):
layer = inputs
else:
layer = inputs._keras_history[0]
if layer.name == name:
return layer
elif layer in exclude:
return None
else:
exclude.add(layer)
inbound_layers = layer._inbound_nodes[0].inbound_layers
if not isinstance(inbound_layers, list):
inbound_layers = [inbound_layers]
if len(inbound_layers) > 0:
for layer in inbound_layers:
layer = search_layer(layer, name, exclude)
if layer is not None:
return layer
def adversarial_training(model, embedding_name, epsilon=1):
"""给模型添加对抗训练
其中model是需要添加对抗训练的keras模型,embedding_name
则是model里边Embedding层的名字。要在模型compile之后使用。
"""
if model.train_function is None: # 如果还没有训练函数
model._make_train_function() # 手动make
old_train_function = model.train_function # 备份旧的训练函数
# 查找Embedding层
for output in model.outputs:
embedding_layer = search_layer(output, embedding_name)
if embedding_layer is not None:
break
if embedding_layer is None:
raise Exception('Embedding layer not found')
# 求Embedding梯度
embeddings = embedding_layer.embeddings # Embedding矩阵
gradients = K.gradients(model.total_loss, [embeddings]) # Embedding梯度
gradients = K.zeros_like(embeddings) + gradients[0] # 转为dense tensor
# 封装为函数
inputs = (model._feed_inputs +
model._feed_targets +
model._feed_sample_weights) # 所有输入层
embedding_gradients = K.function(
inputs=inputs,
outputs=[gradients],
name='embedding_gradients',
) # 封装为函数
def train_function(inputs): # 重新定义训练函数
grads = embedding_gradients(inputs)[0] # Embedding梯度
delta = epsilon * grads / (np.sqrt((grads**2).sum()) + 1e-8) # 计算扰动
K.set_value(embeddings, K.eval(embeddings) + delta) # 注入扰动
outputs = old_train_function(inputs) # 梯度下降
K.set_value(embeddings, K.eval(embeddings) - delta) # 删除扰动
return outputs
model.train_function = train_function # 覆盖原训练函数案例:
https://github.com/bojone/bert4keras/blob/master/examples/task_iflytek_adversarial_training.py
#! -*- coding:utf-8 -*-
# 通过对抗训练增强模型的泛化性能
# 比CLUE榜单公开的同数据集上的BERT base的成绩高2%
# 数据集:IFLYTEK' 长文本分类 (https://github.com/CLUEbenchmark/CLUE)
# 博客:https://kexue.fm/archives/7234
# 适用于Keras 2.3.1
import json
import numpy as np
from bert4keras.backend import keras, search_layer, K
from bert4keras.tokenizers import Tokenizer
from bert4keras.models import build_transformer_model
from bert4keras.optimizers import Adam
from bert4keras.snippets import sequence_padding, DataGenerator
from keras.layers import Lambda, Dense
from tqdm import tqdm
num_classes = 119
maxlen = 128
batch_size = 32
# BERT base
config_path = '/root/kg/bert/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '/root/kg/bert/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '/root/kg/bert/chinese_L-12_H-768_A-12/vocab.txt'
def load_data(filename):
"""加载数据
单条格式:(文本, 标签id)
"""
D = []
with open(filename) as f:
for i, l in enumerate(f):
l = json.loads(l)
text, label = l['sentence'], l['label']
D.append((text, int(label)))
return D
# 加载数据集
train_data = load_data(
'/root/CLUE-master/baselines/CLUEdataset/iflytek/train.json'
)
valid_data = load_data(
'/root/CLUE-master/baselines/CLUEdataset/iflytek/dev.json'
)
# 建立分词器
tokenizer = Tokenizer(dict_path, do_lower_case=True)
class data_generator(DataGenerator):
"""数据生成器
"""
def __iter__(self, random=False):
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
for is_end, (text, label) in self.sample(random):
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
batch_token_ids.append(token_ids)
batch_segment_ids.append(segment_ids)
batch_labels.append([label])
if len(batch_token_ids) == self.batch_size or is_end:
batch_token_ids = sequence_padding(batch_token_ids)
batch_segment_ids = sequence_padding(batch_segment_ids)
batch_labels = sequence_padding(batch_labels)
yield [batch_token_ids, batch_segment_ids], batch_labels
batch_token_ids, batch_segment_ids, batch_labels = [], [], []
# 转换数据集
train_generator = data_generator(train_data, batch_size)
valid_generator = data_generator(valid_data, batch_size)
# 加载预训练模型
bert = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
return_keras_model=False,
)
output = Lambda(lambda x: x[:, 0])(bert.model.output)
output = Dense(
units=num_classes,
activation='softmax',
kernel_initializer=bert.initializer
)(output)
model = keras.models.Model(bert.model.input, output)
model.summary()
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=Adam(2e-5),
metrics=['sparse_categorical_accuracy'],
)
def adversarial_training(model, embedding_name, epsilon=1):
"""给模型添加对抗训练
其中model是需要添加对抗训练的keras模型,embedding_name
则是model里边Embedding层的名字。要在模型compile之后使用。
"""
if model.train_function is None: # 如果还没有训练函数
model._make_train_function() # 手动make
old_train_function = model.train_function # 备份旧的训练函数
# 查找Embedding层
for output in model.outputs:
embedding_layer = search_layer(output, embedding_name)
if embedding_layer is not None:
break
if embedding_layer is None:
raise Exception('Embedding layer not found')
# 求Embedding梯度
embeddings = embedding_layer.embeddings # Embedding矩阵
gradients = K.gradients(model.total_loss, [embeddings]) # Embedding梯度
gradients = K.zeros_like(embeddings) + gradients[0] # 转为dense tensor
# 封装为函数
inputs = (
model._feed_inputs + model._feed_targets + model._feed_sample_weights
) # 所有输入层
embedding_gradients = K.function(
inputs=inputs,
outputs=[gradients],
name='embedding_gradients',
) # 封装为函数
def train_function(inputs): # 重新定义训练函数
grads = embedding_gradients(inputs)[0] # Embedding梯度
delta = epsilon * grads / (np.sqrt((grads**2).sum()) + 1e-8) # 计算扰动
K.set_value(embeddings, K.eval(embeddings) + delta) # 注入扰动
outputs = old_train_function(inputs) # 梯度下降
K.set_value(embeddings, K.eval(embeddings) - delta) # 删除扰动
return outputs
model.train_function = train_function # 覆盖原训练函数
# 写好函数后,启用对抗训练只需要一行代码
adversarial_training(model, 'Embedding-Token', 0.5)
def evaluate(data):
total, right = 0., 0.
for x_true, y_true in data:
y_pred = model.predict(x_true).argmax(axis=1)
y_true = y_true[:, 0]
total += len(y_true)
right += (y_true == y_pred).sum()
return right / total
class Evaluator(keras.callbacks.Callback):
"""评估与保存
"""
def __init__(self):
self.best_val_acc = 0.
def on_epoch_end(self, epoch, logs=None):
val_acc = evaluate(valid_generator)
if val_acc > self.best_val_acc:
self.best_val_acc = val_acc
model.save_weights('best_model.weights')
print(
u'val_acc: %.5f, best_val_acc: %.5f\n' %
(val_acc, self.best_val_acc)
)
def predict_to_file(in_file, out_file):
"""输出预测结果到文件
结果文件可以提交到 https://www.cluebenchmarks.com 评测。
"""
fw = open(out_file, 'w')
with open(in_file) as fr:
for l in tqdm(fr):
l = json.loads(l)
text = l['sentence']
token_ids, segment_ids = tokenizer.encode(text, maxlen=maxlen)
label = model.predict([[token_ids], [segment_ids]])[0].argmax()
l = json.dumps({'id': str(l['id']), 'label': str(label)})
fw.write(l + '\n')
fw.close()
if __name__ == '__main__':
evaluator = Evaluator()
model.fit(
train_generator.forfit(),
steps_per_epoch=len(train_generator),
epochs=50,
callbacks=[evaluator]
)
else:
model.load_weights('best_model.weights')
# predict_to_file('/root/CLUE-master/baselines/CLUEdataset/iflytek/test.json', 'iflytek_predict.json')
GitHub - bojone/keras_adversarial_training: Adversarial Training for NLP in Keras
训练技巧 | 功守道:NLP中的对抗训练 + PyTorch实现 - 灰信网(软件开发博客聚合)
【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现 - 知乎
GitHub - bojone/bert4keras: keras implement of transformers for humans
对抗训练_Fang Suk的博客-CSDN博客_对抗训练
对抗训练浅谈:意义、方法和思考(附Keras实现) - 科学空间|Scientific Spaces
bert4keras 文档中心