bert 对抗训练实现代码
目录
前言:
FGSM
PGD
FreeLB
Virtual Adversarial Training
效果
参考资料
前言:
对抗训练是魔改训练方式的一种,凡事对抗一下,说不定可以提高性能,建议都试一试,网上关于对抗训练的代码已经有很多啦,笔者这里简单汇总一些,供快速应用到自己的代码中,看效果,下面的代码包括FGSM,PGD.FreeLB,Virtual Adversarial Training。
说明:
(1)本篇不讲原理,重在实现,想看原理的,可以去找一些论文或博客,也可以参考文末给出的参考资料,下面的代码也基本都是摘录文末的参考资料,前三种对抗训练见参考资料的前3篇,后一种是一种基于对抗学习的半监督方式,见参考资料的后3篇
(2) 其实扰动应该是在整个emb输出的基础上进行,但是鉴于拆分模型比较麻烦,所以都是在emb矩阵上直接扰动,虽然这样扰动缺少多样性(即同一个位置token面临相同扰动),但是易于实现即:
对于CV任务来说,一般输入张量的shape是(b, h, w, c),这时候我们需要固定模型的batch size,即b,然后给原始输入加上一个shape同样为(b, h, w, c)、全零初始化的Variable,比如就叫做ΔxΔxΔx,那么我们可以直接求loss对x的梯度,然后根据梯度给ΔxΔxΔx赋值,来实现对输入的干扰,完成干扰之后再执行常规的梯度下降。
对于nlp任务来说,原则上也要对Embedding层的输出进行同样的操作,Embedding层的输出shape为(b, n, d),所以也要在Embedding层的输出加上一个shape为(b, n, d)的Variable,然后进行上述步骤,但需要拆解重构模型,对使用者不够友好。
退而求其次。Embedding层的输出是直接取自于Embedding参数矩阵的,因此我们可以直接对Embedding参数矩阵进行扰动。这样得到的对抗样本的多样性会少一些(因为不同样本的同一个token共用了相同的扰动)。但仍能起到正则化的作用,实现起来容易得多。
上述话:来源于bert4keras快速使用以及对抗训练 - 灰信网(软件开发博客聚合)
(3)不论哪种对抗基本都要求知道自己模型中的embedding的参数名,现在用的最多的就是bert,笔者这里打印了一下pytorch-transformers的bert-base-chinese模型层名:
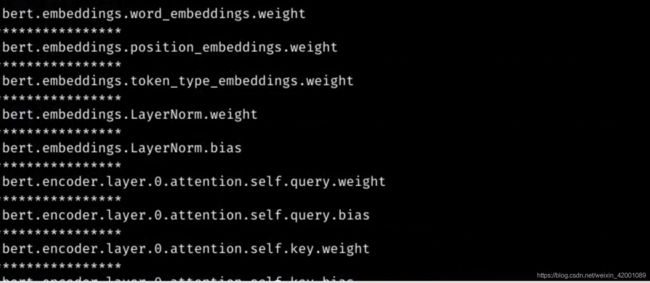
可以看到整个emb应该是word_embeddings+position_embeddings+token_type_embeddings,但是为了便于实现是对word_embeddings矩阵直接扰动的,如果用 bert的话,下面代码中涉及到的"自己模型embedding的参数名"即emb_name可是使用"word_embeddings",注意不要写成embeddings.了,这样的话就是对position_embeddings+token_type_embeddings有影响了,当然可以试一试。
FGSM
这是最开始的对抗思路
class FGM(object):
def __init__(self, model, emb_name, epsilon=1.0):
# emb_name这个参数要换成你模型中embedding的参数名
self.model = model
self.epsilon = epsilon
self.emb_name = emb_name
self.backup = {}
def attack(self):
for name, param in self.model.named_parameters():
if param.requires_grad and self.emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = self.epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self):
for name, param in self.model.named_parameters():
if param.requires_grad and self.emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}训练
fgm = FGM(model,epsilon=1,emb_name='word_embeddings.')
for batch_input, batch_label in processor:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
fgm.attack() # 在embedding上添加对抗扰动
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()PGD
相当于多步FGSM
class PGD(object):
def __init__(self, model, emb_name, epsilon=1., alpha=0.3):
# emb_name这个参数要换成你模型中embedding的参数名
self.model = model
self.emb_name = emb_name
self.epsilon = epsilon
self.alpha = alpha
self.emb_backup = {}
self.grad_backup = {}
def attack(self, is_first_attack=False):
for name, param in self.model.named_parameters():
if param.requires_grad and self.emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0:
r_at = self.alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, self.epsilon)
def restore(self):
for name, param in self.model.named_parameters():
if param.requires_grad and self.emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad and param.grad is not None:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad and param.grad is not None:
param.grad = self.grad_backup[name]训练
pgd = PGD(model,emb_name='word_embeddings.',epsilon=1.0,alpha=0.3)
K = 3
for batch_input, batch_label in processor:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 对抗训练
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.processor
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
FreeLB
class FreeLB(object):
def __init__(self, adv_K, adv_lr, adv_init_mag, adv_max_norm=0., adv_norm_type='l2', base_model='bert'):
self.adv_K = adv_K
self.adv_lr = adv_lr
self.adv_max_norm = adv_max_norm
self.adv_init_mag = adv_init_mag
self.adv_norm_type = adv_norm_type
self.base_model = base_model
def attack(self, model, inputs, gradient_accumulation_steps=1):
input_ids = inputs['input_ids']
if isinstance(model, torch.nn.DataParallel):
embeds_init = getattr(model.module, self.base_model).embeddings.word_embeddings(input_ids)
else:
embeds_init = getattr(model, self.base_model).embeddings.word_embeddings(input_ids)
if self.adv_init_mag > 0:
input_mask = inputs['attention_mask'].to(embeds_init)
input_lengths = torch.sum(input_mask, 1)
if self.adv_norm_type == "l2":
delta = torch.zeros_like(embeds_init).uniform_(-1, 1) * input_mask.unsqueeze(2)
dims = input_lengths * embeds_init.size(-1)
mag = self.adv_init_mag / torch.sqrt(dims)
delta = (delta * mag.view(-1, 1, 1)).detach()
elif self.adv_norm_type == "linf":
delta = torch.zeros_like(embeds_init).uniform_(-self.adv_init_mag, self.adv_init_mag)
delta = delta * input_mask.unsqueeze(2)
else:
delta = torch.zeros_like(embeds_init)
for astep in range(self.adv_K):
delta.requires_grad_()
inputs['inputs_embeds'] = delta + embeds_init
inputs['input_ids'] = None
outputs = model(**inputs)
loss, logits = outputs[:2] # model outputs are always tuple in transformers (see doc)
loss = loss.mean() # mean() to average on multi-gpu parallel training
loss = loss / gradient_accumulation_steps
loss.backward()
delta_grad = delta.grad.clone().detach()
if self.adv_norm_type == "l2":
denorm = torch.norm(delta_grad.view(delta_grad.size(0), -1), dim=1).view(-1, 1, 1)
denorm = torch.clamp(denorm, min=1e-8)
delta = (delta + self.adv_lr * delta_grad / denorm).detach()
if self.adv_max_norm > 0:
delta_norm = torch.norm(delta.view(delta.size(0), -1).float(), p=2, dim=1).detach()
exceed_mask = (delta_norm > self.adv_max_norm).to(embeds_init)
reweights = (self.adv_max_norm / delta_norm * exceed_mask + (1 - exceed_mask)).view(-1, 1, 1)
delta = (delta * reweights).detach()
elif self.adv_norm_type == "linf":
denorm = torch.norm(delta_grad.view(delta_grad.size(0), -1), dim=1, p=float("inf")).view(-1, 1, 1)
denorm = torch.clamp(denorm, min=1e-8)
delta = (delta + self.adv_lr * delta_grad / denorm).detach()
if self.adv_max_norm > 0:
delta = torch.clamp(delta, -self.adv_max_norm, self.adv_max_norm).detach()
else:
raise ValueError("Norm type {} not specified.".format(self.adv_norm_type))
if isinstance(model, torch.nn.DataParallel):
embeds_init = getattr(model.module, self.base_model).embeddings.word_embeddings(input_ids)
else:
embeds_init = getattr(model, self.base_model).embeddings.word_embeddings(input_ids)
return loss
训练
freelb = FreeLB()
K = 3
for batch_input, batch_label in processor:
loss = freelb.attack(model,inputs,.....)
说明
(1)关于这里的训练可能看着有点疑惑,还是不知道具体怎么写,可以直接看:

图片来源:https://github.com/lonePatient/TorchBlocks/blob/e6c5959e6a3d3380bbb147f1c30f752cd8482c1a/examples/task_text_classification_freelb_cola.py#L43
55行的就是一个字典,更多详细情况看代码就知道是怎么回事了。
(2)dropout=0的问题

图片来源见参考资料。
关于dropout要不要为0,笔者建议都试一试,取其好。
Virtual Adversarial Training
这是一种基于对抗学习的半监督训练方式,如果你的标签数据较少,且还有很多未标签数据,可以试一试该方法对结果有没有效果,具体原理见参考资料
待更新
效果
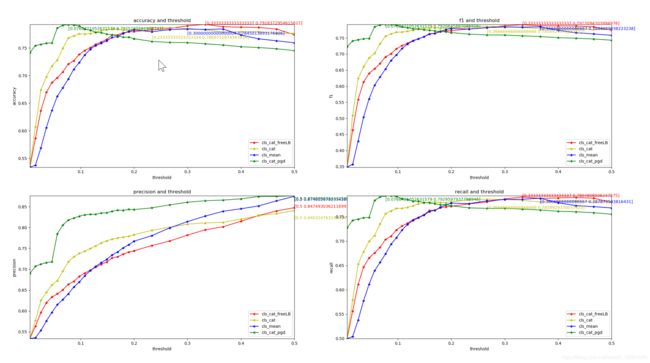
总体上对抗学习还是能带来一些收益的
温馨小提示:这里的cls_cat是cls和token pooling的concat,cls_mean是两者的mean ,效果要比单一用cls或者token pooling的结果都好。
参考资料
FGSM,PGD.FreeLB代码:TorchBlocks/adversarial.py at e6c5959e6a3d3380bbb147f1c30f752cd8482c1a · lonePatient/TorchBlocks · GitHub
NLP中的对抗训练 + PyTorch实现:【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现 - 知乎
对抗训练的理解,以及FGM、PGD和FreeLB的详细介绍:对抗训练的理解,以及FGM、PGD和FreeLB的详细介绍_甘如荠-CSDN博客_fgm对抗训练
Virtual Adversarial Training解读:Virtual Adversarial Training解读_qq_33221657的博客-CSDN博客
Virtual Adversarial Training loss参考代码:Virtual Adversarial Training的pytorch实现_机器学习 数据挖掘 搜索引擎 推荐系统-CSDN博客
Virtual Adversarial Training整个实现参考代码:ssl_text_classification/training.py at 1b92c8df59230f259a7b8a6d50b830d17e081362 · DevSinghSachan/ssl_text_classification · GitHub
笔者微信公众号,定期分享一些trick:
