【python】分类模型测试结果的可视化
一、前言
不定期的用python复现一些在论文里看到的感觉还不错的图,平时开组会可以用到,自己写论文也可参考一下。
二、分类模型的概率分布图
1. 背景
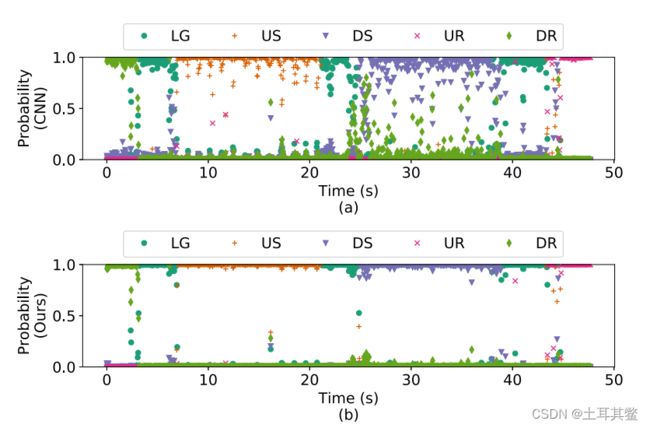
上图出自论文《Sequential Decision Fusion for Environmental Classification in Assistive Walking》。在这两幅图中,横坐标代表时间轴,纵坐标是概率值,每一个最小时间刻度对应5个概率值,这5个概率值是模型输出的,加起来等于1,也就是说当某一个类别的概率值越大时,其他类别的概率就会越低,就会呈现两级分化的现象,这是我们想要达到的模型训练结果(如图b)。相反,当每个类的发生概率都不大时,就会呈现出图a的现象,这说明模型的分类更有可能会出错。
2. 代码实现
首先使用训练好模型对测试数据进行预测,这里我继续使用上篇文章中使用的ActivTracker的数据和模型。
import numpy as np
import matplotlib.pyplot as plt
from keras.models import load_model
#####################################加载数据和模型######################################
test_x = np.load(r'...\testData.npy')
groundTruth = np.load(r'...\groundTruth.npy')
model = load_model(r'...\model.h5')
#####################################对数据进行分类预测##################################
predictions = model.predict(test_x, verbose=2)
print(predictions.shape)
print(predictions)
print查看一下,一共有6130个输出,每个输出有6个概率值,分别对应6个类别的发生概率,我们把这些概率值提取出来再plot一下就ok了

完整代码如下:
import numpy as np
import matplotlib.pyplot as plt
from keras.models import load_model
test_x = np.load(r'...\testData.npy')
groundTruth = np.load(r'...\groundTruth.npy')
model = load_model(r'...\model.h5')
predictions = model.predict(test_x, verbose=2)
# print(predictions.shape)
# print(predictions)
plt.figure(figsize=(12,3))
#####################数据有点多,我只用到了前面1000个输出#################
downstairs = predictions[:1000,0]
jogging = predictions[:1000,1]
sitting = predictions[:1000,2]
standing = predictions[:1000,3]
upstairs = predictions[:1000,4]
walking = predictions[:1000,5]
#####################使用marker并取消线条##########################
mark = 4
plt.plot(downstairs, marker = 'o', linestyle = '', markersize=mark)
plt.plot(jogging, marker = 'x', linestyle = '', markersize=mark)
plt.plot(sitting, marker = 's', linestyle = '', markersize=mark)
plt.plot(standing, marker = 'd', linestyle = '', markersize=mark)
plt.plot(upstairs, marker = '*', linestyle = '', markersize=mark)
plt.plot(walking, marker = 'p', linestyle = '', markersize=mark)
##############把x轴的单位换一下,这里传感器的频率时20Hz,所以200个数据等于10s################
plt.xticks([0,200,400,600,800,1000],['0','10','20','30','40','50'])
plt.xlabel('Time (s)')
plt.ylabel('Probability')
plt.legend(['downstairs','jogging','sitting','standing','upstairs','walking'],bbox_to_anchor=(0.9,1.2),ncol=6)
plt.savefig(r'...\probability.svg', format='svg',dpi = 600, transparent=True,bbox_inches = 'tight')
plt.show()
结果如下图所示,一眼望上去,感觉就jogging和walking两种模式的识别效果不错?

3. 总结
如果是不同算法对比的话,感觉用这个概率分布图比混淆矩阵看上去更直观一点,参考上面引用的论文图片。